TiCDC のパフォーマンス分析およびチューニング方法
このドキュメントでは、TiCDC リソースの使用率と主要なパフォーマンス メトリクスを紹介します。パフォーマンス概要ダッシュボードのCDCパネルを通じて、データ レプリケーションにおける TiCDC パフォーマンスを監視および評価できます。
TiCDC クラスターのリソース使用率
次の 3 つのメトリックを使用すると、TiCDC クラスターのリソース使用率をすぐに取得できます。
- CPU 使用率: TiCDC ノードごとの CPU 使用率。
- メモリ使用量: TiCDC ノードごとのメモリ使用量。
- ゴルーチン数: TiCDC ノードごとのゴルーチンの数。
TiCDC データ レプリケーションの主要な指標
TiCDC 全体的な指標
次のメトリクスを使用すると、TiCDC データ レプリケーションの概要を把握できます。
チェンジフィード チェックポイント ラグ: アップストリームとダウンストリーム間のデータ レプリケーションの進行ラグ (秒単位で測定)。
TiCDC がデータを消費してダウンストリームに書き込む速度がアップストリームのデータ変更に追いついていれば、このメトリクスは小さなレイテンシー範囲内 (通常は 10 秒以内) に収まります。そうしないと、この指標は増加し続けることになります。
このメトリクス (つまり
Changefeed checkpoint lag) が増加する場合、一般的な理由は次のとおりです。- システム リソースの不足: TiCDC の CPU、メモリ、またはディスク容量が不十分な場合、データ処理が遅くなりすぎて、TiCDC 変更フィードのチェックポイントが長くなる可能性があります。
- ネットワークの問題: TiCDC でネットワークの中断、遅延、または帯域幅不足が発生すると、データ転送速度に影響を与える可能性があり、その結果、TiCDC 変更フィードのチェックポイントが長くなります。
- アップストリームでの高い QPS: TiCDC によって処理されるデータが大きすぎる場合、データ処理タイムアウトが発生する可能性があり、その結果、TiCDC 変更フィードのチェックポイントが増加します。通常、単一の TiCDC ノードは最大約 60K の QPS を処理できます。
- データベースの問題:
- 上流の TiKV クラスターの
min resolved tsと最新の PD TSO の間のギャップは重大です。この問題は通常、アップストリームの書き込みワークロードが過度に重い場合に、TiKV が解決された ts を時間内に進めることができないために発生します。 - ダウンストリーム データベースの書き込みレイテンシーが長く、TiCDC がデータをダウンストリームにタイムリーに複製できなくなります。
- 上流の TiKV クラスターの
変更フィード解決 ts ラグ: TiCDC ノードの内部レプリケーション ステータスとアップストリームの間の進行ラグ (秒単位で測定)。このメトリクスが高い場合は、TiCDC Puller または Sorter モジュールのデータ処理能力が不十分であるか、ネットワークレイテンシーまたはディスク読み取り/書き込み速度の遅さの問題が発生している可能性があることを示します。このような場合、TiCDC を効率的かつ安定的に動作させるには、TiCDC ノードの数を増やしたり、ネットワーク構成を最適化するなどの適切な措置を講じる必要があります。
チェンジフィードのステータス: チェンジフィードのステータスの説明については、 チェンジフィード状態転送を参照してください。
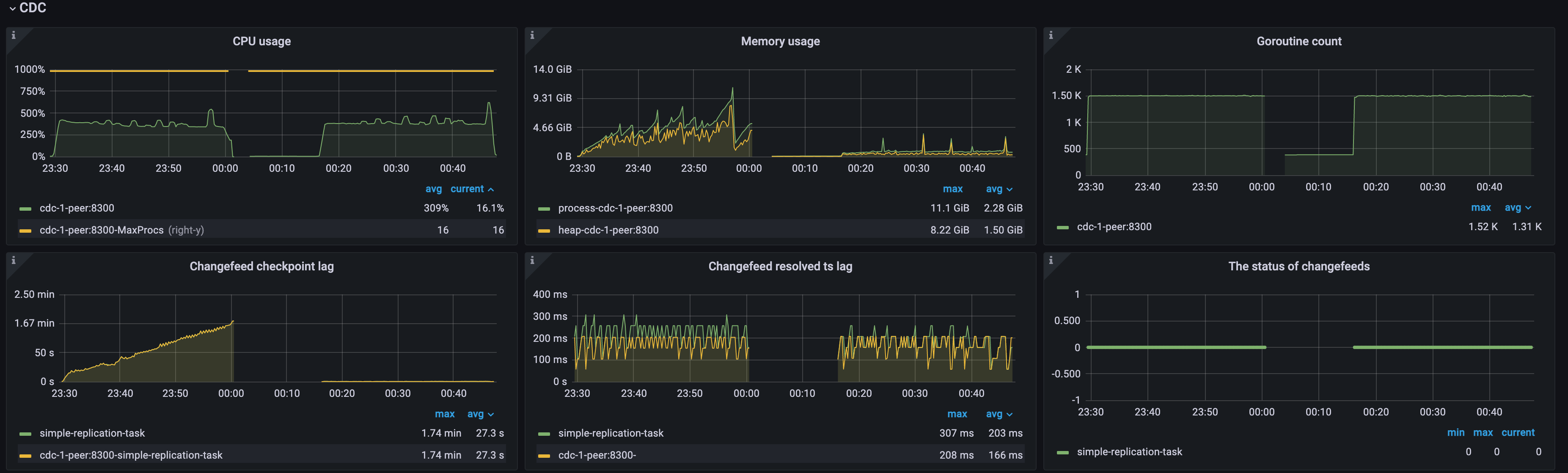
例 1: 単一 TiCDC ノードの場合、高いアップストリーム QPS による高いチェックポイント ラグ
次の図に示すように、アップストリーム QPS が高すぎて、クラスター内に TiCDC ノードが 1 つしかないため、TiCDC ノードは過負荷になり、CPU 使用率が高くなり、 Changefeed checkpoint lagとChangefeed resolved ts lagの両方が増加し続けます。チェンジフィードのステータスは断続的に0から1に移行し、チェンジフィードでエラーが発生し続けていることを示します。次のようにリソースを追加することで、この問題の解決を試みることができます。
- TiCDC ノードをさらに追加する: TiCDC クラスターを複数のノードにスケールアウトして、処理能力を向上させます。
- TiCDC ノード リソースの最適化: TiCDC ノードの CPU およびメモリ構成を増やしてパフォーマンスを向上させます。
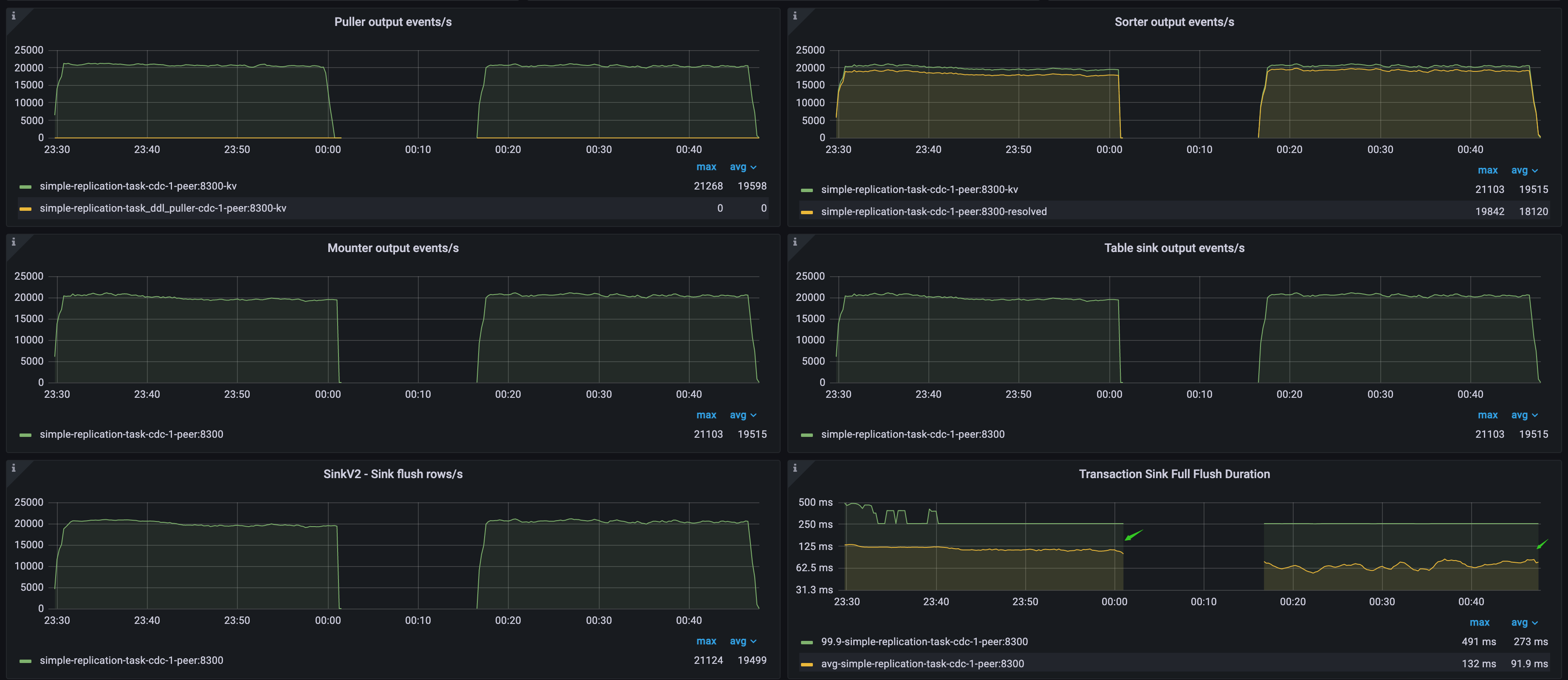
データ フローのスループット メトリックとダウンストリームレイテンシー
次のメトリクスを使用して、TiCDC のデータ フロー スループットとダウンストリームレイテンシーを知ることができます。
- Puller 出力イベント/秒: TiCDC ノードの Puller モジュールが Sorter モジュールに送信する 1 秒あたりの行数。
- ソーター出力イベント/秒: TiCDC ノードのソーター モジュールがマウンター モジュールに送信する 1 秒あたりの行数。
- マウンター出力イベント/秒: TiCDC ノードのマウンター モジュールがシンク モジュールに送信する 1 秒あたりの行数。
- テーブル シンク出力イベント/秒: TiCDC ノードのテーブル ソーター モジュールがシンク モジュールに送信する 1 秒あたりの行数。
- SinkV2 - シンク フラッシュ行数/秒: TiCDC ノードのシンク モジュールがダウンストリームに送信する 1 秒あたりの行数。
- トランザクションシンクのフル フラッシュ期間: TiCDC ノードの MySQL シンクによるダウンストリーム トランザクションの書き込みの平均レイテンシーと p999レイテンシー。
- MQ ワーカーのメッセージ送信期間パーセンタイル: ダウンストリームが Kafka である場合の MQ ワーカーによるメッセージ送信のレイテンシー。
- Kafka 送信バイト: MQ ワークロードでのダウンストリーム トランザクションの書き込みトラフィック。
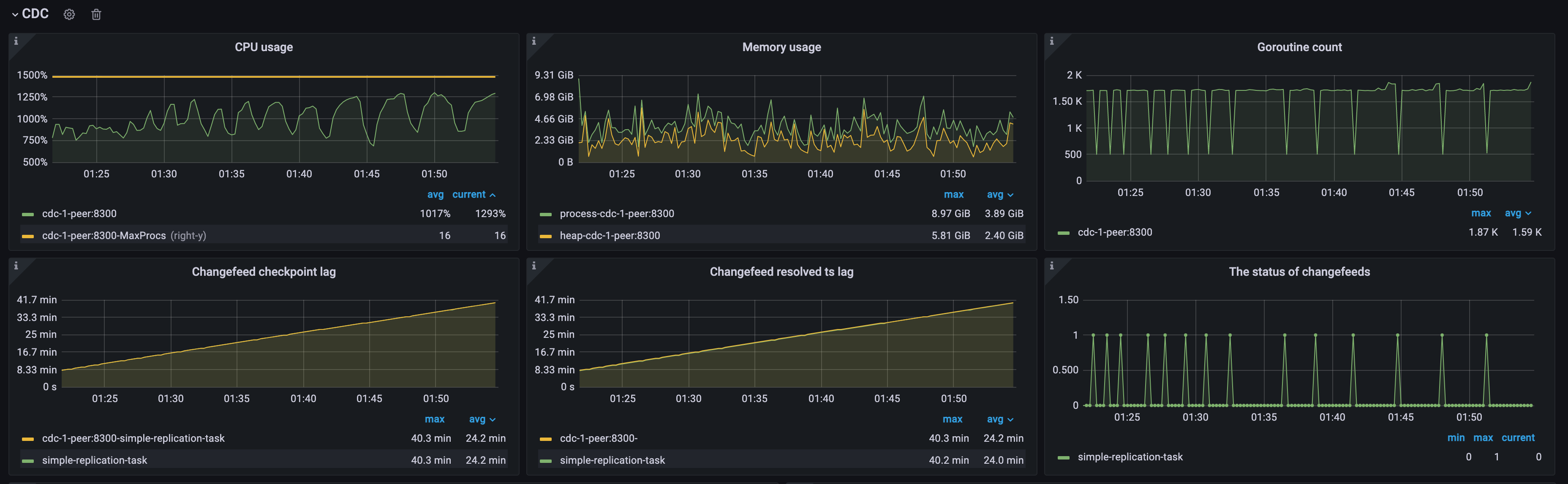
例 2: TiCDC データ レプリケーションのパフォーマンスに対するダウンストリーム データベースの書き込み速度の影響
次の図に示すように、アップストリームとダウンストリームの両方が TiDB クラスターです。 TiCDC Puller output events/sメトリックは、アップストリーム データベースの QPS を示します。 Transaction Sink Full Flush Durationメトリックは、ダウンストリーム データベースの平均書き込みレイテンシーを示します。最初のワークロードでは高く、2 番目のワークロードでは低くなります。
- 最初のワークロード中は、ダウンストリーム TiDB クラスターのデータの書き込みが遅いため、TiCDC はアップストリーム QPS に遅れる速度でデータを消費し、
Changefeed checkpoint lagが継続的に増加します。ただし、Changefeed resolved ts lag300 ミリ秒以内にとどまっており、レプリケーションの遅延とスループットのボトルネックがプーラー モジュールとソーター モジュールによって引き起こされているのではなく、下流のシンク モジュールによって引き起こされていることを示しています。 - 2 番目のワークロード中は、ダウンストリーム TiDB クラスターのデータ書き込み速度が速いため、TiCDC はアップストリームに完全に追いつく速度でデータをレプリケートします。1 と
Changefeed checkpoint lagChangefeed resolved ts lag500 ミリ秒以内に留まり、これは TiCDC にとって比較的理想的なレプリケーション速度です。