Introduction to Join Reorder
In real application scenarios, it is common to join multiple tables. The execution efficiency of join is associated with the order in which each table joins.
For example:
SELECT * FROM t1, t2, t3 WHERE t1.a=t2.a AND t3.a=t2.a;
In this query, tables can be joined in the following two orders:
- t1 joins t2, and then joins t3
- t2 joins t3, and then joins t1
As t1 and t3 have different data volumes and distribution, these two execution orders might show different performances.
Therefore, the optimizer needs an algorithm to determine the join order. Currently, TiDB uses the Join Reorder algorithm, also known as the greedy algorithm.
Instance of Join Reorder algorithm
Take the three tables above (t1, t2, and t3) as an example.
First, TiDB obtains all the nodes that participates in the join operation, and sorts the nodes in the ascending order of row numbers.

After that, the table with the least rows is selected and joined with other two tables respectively. By comparing the sizes of the output result sets, TiDB selects the pair with a smaller result set.
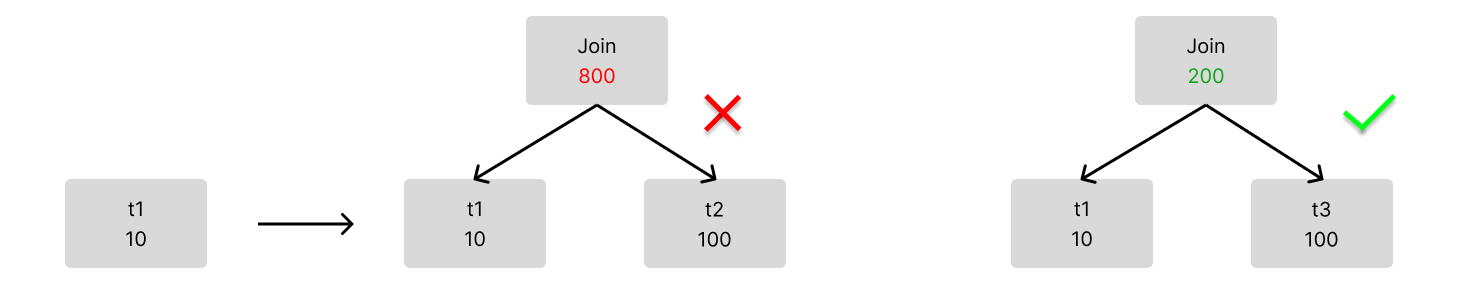
Then TiDB enters the next round of selection. If you try to join four tables, TiDB continues to compare the sizes of the output result sets and selects the pair with a smaller result set.
In this case only three tables are joined, so TiDB gets the final join result.
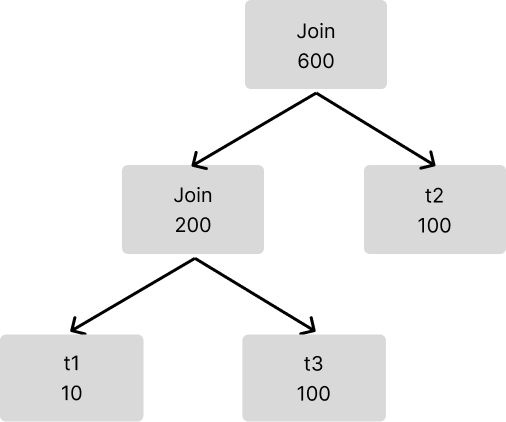
The above process is the Join Reorder algorithm currently used in TiDB.
Limitations of Join Reorder algorithm
The current Join Reorder algorithm has the following limitations:
- The Join Reorder for Outer Join is not supported
- Limited by the calculation methods of the result sets, the algorithm cannot ensure it selects the optimum join order.
Currently, the STRAIGHT_JOIN syntax is supported in TiDB to force a join order. For more information, refer to Description of the syntax elements.