TiDB Scheduling
The Placement Driver (PD) works as the manager in a TiDB cluster, and it also schedules Regions in the cluster. This article introduces the design and core concepts of the PD scheduling component.
Scheduling situations
TiKV is the distributed key-value storage engine used by TiDB. In TiKV, data is organized as Regions, which are replicated on several stores. In all replicas, a leader is responsible for reading and writing, and followers are responsible for replicating Raft logs from the leader.
Now consider about the following situations:
- To utilize storage space in a high-efficient way, multiple Replicas of the same Region need to be properly distributed on different nodes according to the Region size;
- For multiple data center topologies, one data center failure only causes one replica to fail for all Regions;
- When a new TiKV store is added, data can be rebalanced to it;
- When a TiKV store fails, PD needs to consider:
- Recovery time of the failed store.
- If it's short (for example, the service is restarted), whether scheduling is necessary or not.
- If it's long (for example, disk fault, data is lost, etc.), how to do scheduling.
- Replicas of all Regions.
- If the number of replicas is not enough for some Regions, PD needs to complete them.
- If the number of replicas is more than expected (for example, the failed store re-joins into the cluster after recovery), PD needs to delete them.
- Recovery time of the failed store.
- Read/Write operations are performed on leaders, which can not be distributed only on a few individual stores;
- Not all Regions are hot, so loads of all TiKV stores need to be balanced;
- When Regions are in balancing, data transferring utilizes much network/disk traffic and CPU time, which can influence online services.
These situations can occur at the same time, which makes it harder to resolve. Also, the whole system is changing dynamically, so a scheduler is needed to collect all information about the cluster, and then adjust the cluster. So, PD is introduced into the TiDB cluster.
Scheduling requirements
The above situations can be classified into two types:
A distributed and highly available storage system must meet the following requirements:
- The right number of replicas.
- Replicas need to be distributed on different machines according to different topologies.
- The cluster can perform automatic disaster recovery from TiKV peers' failure.
A good distributed system needs to have the following optimizations:
- All Region leaders are distributed evenly on stores;
- Storage capacity of all TiKV peers are balanced;
- Hot spots are balanced;
- Speed of load balancing for the Regions needs to be limited to ensure that online services are stable;
- Maintainers are able to take peers online/offline manually.
After the first type of requirements is satisfied, the system will be failure tolerable. After the second type of requirements is satisfied, resources will be utilized more efficiently and the system will have better scalability.
To achieve the goals, PD needs to collect information firstly, such as state of peers, information about Raft groups and the statistics of accessing the peers. Then we need to specify some strategies for PD, so that PD can make scheduling plans from these information and strategies. Finally, PD distributes some operators to TiKV peers to complete scheduling plans.
Basic scheduling operators
All scheduling plans contain three basic operators:
- Add a new replica
- Remove a replica
- Transfer a Region leader between replicas in a Raft group
They are implemented by the Raft commands AddReplica, RemoveReplica, and TransferLeader.
Information collection
Scheduling is based on information collection. In short, the PD scheduling component needs to know the states of all TiKV peers and all Regions. TiKV peers report the following information to PD:
State information reported by each TiKV peer:
Each TiKV peer sends heartbeats to PD periodically. PD not only checks whether the store is alive, but also collects
StoreStatein the heartbeat message.StoreStateincludes:Total disk space
Available disk space
The number of Regions
Data read/write speed
The number of snapshots that are sent/received (The data might be replicated between replicas through snapshots)
Whether the store is overloaded
Labels (See Perception of Topology)
You can use PD control to check the status of a TiKV store, which can be Up, Disconnect, Offline, Down, or Tombstone. The following is a description of all statuses and their relationship.
Up: The TiKV store is in service.
Disconnect: Heartbeat messages between the PD and the TiKV store are lost for more than 20 seconds. If the lost period exceeds the time specified by
max-store-down-time, the status "Disconnect" changes to "Down".Down: Heartbeat messages between the PD and the TiKV store are lost for a time longer than
max-store-down-time(30 minutes by default). In this status, the TiKV store starts replenishing replicas of each Region on the surviving store.Offline: A TiKV store is manually taken offline through PD Control. This is only an intermediate status for the store to go offline. The store in this status moves all its Regions to other "Up" stores that meet the relocation conditions. When
leader_countandregion_count(obtained through PD Control) both show0, the store status changes to "Tombstone" from "Offline". In the "Offline" status, do not disable the store service or the physical server where the store is located. During the process that the store goes offline, if the cluster does not have target stores to relocate the Regions (for example, inadequate stores to hold replicas in the cluster), the store is always in the "Offline" status.Tombstone: The TiKV store is completely offline. You can use the
remove-tombstoneinterface to safely clean up TiKV in this status.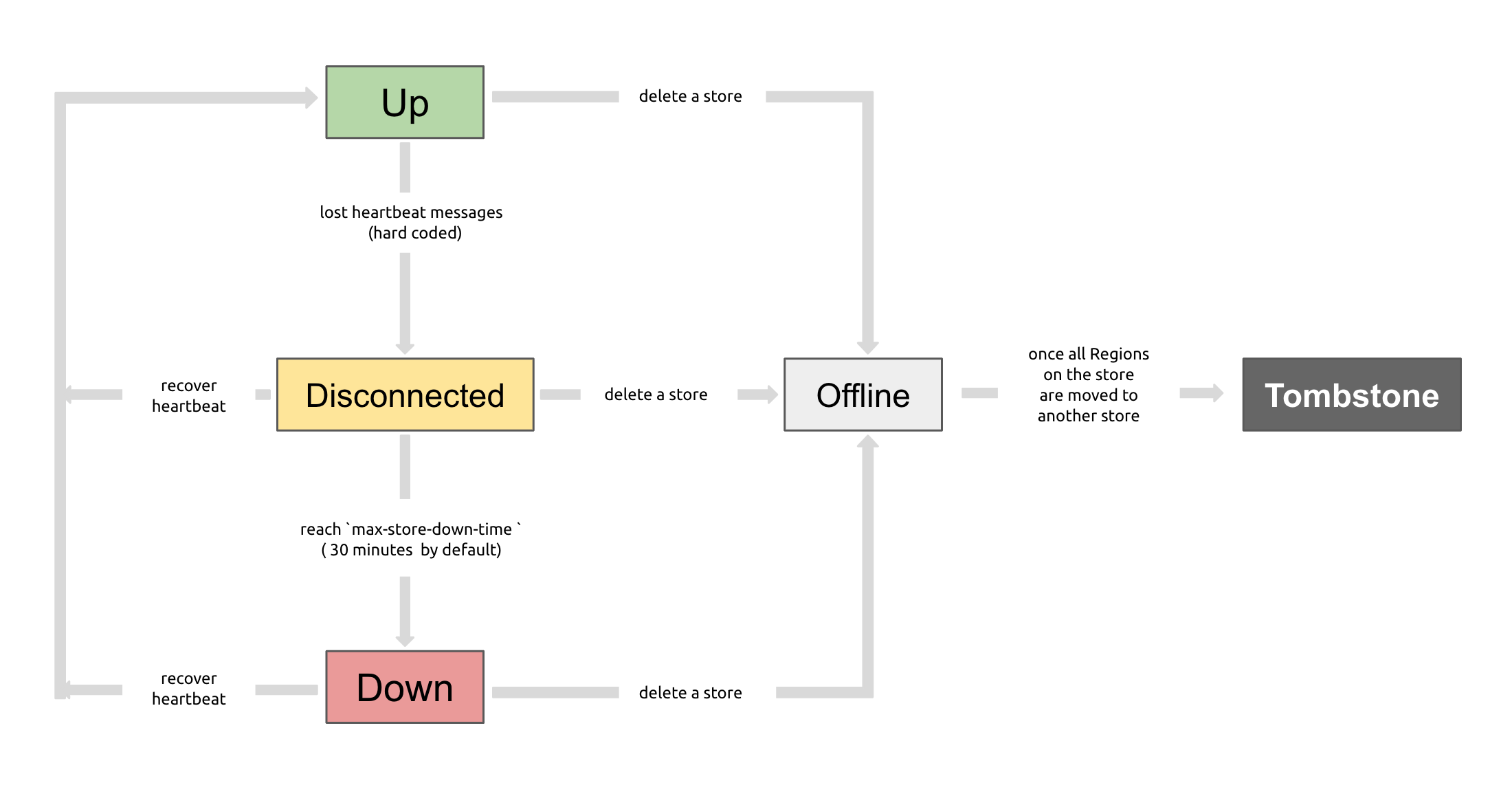
Information reported by Region leaders:
Each Region leader sends heartbeats to PD periodically to report
RegionState, including:- Position of the leader itself
- Positions of other replicas
- The number of offline replicas
- data read/write speed
PD collects cluster information by the two types of heartbeats and then makes decision based on it.
Besides, PD can get more information from an expanded interface to make a more precise decision. For example, if a store's heartbeats are broken, PD can't know whether the peer steps down temporarily or forever. It just waits a while (by default 30min) and then treats the store as offline if there are still no heartbeats received. Then PD balances all regions on the store to other stores.
But sometimes stores are manually set offline by a maintainer, so the maintainer can tell PD this by the PD control interface. Then PD can balance all regions immediately.
Scheduling strategies
After collecting the information, PD needs some strategies to make scheduling plans.
Strategy 1: The number of replicas of a Region needs to be correct
PD can know that the replica count of a Region is incorrect from the Region leader's heartbeat. If it happens, PD can adjust the replica count by adding/removing replica(s). The reason for incorrect replica count can be:
- Store failure, so some Region's replica count is less than expected;
- Store recovery after failure, so some Region's replica count could be more than expected;
max-replicasis changed.
Strategy 2: Replicas of a Region need to be at different positions
Note that here "position" is different from "machine". Generally PD can only ensure that replicas of a Region are not at a same peer to avoid that the peer's failure causes more than one replicas to become lost. However in production, you might have the following requirements:
- Multiple TiKV peers are on one machine;
- TiKV peers are on multiple racks, and the system is expected to be available even if a rack fails;
- TiKV peers are in multiple data centers, and the system is expected to be available even if a data center fails;
The key to these requirements is that peers can have the same "position", which is the smallest unit for failure toleration. Replicas of a Region must not be in one unit. So, we can configure labels for the TiKV peers, and set location-labels on PD to specify which labels are used for marking positions.
Strategy 3: Replicas need to be balanced between stores
The size limit of a Region replica is fixed, so keeping the replicas balanced between stores is helpful for data size balance.
Strategy 4: Leaders need to be balanced between stores
Read and write operations are performed on leaders according to the Raft protocol, so that PD needs to distribute leaders into the whole cluster instead of several peers.
Strategy 5: Hot spots need to be balanced between stores
PD can detect hot spots from store heartbeats and Region heartbeats, so that PD can distribute hot spots.
Strategy 6: Storage size needs to be balanced between stores
When started up, a TiKV store reports capacity of storage, which indicates the store's space limit. PD will consider this when scheduling.
Strategy 7: Adjust scheduling speed to stabilize online services
Scheduling utilizes CPU, memory, network and I/O traffic. Too much resource utilization will influence online services. Therefore, PD needs to limit the number of the concurrent scheduling tasks. By default this strategy is conservative, while it can be changed if quicker scheduling is required.
Scheduling implementation
PD collects cluster information from store heartbeats and Region heartbeats, and then makes scheduling plans from the information and strategies. Scheduling plans are a sequence of basic operators. Every time PD receives a Region heartbeat from a Region leader, it checks whether there is a pending operator on the Region or not. If PD needs to dispatch a new operator to a Region, it puts the operator into heartbeat responses, and monitors the operator by checking follow-up Region heartbeats.
Note that here "operators" are only suggestions to the Region leader, which can be skipped by Regions. Leader of Regions can decide whether to skip a scheduling operator or not based on its current status.