Data Check in the Sharding Scenario
sync-diff-inspector supports data check in the sharding scenario. Assume that you use the DM replication tool to replicate data from multiple MySQL instances into TiDB, and now you can use sync-diff-inspector to check upstream and downstream data.
Use table-config for configuration
You can use table-config to configure table-0, set is-sharding=true and configure the upstream table information in table-config.source-tables. This configuration method requires setting all sharded tables, which is suitable for scenarios where the number of upstream sharded tables is small and the naming rules of sharded tables do not have a pattern as shown below.
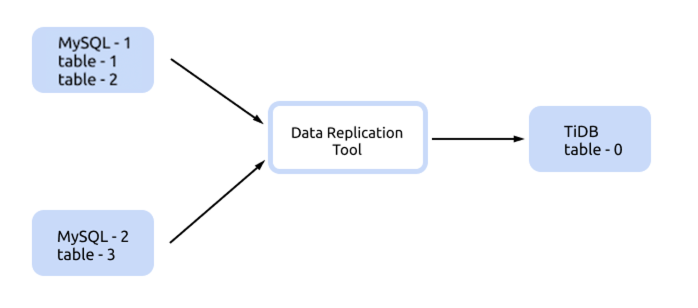
Below is a complete example of the sync-diff-inspector configuration.
# Diff Configuration.
######################### Global config #########################
# The log level. You can set it to "info" or "debug".
log-level = "info"
# sync-diff-inspector divides the data into multiple chunks based on the primary key,
# unique key, or the index, and then compares the data of each chunk.
# Compares data in each chunk. Uses "chunk-size" to set the size of a chunk.
chunk-size = 1000
# The number of goroutines created to check data
check-thread-count = 4
# The proportion of sampling check. If you set it to 100, all the data is checked.
sample-percent = 100
# If enabled, the chunk's checksum is calculated and data is compared by checksum.
# If disabled, data is compared line by line.
use-checksum = true
# If it is set to true, data is checked only by calculating checksum. Data is not checked after inspection, even if the upstream and downstream checksums are inconsistent.
only-use-checksum = false
# Whether to use the checkpoint of the last check. If it is enabled, the inspector only checks the last unchecked chunks and chunks that failed the verification.
use-checkpoint = true
# If it is set to true, data check is ignored.
# If it is set to false, data is checked.
ignore-data-check = false
# If it is set to true, the table struct comparison is ignored.
# If set to false, the table struct is compared.
ignore-struct-check = false
# The name of the file which saves the SQL statements used to repair data
fix-sql-file = "fix.sql"
######################### Tables config #########################
# Configures the tables of the target database that need to be checked
[[check-tables]]
# The name of the schema in the target database
schema = "test"
# The name of tables that need to be checked in the target database
tables = ["table-0"]
# Configures the sharded tables corresponding to this table
[[table-config]]
# The name of the target schema
schema = "test"
# The name of the table in the target schema
table = "table-0"
# Sets it to "true" in the sharding scenario
is-sharding = true
# Configuration of the source tables
[[table-config.source-tables]]
# The instance ID of the source database
instance-id = "MySQL-1"
schema = "test"
table = "table-1"
[[table-config.source-tables]]
# The instance ID of the source database
instance-id = "MySQL-1"
schema = "test"
table = "test-2"
[[table-config.source-tables]]
# The instance ID of the source database
instance-id = "MySQL-2"
schema = "test"
table = "table-3"
######################### Databases config #########################
# Configuration of the source database instance
[[source-db]]
host = "127.0.0.1"
port = 3306
user = "root"
password = "123456"
instance-id = "MySQL-1"
# Configuration of the source database instance
[[source-db]]
host = "127.0.0.2"
port = 3306
user = "root"
password = "123456"
instance-id = "MySQL-2"
# Configuration of the target database instance
[target-db]
host = "127.0.0.3"
port = 4000
user = "root"
password = "123456"
instance-id = "target-1"
Use table-rules for configuration
You can use table-rules for configuration when there are a large number of upstream sharded tables and the naming rules of all sharded tables have a pattern, as shown below:
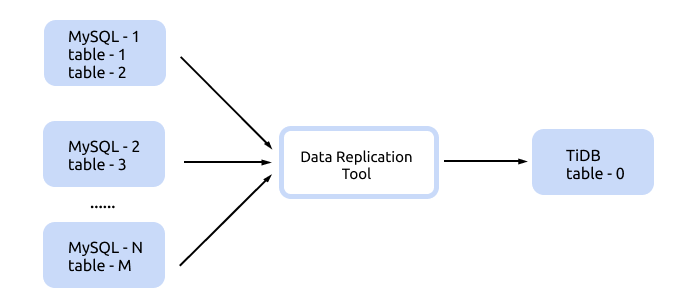
Below is a complete example of the sync-diff-inspector configuration.
# Diff Configuration.
######################### Global config #########################
# The log level. You can set it to "info" or "debug".
log-level = "info"
# sync-diff-inspector divides the data into multiple chunks based on the primary key,
# unique key, or the index, and then compares the data of each chunk.
# Uses "chunk-size" to set the size of a chunk.
chunk-size = 1000
# The number of goroutines created to check data
check-thread-count = 4
# The proportion of sampling check. If you set it to 100, all the data is checked.
sample-percent = 100
# If enabled, the chunk's checksum is calculated and data is compared by checksum.
# If disabled, data is compared line by line.
use-checksum = true
# If it is set to true, data is checked only by calculating checksum. Data is not checked after inspection, even if the upstream and downstream checksums are inconsistent.
only-use-checksum = false
# Whether to use the checkpoint of the last check. If it is enabled, the inspector only checks the last unchecked chunks and chunks that failed the verification.
use-checkpoint = true
# If it is set to true, data check is ignored.
# If it is set to false, data is checked.
ignore-data-check = false
# If it is set to true, the table struct comparison is ignored.
# If set to false, the table struct is compared.
ignore-struct-check = false
# The name of the file which saves the SQL statements used to repair data
fix-sql-file = "fix.sql"
######################### Tables config #########################
# Configures the tables of the target database that need to be checked
[[check-tables]]
# The name of the schema in the target database
schema = "test"
# The name of tables that need to be checked in the target database
tables = ["table-0"]
# Use `table-rule` to set the mapping relationship between the upstream sharded tables and the downstream table family. You can configure the mapping rule only for the schema or table, or the mapping rules for both the schema and table.
[[table-rules]]
# schema-pattern and table-pattern support wildcard *?
# All tables that meet the schema-pattern and table-pattern rules in the upstream database configured in source-db are the sharded tables of target-schema.target-table.
schema-pattern = "test"
table-pattern = "table-*"
target-schema = "test"
target-table = "table-0"
######################### Databases config #########################
# Configuration of the source database instance
[[source-db]]
host = "127.0.0.1"
port = 3306
user = "root"
password = "123456"
instance-id = "MySQL-1"
# Configuration of the source database instance
[[source-db]]
host = "127.0.0.2"
port = 3306
user = "root"
password = "123456"
instance-id = "MySQL-2"
# Configuration of the target database instance
[target-db]
host = "127.0.0.3"
port = 4000
user = "root"
password = "123456"
instance-id = "target-1"