TiSpark User Guide
TiSpark vs TiFlash
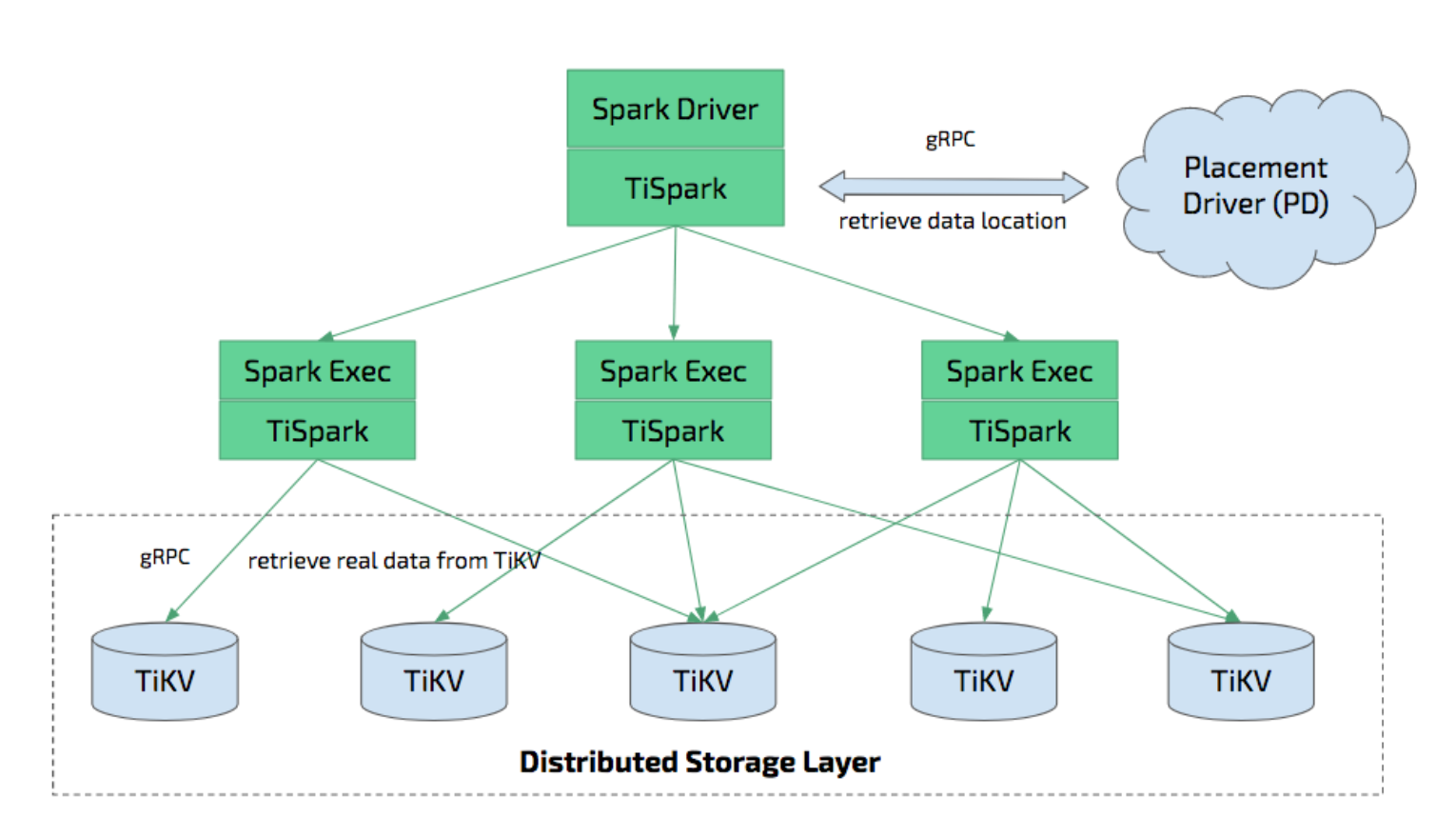
TiSpark is a thin layer built for running Apache Spark on top of TiDB/TiKV to answer the complex OLAP queries. It takes advantages of both the Spark platform and the distributed TiKV cluster and seamlessly glues to TiDB, the distributed OLTP database, to provide a Hybrid Transactional/Analytical Processing (HTAP) solution to serve as a one-stop solution for both online transactions and analysis.
TiFlash is another tool that enables HTAP. Both TiFlash and TiSpark allow the use of multiple hosts to execute OLAP queries on OLTP data. TiFlash stores data in a columnar format, which allows more efficient analytical queries. TiFlash and TiSpark can be used together.
What is TiSpark
TiSpark depends on the TiKV cluster and the PD cluster. You also need to set up a Spark cluster. This document provides a brief introduction to how to setup and use TiSpark. It requires some basic knowledge of Apache Spark. For more information, see Apache Spark website.
Deeply integrating with Spark Catalyst Engine, TiSpark provides precise control on computing. This allows Spark to read data from TiKV efficiently. TiSpark also supports index seek, which enables high-speed point query. TiSpark accelerates data queries by pushing computing to TiKV so as to reduce the volume of data to be processed by Spark SQL. Meanwhile, TiSpark can use TiDB built-in statistics to select the best query plan.
With TiSpark and TiDB, you can run both transaction and analysis tasks on the same platform without building and maintaining ETLs. This simplifies the system architecture and reduces the cost of maintenance.
You can use tools of the Spark ecosystem for data processing on TiDB:
- TiSpark: Data analysis and ETLs
- TiKV: Data retrieval
- Scheduling system: Report generation
Also, TiSpark supports distributed writes to TiKV. Compared with writes to TiDB by using Spark and JDBC, distributed writes to TiKV can implement transactions (either all data are written successfully or all writes fail), and the writes are faster.
Requirements
- TiSpark supports Spark >= 2.3.
- TiSpark requires JDK 1.8 and Scala 2.11/2.12.
- TiSpark runs in any Spark mode such as
YARN,Mesos, andStandalone.
Recommended deployment configurations of Spark
Since TiSpark is a TiDB connector of Spark, to use it, a running Spark cluster is required.
This document provides basic advice on deploying Spark. Please turn to the Spark official website for detailed hardware recommendations.
For independent deployment of Spark cluster:
- It is recommended to allocate 32 GB memory for Spark. Reserve at least 25% of the memory for the operating system and the buffer cache.
- It is recommended to provision at least 8 to 16 cores per machine for Spark. First, you must assign all the CPU cores to Spark.
The following is an example based on the spark-env.sh configuration:
SPARK_EXECUTOR_MEMORY = 32g
SPARK_WORKER_MEMORY = 32g
SPARK_WORKER_CORES = 8
Get TiSpark
TiSpark is a third-party jar package for Spark that provides the ability to read and write TiKV.
Get mysql-connector-j
The mysql-connector-java dependency is no longer provided because of the limit of the GPL license.
The following versions of TiSpark's jar will no longer include mysql-connector-java.
- TiSpark > 3.0.1
- TiSpark > 2.5.1 for TiSpark 2.5.x
- TiSpark > 2.4.3 for TiSpark 2.4.x
However, TiSpark needs mysql-connector-java for writing and authentication. In such cases, you need to import mysql-connector-java manually using either of the following methods:
Put
mysql-connector-javainto spark jars file.Import
mysql-connector-javawhen you submit a spark job. See the following example:
spark-submit --jars tispark-assembly-3.0_2.12-3.1.0-SNAPSHOT.jar,mysql-connector-java-8.0.29.jar
Choose TiSpark version
You can choose TiSpark version according to your TiDB and Spark version.
| TiSpark version | TiDB, TiKV, PD version | Spark version | Scala version |
|---|---|---|---|
| 2.4.x-scala_2.11 | 5.x, 4.x | 2.3.x, 2.4.x | 2.11 |
| 2.4.x-scala_2.12 | 5.x, 4.x | 2.4.x | 2.12 |
| 2.5.x | 5.x, 4.x | 3.0.x, 3.1.x | 2.12 |
| 3.0.x | 5.x, 4.x | 3.0.x, 3.1.x, 3.2.x | 2.12 |
| 3.1.x | 6.x, 5.x, 4.x | 3.0.x, 3.1.x, 3.2.x, 3.3.x | 2.12 |
| 3.2.x | 6.x, 5.x, 4.x | 3.0.x, 3.1.x, 3.2.x, 3.3.x | 2.12 |
TiSpark 2.4.4, 2.5.2, 3.0.2, 3.1.1, and 3.2.3 are the latest stable versions and are highly recommended.
Get TiSpark jar
You can get the TiSpark jar using one of the following methods:
- Get from maven central and search for
pingcap - Get from TiSpark releases
- Build from source with the steps below
git clone https://github.com/pingcap/tispark.git
Run the following command under the TiSpark root directory.
// add -Dmaven.test.skip=true to skip the tests
mvn clean install -Dmaven.test.skip=true
// or you can add properties to specify spark version
mvn clean install -Dmaven.test.skip=true -Pspark3.2.1
TiSpark jar's artifact ID
The Artifact ID of TiSpark varies with TiSpark versions.
| TiSpark version | Artifact ID |
|---|---|
| 2.4.x-${scala_version}, 2.5.0 | tispark-assembly |
| 2.5.1 | tispark-assembly-${spark_version} |
| 3.0.x, 3.1.x, 3.2.x | tispark-assembly-${spark_version}-${scala_version} |
Getting started
This document describes how to use TiSpark in spark-shell.
Start spark-shell
To use TiSpark in spark-shell:
Add the following configuration in spark-defaults.conf:
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses ${your_pd_address}
spark.sql.catalog.tidb_catalog org.apache.spark.sql.catalyst.catalog.TiCatalog
spark.sql.catalog.tidb_catalog.pd.addresses ${your_pd_address}
Start spark-shell with the --jars option.
spark-shell --jars tispark-assembly-{version}.jar
Get TiSpark version
You can get TiSpark version information by running the following command in spark-shell:
spark.sql("select ti_version()").collect
Read data using TiSpark
You can use Spark SQL to read data from TiKV.
spark.sql("use tidb_catalog")
spark.sql("select count(*) from ${database}.${table}").show
Write data using TiSpark
You can use the Spark DataSource API to write data to TiKV, for which ACID is guaranteed.
val tidbOptions: Map[String, String] = Map(
"tidb.addr" -> "127.0.0.1",
"tidb.password" -> "",
"tidb.port" -> "4000",
"tidb.user" -> "root"
)
val customerDF = spark.sql("select * from customer limit 100000")
customerDF.write
.format("tidb")
.option("database", "tpch_test")
.option("table", "cust_test_select")
.options(tidbOptions)
.mode("append")
.save()
See Data Source API User Guide for more details.
Starting from TiSpark 3.1, you can write data to TiKV using Spark SQL. For more information, see insert SQL.
Write data using JDBC DataSource
You can also use Spark JDBC to write to TiDB without the use of TiSpark.
This is beyond the scope of TiSpark. This document only provides an example here. For detailed information, see JDBC To Other Databases.
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions
val customer = spark.sql("select * from customer limit 100000")
// you might need to repartition the source to make it balanced across nodes
// and increase concurrency
val df = customer.repartition(32)
df.write
.mode(saveMode = "append")
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// replace the host and port with yours and be sure to use rewrite batch
.option("url", "jdbc:mysql://127.0.0.1:4000/test?rewriteBatchedStatements=true")
.option("useSSL", "false")
// as tested, setting to `150` is a good practice
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 150)
.option("dbtable", s"cust_test_select") // database name and table name here
.option("isolationLevel", "NONE") // set isolationLevel to NONE
.option("user", "root") // TiDB user here
.save()
Set isolationLevel to NONE to avoid large single transactions which might lead to TiDB OOM and also avoid the ISOLATION LEVEL does not support error (TiDB currently only supports REPEATABLE-READ).
Delete data using TiSpark
You can use Spark SQL to delete data from TiKV.
spark.sql("use tidb_catalog")
spark.sql("delete from ${database}.${table} where xxx")
See delete feature for more details.
Work with other data sources
You can use multiple catalogs to read data from different data sources as follows:
// Read from Hive
spark.sql("select * from spark_catalog.default.t").show
// Join Hive tables and TiDB tables
spark.sql("select t1.id,t2.id from spark_catalog.default.t t1 left join tidb_catalog.test.t t2").show
TiSpark configurations
The configurations in the following table can be put together with spark-defaults.conf or passed in the same way as other Spark configuration properties.
| Key | Default value | Description |
|---|---|---|
spark.tispark.pd.addresses | 127.0.0.1:2379 | The addresses of PD clusters, which are split by commas. |
spark.tispark.grpc.framesize | 2147483647 | The maximum frame size of gRPC response in bytes (default to 2G). |
spark.tispark.grpc.timeout_in_sec | 10 | The gRPC timeout time in seconds. |
spark.tispark.plan.allow_agg_pushdown | true | Whether aggregations are allowed to push down to TiKV (in case of busy TiKV nodes). |
spark.tispark.plan.allow_index_read | true | Whether index is enabled in planning (which might cause heavy pressure on TiKV). |
spark.tispark.index.scan_batch_size | 20000 | The number of row keys in a batch for the concurrent index scan. |
spark.tispark.index.scan_concurrency | 5 | The maximum number of threads for index scan that retrieves row keys (shared among tasks inside each JVM). |
spark.tispark.table.scan_concurrency | 512 | The maximum number of threads for table scan (shared among tasks inside each JVM). |
spark.tispark.request.command.priority | Low | The value options are Low, Normal, High. This setting impacts the resources allocated in TiKV. Low is recommended because the OLTP workload is not disturbed. |
spark.tispark.coprocess.codec_format | chblock | Retain the default codec format for coprocessor. Available options are default, chblock and chunk. |
spark.tispark.coprocess.streaming | false | Whether to use streaming for response fetching (experimental). |
spark.tispark.plan.unsupported_pushdown_exprs | A comma-separated list of expressions. In case you have a very old version of TiKV, you might disable the push down of some expressions if they are not supported. | |
spark.tispark.plan.downgrade.index_threshold | 1000000000 | If the range of index scan on one Region exceeds this limit in the original request, downgrade this Region's request to table scan rather than the planned index scan. By default, the downgrade is disabled. |
spark.tispark.show_rowid | false | Whether to show row ID if the ID exists. |
spark.tispark.db_prefix | The string that indicates the extra prefix for all databases in TiDB. This string distinguishes the databases in TiDB from the Hive databases with the same name. | |
spark.tispark.request.isolation.level | SI | Whether to resolve locks for the underlying TiDB clusters. When you use the "RC", you get the latest version of the record smaller than your tso and ignore the locks. When you use "SI", you resolve the locks and get the records depending on whether the resolved lock is committed or aborted. |
spark.tispark.coprocessor.chunk_batch_size | 1024 | Rows fetched from coprocessor. |
spark.tispark.isolation_read_engines | tikv,tiflash | List of readable engines of TiSpark, comma separated. Storage engines not listed will not be read. |
spark.tispark.stale_read | optional | The stale read timestamp(ms). See here for more details. |
spark.tispark.tikv.tls_enable | false | Whether to enable TiSpark TLS. |
spark.tispark.tikv.trust_cert_collection | The trusted certificate for TiKV Client, used for verifying the remote PD's certificate, for example, /home/tispark/config/root.pem The file should contain an X.509 certificate collection. | |
spark.tispark.tikv.key_cert_chain | An X.509 certificate chain file for TiKV Client, for example, /home/tispark/config/client.pem. | |
spark.tispark.tikv.key_file | A PKCS#8 private key file for TiKV Client, for example, /home/tispark/client_pkcs8.key. | |
spark.tispark.tikv.jks_enable | false | Whether to use the JAVA key store instead of the X.509 certificate. |
spark.tispark.tikv.jks_trust_path | A JKS format certificate for TiKV Client, generated by keytool, for example, /home/tispark/config/tikv-truststore. | |
spark.tispark.tikv.jks_trust_password | The password of spark.tispark.tikv.jks_trust_path. | |
spark.tispark.tikv.jks_key_path | A JKS format key for TiKV Client, generated by keytool, for example, /home/tispark/config/tikv-clientstore. | |
spark.tispark.tikv.jks_key_password | The password of spark.tispark.tikv.jks_key_path. | |
spark.tispark.jdbc.tls_enable | false | Whether to enable TLS when using the JDBC connector. |
spark.tispark.jdbc.server_cert_store | The trusted certificate for JDBC. It is a Java keystore (JKS) format certificate generated by keytool, for example, /home/tispark/config/jdbc-truststore. The default value is "", which means TiSpark does not verify the TiDB server. | |
spark.tispark.jdbc.server_cert_password | The password of spark.tispark.jdbc.server_cert_store. | |
spark.tispark.jdbc.client_cert_store | A PKCS#12 certificate for JDBC. It is a JKS format certificate generated by keytool, for example, /home/tispark/config/jdbc-clientstore. Default is "", which means TiDB server doesn't verify TiSpark. | |
spark.tispark.jdbc.client_cert_password | The password of spark.tispark.jdbc.client_cert_store. | |
spark.tispark.tikv.tls_reload_interval | 10s | The interval for checking if there is any reloading certificates. The default value is 10s (10 seconds). |
spark.tispark.tikv.conn_recycle_time | 60s | The interval for cleaning expired connections with TiKV. It takes effect only when certificate reloading is enabled. The default value is 60s (60 seconds). |
spark.tispark.host_mapping | The route map used to configure the mapping between public IP addresses and intranet IP addresses. When the TiDB cluster is running on the intranet, you can map a set of intranet IP addresses to public IP addresses for an outside Spark cluster to access. The format is {Intranet IP1}:{Public IP1};{Intranet IP2}:{Public IP2}, for example, 192.168.0.2:8.8.8.8;192.168.0.3:9.9.9.9. | |
spark.tispark.new_collation_enable | When new collation is enabled on TiDB, this configuration can be set to true. If new collation is not enabled on TiDB, this configuration can be set to false. If this item is not configured, TiSpark configures new collation automatically based on the TiDB version. The configuration rule is as follows: If the TiDB version is greater than or equal to v6.0.0, it is true; otherwise, it is false. | |
spark.tispark.replica_read | leader | The type of the replica to read. Value options are leader, follower, and learner. Multiple types can be specified at the same time and TiSpark selects the type according to the order. |
spark.tispark.replica_read.label | The label of the target TiKV node. The format is label_x=value_x,label_y=value_y, and the items are connected by logical conjunction. |
TLS configurations
TiSpark TLS has two parts: TiKV Client TLS and JDBC connector TLS. To enable TLS in TiSpark, you need to configure both. spark.tispark.tikv.xxx is used for TiKV Client to create a TLS connection with PD and TiKV server. spark.tispark.jdbc.xxx is used for JDBC to connect with TiDB server in TLS connection.
When TiSpark TLS is enabled, you must configure either the X.509 certificate with tikv.trust_cert_collection, tikv.key_cert_chain and tikv.key_file configurations, or the JKS certificate with tikv.jks_enable, tikv.jks_trust_path and tikv.jks_key_path. jdbc.server_cert_store and jdbc.client_cert_store are optional.
TiSpark only supports TLSv1.2 and TLSv1.3.
- The following is an example of opening TLS configuration with the X.509 certificate in TiKV Client.
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.trust_cert_collection /home/tispark/root.pem
spark.tispark.tikv.key_cert_chain /home/tispark/client.pem
spark.tispark.tikv.key_file /home/tispark/client.key
- The following is an example of enabling TLS with JKS configurations in TiKV Client.
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.jks_enable true
spark.tispark.tikv.jks_key_path /home/tispark/config/tikv-truststore
spark.tispark.tikv.jks_key_password tikv_trustore_password
spark.tispark.tikv.jks_trust_path /home/tispark/config/tikv-clientstore
spark.tispark.tikv.jks_trust_password tikv_clientstore_password
When both JKS and X.509 certificates are configured, JKS would have a higher priority. That means TLS builder will use JKS certificate first. Therefore, do not set spark.tispark.tikv.jks_enable=true when you just want to use a common PEM certificate.
- The following is an example of enabling TLS in JDBC connector.
spark.tispark.jdbc.tls_enable true
spark.tispark.jdbc.server_cert_store /home/tispark/jdbc-truststore
spark.tispark.jdbc.server_cert_password jdbc_truststore_password
spark.tispark.jdbc.client_cert_store /home/tispark/jdbc-clientstore
spark.tispark.jdbc.client_cert_password jdbc_clientstore_password
- For details about how to open TiDB TLS, see Enable TLS between TiDB Clients and Servers.
- For details about how to generate a JAVA key store, see Connecting Securely Using SSL.
Log4j configuration
When you start spark-shell or spark-sql and run query, you might see the following warnings:
Failed to get database ****, returning NoSuchObjectException
Failed to get database ****, returning NoSuchObjectException
where **** is the database name.
The warnings are benign and occurs because Spark cannot find **** in its own catalog. You can just ignore these warnings.
To mute them, append the following text to ${SPARK_HOME}/conf/log4j.properties.
# tispark disable "WARN ObjectStore:568 - Failed to get database"
log4j.logger.org.apache.hadoop.hive.metastore.ObjectStore=ERROR
Time zone configuration
Set time zone by using the -Duser.timezone system property (for example, -Duser.timezone=GMT-7), which affects the Timestamp type.
Do not use spark.sql.session.timeZone.
Features
The major features of TiSpark are as follows:
| Feature support | TiSpark 2.4.x | TiSpark 2.5.x | TiSpark 3.0.x | TiSpark 3.1.x |
|---|---|---|---|---|
| SQL select without tidb_catalog | ✔ | ✔ | ||
| SQL select with tidb_catalog | ✔ | ✔ | ✔ | |
| DataFrame append | ✔ | ✔ | ✔ | ✔ |
| DataFrame reads | ✔ | ✔ | ✔ | ✔ |
| SQL show databases | ✔ | ✔ | ✔ | ✔ |
| SQL show tables | ✔ | ✔ | ✔ | ✔ |
| SQL auth | ✔ | ✔ | ✔ | |
| SQL delete | ✔ | ✔ | ||
| SQL insert | ✔ | |||
| TLS | ✔ | ✔ | ||
| DataFrame auth | ✔ |
Support for expression index
TiDB v5.0 supports expression index.
TiSpark currently supports retrieving data from tables with expression index, but the expression index will not be used by the planner of TiSpark.
Work with TiFlash
TiSpark can read data from TiFlash via the configuration spark.tispark.isolation_read_engines.
Support for partitioned tables
Read partitioned tables from TiDB
TiSpark can read the range and hash partitioned tables from TiDB.
Currently, TiSpark does not support a MySQL/TiDB partition table syntax select col_name from table_name partition(partition_name). However, you can still use the where condition to filter the partitions.
TiSpark decides whether to apply partition pruning according to the partition type and the partition expression associated with the table.
TiSpark applies partition pruning on range partitioning only when the partition expression is one of the following:
- column expression
YEAR($argument)where the argument is a column and its type is datetime or string literal that can be parsed as datetime.
If partition pruning is not applicable, TiSpark's reading is equivalent to doing a table scan over all partitions.
Write into partitioned tables
Currently, TiSpark only supports writing data into the range and hash partitioned tables under the following conditions:
- The partition expression is a column expression.
- The partition expression is
YEAR($argument)where the argument is a column and its type is datetime or string literal that can be parsed as datetime.
There are two ways to write into partitioned tables:
- Use datasource API to write into partition table which supports replace and append semantics.
- Use delete statement with Spark SQL.
Security
If you are using TiSpark v2.5.0 or a later version, you can authenticate and authorize TiSpark users by using TiDB.
The authentication and authorization feature is disabled by default. To enable it, add the following configurations to the Spark configuration file spark-defaults.conf.
// Enable authentication and authorization
spark.sql.auth.enable true
// Configure TiDB information
spark.sql.tidb.addr $your_tidb_server_address
spark.sql.tidb.port $your_tidb_server_port
spark.sql.tidb.user $your_tidb_server_user
spark.sql.tidb.password $your_tidb_server_password
For more information, see Authorization and authentication through TiDB server.
Other features
Statistics information
TiSpark uses the statistic information for:
- Determining which index to use in your query plan with the minimum estimated cost.
- Small table broadcasting, which enables efficient broadcast join.
To allow TiSpark to access statistic information, make sure that relevant tables have been analyzed.
See Introduction to Statistics for more details about how to analyze tables.
Since TiSpark 2.0, statistics information is automatically loaded by default.
FAQ
See TiSpark FAQ.