Bidirectional Replication between TiDB Clusters
This document describes the bidirectional replication between two TiDB clusters, how the replication works, how to enable it, and how to replicate DDL operations.
User scenario
If you want two TiDB clusters to exchange data changes with each other, TiDB Binlog allows you to do that. For example, you want cluster A and cluster B to replicate data with each other.
The user scenario is shown as below:
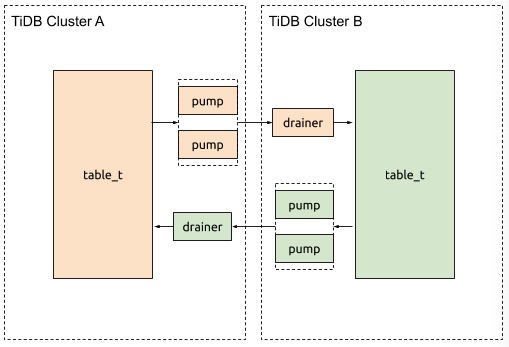
Implementation details
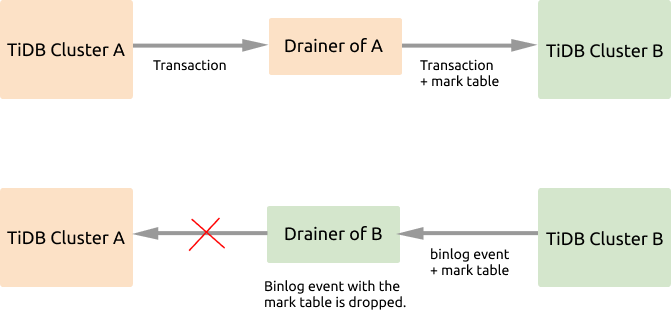
If the bidirectional replication is enabled between cluster A and cluster B, the data written to cluster A will be replicated to cluster B, and then these data changes will be replicated back to cluster A, which causes an infinite loop of replication. From the figure above, you can see that during the data replication, Drainer marks the binlog events, and filters out the marked events to avoid such a replication loop.
The detailed implementation is described as follows:
- Start the TiDB Binlog replication program for each of the two clusters.
- When the transaction to be replicated passes through the Drainer of cluster A, this Drainer adds the
_drainer_repl_marktable to the transaction, writes this DML event update to the mark table, and replicate this transaction to cluster B. - Cluster B returns binlog events with the
_drainer_repl_markmark table to cluster A. The Drainer of cluster B identifies the mark table with the DML event when parsing the binlog event, and gives up replicating this binlog event to cluster A.
The replication process from cluster B to cluster A is the same as above. The two clusters can be upstream and downstream of each other.
Drainer can use a unique ID for each connection to downstream to avoid conflicts. channel_id is used to indicate a channel for bidirectional replication. The two clusters should have the same channel_id configuration (with the same value).
If you add or delete columns in the upstream, there might be extra or missing columns of the data to be replicated to the downstream. Drainer allows this situation by ignoring the extra columns or by inserting default values to the missing columns.
Mark table
The _drainer_repl_mark mark table has the following structure:
CREATE TABLE `_drainer_repl_mark` (
`id` bigint(20) NOT NULL,
`channel_id` bigint(20) NOT NULL DEFAULT '0',
`val` bigint(20) DEFAULT '0',
`channel_info` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`,`channel_id`)
);
Drainer uses the following SQL statement to update _drainer_repl_mark, which ensures data change and the generation of binlog:
update drainer_repl_mark set val = val + 1 where id = ? && channel_id = ?;
Replicate DDL operations
Because Drainer cannot add the mark table to DDL operations, you can only use the one-way replication method to replicate DDL operations.
For example, if DDL replication is enabled from cluster A to cluster B, then the replication is disabled from cluster B to cluster A. This means that all DDL operations are performed on cluster A.
Configure and enable bidirectional replication
For bidirectional replication between cluster A and cluster B, assume that all DDL operations are executed on cluster A. On the replication path from cluster A to cluster B, add the following configuration to Drainer:
[syncer]
loopback-control = true
channel-id = 1 # Configures the same ID for both clusters to be replicated.
sync-ddl = true # Enables it if you need to perform DDL replication.
[syncer.to]
# 1 means SyncFullColumn and 2 means SyncPartialColumn.
# If set to SyncPartialColumn, Drainer allows the downstream table
# structure to have more or fewer columns than the data to be replicated
# And remove the STRICT_TRANS_TABLES of the SQL mode to allow fewer columns, and insert zero values to the downstream.
sync-mode = 2
# Ignores the checkpoint table.
[[syncer.ignore-table]]
db-name = "tidb_binlog"
tbl-name = "checkpoint"
On the replication path from cluster B to cluster A, add the following configuration to Drainer:
[syncer]
loopback-control = true
channel-id = 1 # Configures the same ID for both clusters to be replicated.
sync-ddl = false # Disables it if you do not need to perform DDL replication.
[syncer.to]
# 1 means SyncFullColumn and 2 means SyncPartialColumn.
# If set to SyncPartialColumn, Drainer allows the downstream table
# structure to have more or fewer columns than the data to be replicated
# And remove the STRICT_TRANS_TABLES of the SQL mode to allow fewer columns, and insert zero values to the downstream.
sync-mode = 2
# Ignores the checkpoint table.
[[syncer.ignore-table]]
db-name = "tidb_binlog"
tbl-name = "checkpoint"