BR Tool Overview
BR (Backup & Restore) is a command-line tool for distributed backup and restoration of the TiDB cluster data.
Compared with Dumpling, BR is more suitable to scenarios involving huge data volumes.
This document describes BR's implementation principles, recommended deployment configuration, usage restrictions and several methods to use BR.
Implementation principles
BR sends the backup or restoration commands to each TiKV node. After receiving these commands, TiKV performs the corresponding backup or restoration operations.
Each TiKV node has a path in which the backup files generated in the backup operation are stored and from which the stored backup files are read during the restoration.
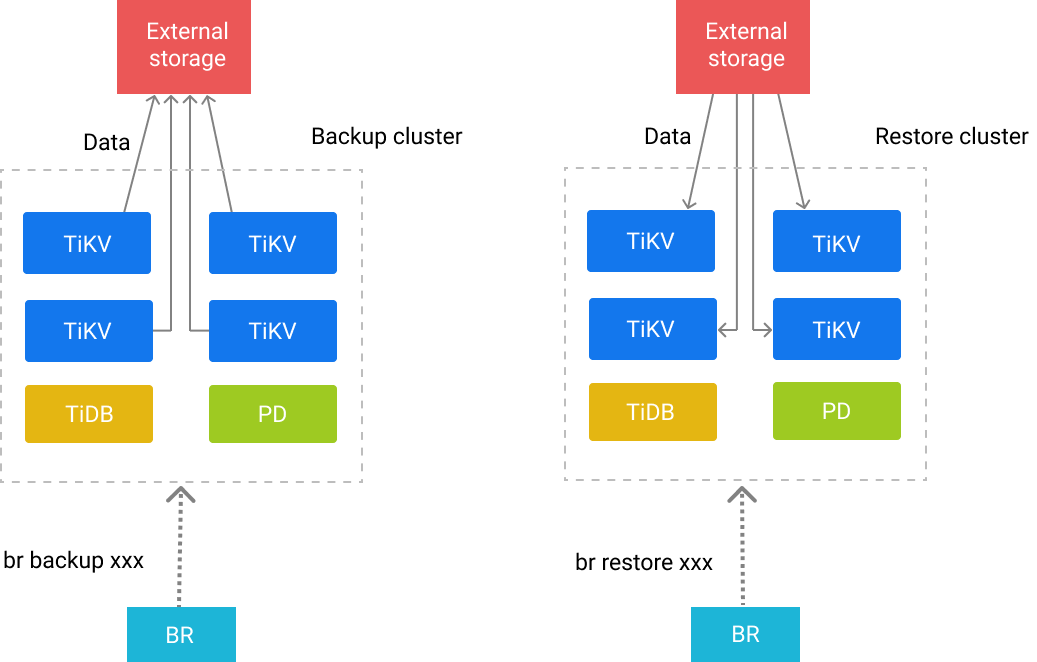
Backup principle
When BR performs a backup operation, it first obtains the following information from PD:
- The current TS (timestamp) as the time of the backup snapshot
- The TiKV node information of the current cluster
According to these information, BR starts a TiDB instance internally to obtain the database or table information corresponding to the TS, and filters out the system databases (information_schema, performance_schema, mysql) at the same time.
According to the backup sub-command, BR adopts the following two types of backup logic:
- Full backup: BR traverses all the tables and constructs the KV range to be backed up according to each table.
- Single table backup: BR constructs the KV range to be backed up according a single table.
Finally, BR collects the KV range to be backed up and sends the complete backup request to the TiKV node of the cluster.
The structure of the request:
BackupRequest{
ClusterId, // The cluster ID.
StartKey, // The starting key of the backup (backed up).
EndKey, // The ending key of the backup (not backed up).
StartVersion, // The version of the last backup snapshot, used for the incremental backup.
EndVersion, // The backup snapshot time.
StorageBackend, // The path where backup files are stored.
RateLimit, // Backup speed (MB/s).
}
After receiving the backup request, the TiKV node traverses all Region leaders on the node to find the Regions that overlap with the KV ranges in this request. The TiKV node backs up some or all of the data within the range, and generates the corresponding SST file.
After finishing backing up the data of the corresponding Region, the TiKV node returns the metadata to BR. BR collects the metadata and stores it in the backupmeta file which is used for restoration.
If StartVersion is not 0, the backup is seen as an incremental backup. In addition to KVs, BR also collects DDLs between [StartVersion, EndVersion). During data restoration, these DDLs are restored first.
If checksum is enabled when you execute the backup command, BR calculates the checksum of each backed up table for data check.
Types of backup files
Two types of backup files are generated in the path where backup files are stored:
- The SST file: stores the data that the TiKV node backed up.
- The
backupmetafile: stores the metadata of this backup operation, including the number, the key range, the size, and the Hash (sha256) value of the backup files. - The
backup.lockfile: prevents multiple backup operations from storing data to the same directory.
The format of the SST file name
The SST file is named in the format of storeID_regionID_regionEpoch_keyHash_cf, where
storeIDis the TiKV node ID;regionIDis the Region ID;regionEpochis the version number of the Region;keyHashis the Hash (sha256) value of the startKey of a range, which ensures the uniqueness of a key;cfindicates the Column Family of RocksDB (defaultorwriteby default).
Restoration principle
During the data restoration process, BR performs the following tasks in order:
It parses the
backupmetafile in the backup path, and then starts a TiDB instance internally to create the corresponding databases and tables based on the parsed information.It aggregates the parsed SST files according to the tables.
It pre-splits Regions according to the key range of the SST file so that every Region corresponds to at least one SST file.
It traverses each table to be restored and the SST file corresponding to each tables.
It finds the Region corresponding to the SST file and sends a request to the corresponding TiKV node for downloading the file. Then it sends a request for loading the file after the file is successfully downloaded.
After TiKV receives the request to load the SST file, TiKV uses the Raft mechanism to ensure the strong consistency of the SST data. After the downloaded SST file is loaded successfully, the file is deleted asynchronously.
After the restoration operation is completed, BR performs a checksum calculation on the restored data to compare the stored data with the backed up data.
Deploy and use BR
Recommended deployment configuration
- It is recommended that you deploy BR on the PD node.
- It is recommended that you mount a high-performance SSD to BR nodes and all TiKV nodes. A 10-gigabit network card is recommended. Otherwise, bandwidth is likely to be the performance bottleneck during the backup and restore process.
Usage restrictions
The following are the limitations of using BR for backup and restoration:
- When BR restores data to the upstream cluster of TiCDC/Drainer, TiCDC/Drainer cannot replicate the restored data to the downstream.
- BR supports operations only between clusters with the same
new_collations_enabled_on_first_bootstrapvalue because BR only backs up KV data. If the cluster to be backed up and the cluster to be restored use different collations, the data validation fails. Therefore, before restoring a cluster, make sure that the switch value from the query result of theselect VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME='new_collation_enabled';statement is consistent with that during the backup process.
Compatibility
The compatibility issues of BR and the TiDB cluster are divided into the following categories:
- Some versions of BR are not compatible with the interface of the TiDB cluster.
- The KV format might change when some features are enabled or disabled. If these features are not consistently enabled or disabled during backup and restore, compatibility issues might occur.
These features are as follows:
| Features | Related issues | Solutions |
|---|---|---|
| Clustered index | #565 | Make sure that the value of the tidb_enable_clustered_index global variable during restore is consistent with that during backup. Otherwise, data inconsistency might occur, such as default not found and inconsistent data index. |
| New collation | #352 | Make sure that the value of the new_collations_enabled_on_first_bootstrap variable is consistent with that during backup. Otherwise, inconsistent data index might occur and checksum might fail to pass. |
| TiCDC enabled on the restore cluster | #364 | Currently, TiKV cannot push down the BR-ingested SST files to TiCDC. Therefore, you need to disable TiCDC when using BR to restore data. |
However, even after you have ensured that the above features are consistently enabled or disabled during backup and restore, compatibility issues might still occur due to the inconsistent internal versions or inconsistent interfaces between BR and TiKV/TiDB/PD. To avoid such cases, BR has the built-in version check.
Version check
Before performing backup and restore, BR compares and checks the TiDB cluster version and the BR version. If there is a major-version mismatch (for example, BR v4.x and TiDB v5.x), BR prompts a reminder to exit. To forcibly skip the version check, you can set --check-requirements=false.
Note that skipping the version check might introduce incompatibility. The version compatibility information between BR and TiDB versions are as follows:
| Backup version (vertical) \ Restore version (horizontal) | Use BR nightly to restore TiDB nightly | Use BR v5.0 to restore TiDB v5.0 | Use BR v4.0 to restore TiDB v4.0 |
|---|---|---|---|
| Use BR nightly to back up TiDB nightly | ✅ | ✅ | ❌ (If a table with the primary key of the non-integer clustered index type is restored to a TiDB v4.0 cluster, BR will cause data error without warning.) |
| Use BR v5.0 to back up TiDB v5.0 | ✅ | ✅ | ❌ (If a table with the primary key of the non-integer clustered index type is restored to a TiDB v4.0 cluster, BR will cause data error without warning.) |
| Use BR v4.0 to back up TiDB v4.0 | ✅ | ✅ | ✅ (If TiKV >= v4.0.0-rc.1, and if BR contains the #233 bug fix and TiKV does not contain the #7241 bug fix, BR will cause the TiKV node to restart.) |
| Use BR nightly or v5.0 to back up TiDB v4.0 | ❌ (If the TiDB version is earlier than v4.0.9, the #609 issue might occur.) | ❌ (If the TiDB version is earlier than v4.0.9, the #609 issue might occur.) | ❌ (If the TiDB version is earlier than v4.0.9, the #609 issue might occur.) |
Minimum machine configuration required for running BR
The minimum machine configuration required for running BR is as follows:
| CPU | Memory | Hard Disk Type | Network |
|---|---|---|---|
| 1 core | 4 GB | HDD | Gigabit network card |
In general scenarios (less than 1000 tables for backup and restore), the CPU consumption of BR at runtime does not exceed 200%, and the memory consumption does not exceed 4 GB. However, when backing up and restoring a large number of tables, BR might consume more than 4 GB of memory. In a test of backing up 24000 tables, BR consumes about 2.7 GB of memory, and the CPU consumption remains below 100%.
Best practices
The following are some recommended operations for using BR for backup and restoration:
- It is recommended that you perform the backup operation during off-peak hours to minimize the impact on applications.
- BR supports restore on clusters of different topologies. However, the online applications will be greatly impacted during the restore operation. It is recommended that you perform restore during the off-peak hours or use
rate-limitto limit the rate. - It is recommended that you execute multiple backup operations serially. Running different backup operations in parallel reduces backup performance and also affects the online application.
- It is recommended that you execute multiple restore operations serially. Running different restore operations in parallel increases Region conflicts and also reduces restore performance.
- It is recommended that you mount a shared storage (for example, NFS) on the backup path specified by
-s, to make it easier to collect and manage backup files. - It is recommended that you use a storage hardware with high throughput, because the throughput of a storage hardware limits the backup and restoration speed.
How to use BR
Currently, the following methods are supported to run the BR tool:
- Use SQL statements
- Use the command-line tool
- Use BR In the Kubernetes environment
Use SQL statements
TiDB supports both BACKUP and RESTORE SQL statements. The progress of these operations can be monitored with the statement SHOW BACKUPS|RESTORES.
Use the command-line tool
The br command-line utility is available as a separate download. For details, see Use BR Command-line for Backup and Restoration.
In the Kubernetes environment
In the Kubernetes environment, you can use the BR tool to back up TiDB cluster data to S3-compatible storage, Google Cloud Storage (GCS) and persistent volumes (PV), and restore them:
- Back up Data to S3-Compatible Storage Using BR
- Restore Data from S3-Compatible Storage Using BR
- Back up Data to GCS Using BR
- Restore Data from GCS Using BR
- Back up Data to PV Using BR
- Restore Data from PV Using BR