Execution Principles and Best Practices of DDL Statements
This document provides an overview of the execution principles and best practices related to DDL statements in TiDB. The principles include the DDL Owner module and the online DDL change process.
DDL execution principles
TiDB uses an online and asynchronous approach to execute DDL statements. This means that DML statements in other sessions are not blocked while DDL statements are being executed. In other words, you can change the definitions of database objects using online and asynchronous DDL statements while your applications are running.
Types of DDL statements
Based on whether DDL statements block the user application during execution, DDL statements can be divided into the following types:
Offline DDL statements: When the database receives a DDL statement from the user, it first locks the database object to be modified and then changes the metadata. During the DDL execution, the database blocks the user application from modifying data.
Online DDL statements: When a DDL statement is executed in the database, a specific method is used to ensure that the statement does not block the user application. This allows the user to submit modifications during the DDL execution. The method also ensures the correctness and consistency of the corresponding database object during the execution process.
Based on whether to operate the data included in the target DDL object, DDL statements can be divided into the following types:
Logical DDL statements: Logical DDL statements usually only modify the metadata of the database object, without processing the data stored in the object, for example, changing the table name or changing the column name.
In TiDB, logical DDL statements are also referred to as "general DDL". These statements typically have a short execution time, often taking only a few tens of milliseconds or seconds to complete. As a result, they do not consume much system resource and do not affect the workload on the application.
Physical DDL statements: Physical DDL statements not only modify the metadata of the object to be changed, but also modify the user data stored in the object. For example, when TiDB creates an index for a table, it not only changes the definition of the table, but also performs a full table scan to build the newly added index.
In TiDB, physical DDL statements are also referred to as "reorg DDL", which stands for reorganization. Currently, physical DDL statements only include
ADD INDEXand lossy column type changes (such as changing from anINTtype to aCHARtype). These statements take a long time to execute, and the execution time is affected by the amount of data in the table, the machine configuration, and the application workload.Executing physical DDL statements can have an impact on the workload of the application for two reasons. On the one hand, it consumes CPU and I/O resources from TiKV to read data and write new data. On the other hand, the TiDB node serving as DDL Owners or those TiDB nodes scheduled by the TiDB Distributed eXecution Framework (DXF) to execute
ADD INDEXtasks consume CPU resources from TiDB to perform the corresponding computations.
TiDB DDL module
The TiDB DDL module introduces the role of the DDL Owner (or Owner), which serves as a proxy for executing all DDL statements within the TiDB cluster. In the current implementation, only one TiDB node in the entire cluster can be elected as the Owner at any given time. Once a TiDB node is elected as Owner, the worker started in that TiDB node can handle the DDL tasks in the cluster.
TiDB uses the election mechanism of etcd to elect a node to host the Owner from multiple TiDB nodes. By default, each TiDB node can potentially be elected as the Owner (you can configure run-ddl to manage node participation in the election). The elected Owner node has a term, and it actively maintains the term by renewing it. When the Owner node is down, another node can be elected as the new Owner through etcd and continue executing DDL tasks in the cluster.
A simple illustration of the DDL Owner is as follows:
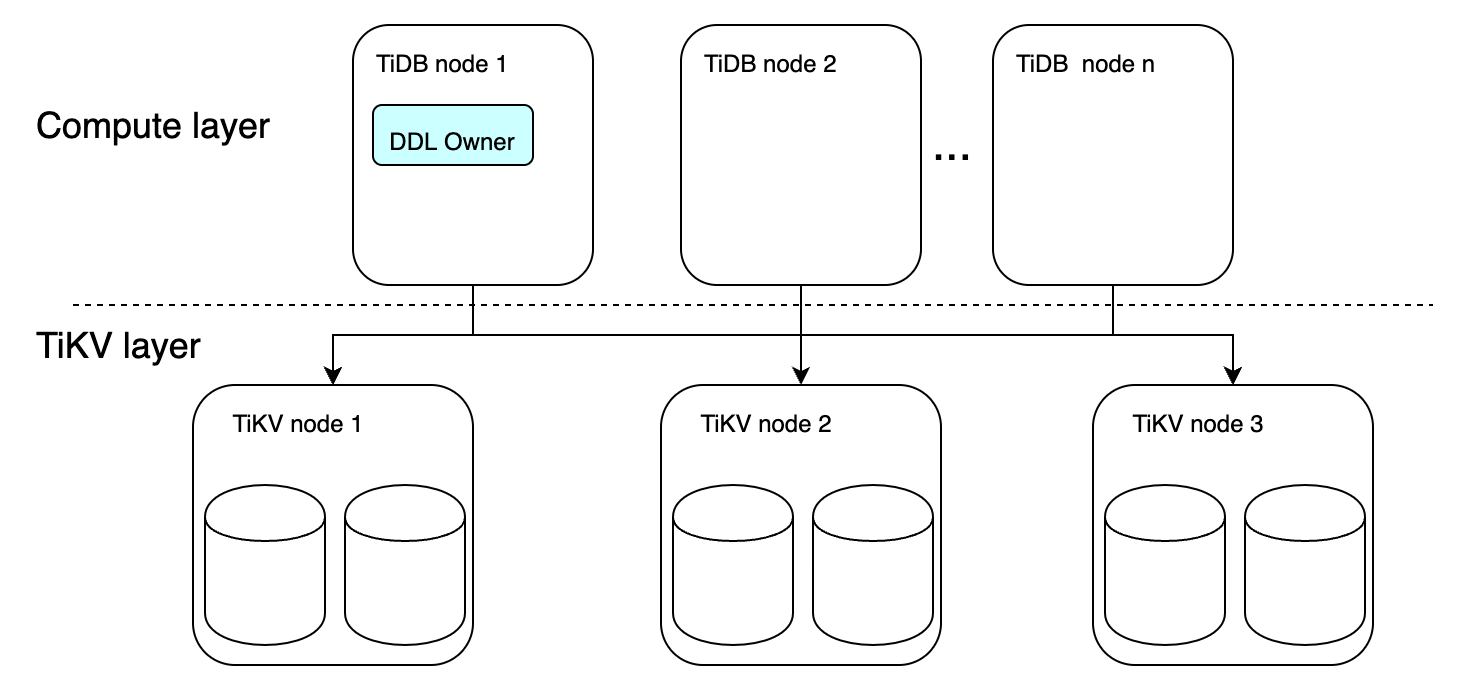
You can use the ADMIN SHOW DDL statement to view the current DDL owner:
ADMIN SHOW DDL;
+------------+--------------------------------------+---------------+--------------+--------------------------------------+-------+
| SCHEMA_VER | OWNER_ID | OWNER_ADDRESS | RUNNING_JOBS | SELF_ID | QUERY |
+------------+--------------------------------------+---------------+--------------+--------------------------------------+-------+
| 26 | 2d1982af-fa63-43ad-a3d5-73710683cc63 | 0.0.0.0:4000 | | 2d1982af-fa63-43ad-a3d5-73710683cc63 | |
+------------+--------------------------------------+---------------+--------------+--------------------------------------+-------+
1 row in set (0.00 sec)
How the online DDL asynchronous change works in TiDB
From the beginning of its design, the TiDB DDL module has opted for an online asynchronous change mode, which lets you modify your applications without experiencing any downtime.
DDL changes involve transitioning from one state to another, typically from a "before change" state to an "after change" state. With online DDL changes, this transition occurs by introducing multiple small version states that are mutually compatible. During the execution of a DDL statement, TiDB nodes in the same cluster are allowed to have different small version changes, as long as the difference between the small versions of the change objects is not more than two versions. This is possible because adjacent small versions can be mutually compatible.
In this way, evolving through multiple small versions ensures that metadata can be correctly synchronized across multiple TiDB nodes. This helps maintain the correctness and consistency of user transactions that involve changing data during the process.
Taking ADD INDEX as an example, the entire process of state change is as follows:
absent -> delete only -> write only -> write reorg -> public
For users, the newly created index is unavailable before the public state.
- Online DDL asychronous change before TiDB v6.2.0
- Parallel DDL framework starting from v6.2.0
Before v6.2.0, the process of handling asynchronous schema changes in the TiDB SQL layer is as follows:
MySQL Client sends a DDL request to a TiDB server.
After receiving the request, a TiDB server parses and optimizes the request at the MySQL Protocol layer, and then sends it to the TiDB SQL layer for execution.
Once the SQL layer of TiDB receives the DDL request, it starts the
start jobmodule to encapsulate the request into a specific DDL job (that is, a DDL task), and then stores this job in the corresponding DDL job queue in the KV layer based on the statement type. The corresponding worker is notified of the job that requires processing.When receiving the notification to process the job, the worker determines whether it has the role of the DDL Owner. If it does, it directly processes the job. Otherwise, it exits without any processing.
If a TiDB server is not the Owner role, then another node must be the Owner. The worker of the node in the Owner role periodically checks whether there is an available job that can be executed. If such a job is identified, the worker will process the job.
After the worker processes the Job, it removes the job from the job queue in the KV layer and places it in the
job history queue. Thestart jobmodule that encapsulated the job periodically checks the ID of the job in thejob history queueto see whether it has been processed. If so, the entire DDL operation corresponding to the job ends.TiDB server returns the DDL processing result to the MySQL Client.
Before TiDB v6.2.0, the DDL execution framework had the following limitations:
- The TiKV cluster only has two queues:
general job queueandadd index job queue, which handle logical DDL and physical DDL, respectively. - The DDL Owner always processes DDL jobs in a first-in-first-out way.
- The DDL Owner can only execute one DDL task of the same type (either logical or physical) at a time, which is relatively strict, and affects the user experience.
These limitations might lead to some "unintended" DDL blocking behavior. For more details, see SQL FAQ - DDL Execution.
Before TiDB v6.2.0, because the Owner can only execute one DDL task of the same type (either logical or physical) at a time, which is relatively strict, and affects the user experience.
If there is no dependency between DDL tasks, parallel execution does not affect data correctness and consistency. For example, user A adds an index to the T1 table, while user B deletes a column from the T2 table. These two DDL statements can be executed in parallel.
To improve the user experience of DDL execution, starting from v6.2.0, TiDB enables the Owner to determine the relevance of DDL tasks. The logic is as follows:
- DDL statements to be performed on the same table are mutually blocked.
DROP DATABASEand DDL statements that affect all objects in the database are mutually blocked.- Adding indexes and column type changes on different tables can be executed concurrently.
- A logical DDL statement must wait for the previous logical DDL statement to be executed before it can be executed.
- In other cases, DDL can be executed based on the level of availability for concurrent DDL execution.
In specific, TiDB has upgraded the DDL execution framework in v6.2.0 in the following aspects:
The DDL Owner can execute DDL tasks in parallel based on the preceding logic.
The first-in-first-out issue in the DDL Job queue has been addressed. The DDL Owner no longer selects the first job in the queue, but instead selects the job that can be executed at the current time.
The number of workers that handle physical DDL statements has been increased, enabling multiple physical DDL statements to be executed in parallel.
Because all DDL tasks in TiDB are implemented using an online change approach, TiDB can determine the relevance of new DDL jobs through the Owner, and schedule DDL tasks based on this information. This approach enables the distributed database to achieve the same level of DDL concurrency as traditional databases.
The concurrent DDL framework enhances the execution capability of DDL statements in TiDB, making it more compatible with the usage patterns of commercial databases.
Best practices
Balance the physical DDL execution speed and the impact on application load through system variables
When executing physical DDL statements (including adding indexes or column type changes), you can adjust the values of the following system variables to balance the speed of DDL execution and the impact on application load:
tidb_ddl_reorg_worker_cnt: This variable sets the number of reorg workers for a DDL operation, which controls the concurrency of backfilling.tidb_ddl_reorg_batch_size: This variable sets the batch size for a DDL operation in there-organizephase, which controls the amount of data to be backfilled.Recommended values:
- If there is no other load, you can increase the values of
tidb_ddl_reorg_worker_cntandtidb_ddl_reorg_batch_sizeto speed up theADD INDEXoperation. For example, you can set the values of the two variables to20and2048, respectively. - If there is other load, you can decrease the values of
tidb_ddl_reorg_worker_cntandtidb_ddl_reorg_batch_sizeto minimize the impact on other application. For example, you can set the values of the these variables to4and256, respectively.
- If there is no other load, you can increase the values of
Quickly create many tables by concurrently sending DDL requests
A table creation operation takes about 50 milliseconds. The actual time taken to create a table might be longer because of the framework limitations.
To create tables faster, it is recommended to send multiple DDL requests concurrently to achieve the fastest table creation speed. If you send DDL requests serially and do not send them to the Owner node, the table creation speed will be very slow.
Make multiple changes in a single ALTER statement
Starting from v6.2.0, TiDB supports modifying multiple schema objects (such as columns and indexes) of a table in a single ALTER statement while ensuring the atomicity of the entire statement. Therefore, it is recommended to make multiple changes in a single ALTER statement.
Check the read and write performance
When TiDB is adding an index, the phase of backfilling data will cause read and write pressure on the cluster. After the ADD INDEX command is sent and the write reorg phase starts, it is recommended to check the read and write performance metrics of TiDB and TiKV on the Grafana dashboard and the application response time, to determine whether the ADD INDEX operation affects the cluster.
DDL-related commands
ADMIN SHOW DDL: Used to view the status of TiDB DDL operations, including the current schema version number, the DDL ID and address of the DDL Owner, the DDL task and SQL being executed, and the DDL ID of the current TiDB instance. For details, seeADMIN SHOW DDL.ADMIN SHOW DDL JOBS: Used to view the detailed status of DDL tasks running in the cluster environment. For details, seeADMIN SHOW DDL JOBS.ADMIN SHOW DDL JOB QUERIES job_id [, job_id]: Used to view the original SQL statement of the DDL task corresponding to thejob_id. For details, seeADMIN SHOW DDL JOB QUERIES.ADMIN CANCEL DDL JOBS job_id, [, job_id]: Used to cancel DDL tasks that have been submitted but not completed. After the cancellation is completed, the SQL statement that executes the DDL task returns theERROR 8214 (HY000): Cancelled DDL joberror.If a completed DDL task is canceled, you can see the
DDL Job:90 not founderror in theRESULTcolumn, which means that the task has been removed from the DDL waiting queue.ADMIN PAUSE DDL JOBS job_id [, job_id]: Used to pause the DDL jobs that are being executed. After the command is executed, the SQL statement that executes the DDL job is displayed as being executed, while the background job has been paused. For details, refer toADMIN PAUSE DDL JOBS.You can only pause DDL tasks that are in progress or still in the queue. Otherwise, the
Job 3 can't be paused nowerror is shown in theRESULTcolumn.ADMIN RESUME DDL JOBS job_id [, job_id]: Used to resume the DDL tasks that have been paused. After the command is executed, the SQL statement that executes the DDL task is displayed as being executed, and the background task is resumed. For details, refer toADMIN RESUME DDL JOBS.You can only resume a paused DDL task. Otherwise, the
Job 3 can't be resumederror is shown in theRESULTcolumn.
Common questions
For common questions about DDL execution, see SQL FAQ - DDL execution.