タイタンの概要
巨人は、キーと値の分離のための高性能RocksDBプラグインです。大きな値が使用されている場合、Titan は RocksDB での書き込み増幅を減らすことができます。
キーと値のペアの値のサイズが大きい (1 KB または 512 B より大きい) 場合、Titan は書き込み、更新、およびポイント読み取りのシナリオで RocksDB よりも優れたパフォーマンスを発揮します。ただし、Titan は、storageスペースと範囲クエリのパフォーマンスを犠牲にすることで、より高い書き込みパフォーマンスを実現します。 SSD の価格が下がり続けるにつれて、このトレードオフはますます重要になります。
主な機能
- ログ構造のマージ ツリー (LSM ツリー) から値を分離し、個別に格納することで、書き込み増幅を減らします。
- RocksDB インスタンスを Titan にシームレスにアップグレードします。アップグレードは人間の介入を必要とせず、オンライン サービスに影響を与えません。
- 現在の TiKV で使用されているすべての RocksDB 機能と 100% の互換性を実現します。
使用シナリオ
Titan は、大量のデータが TiKV フォアグラウンドに書き込まれるシナリオに適しています。
- RocksDB は大量の圧縮をトリガーし、大量の I/O 帯域幅または CPU リソースを消費します。これにより、フォアグラウンドの読み取りおよび書き込みパフォーマンスが低下します。
- RocksDB の圧縮は (I/O 帯域幅の制限または CPU のボトルネックが原因で) 大幅に遅れ、頻繁に書き込み停止が発生します。
- RocksDB は大量の圧縮をトリガーします。これにより、大量の I/O 書き込みが発生し、SSD ディスクの寿命に影響します。
前提条件
Titan を有効にするための前提条件は次のとおりです。
- 値の平均サイズが大きいか、すべての大きな値のサイズが値の合計サイズの大部分を占めています。現在、1 KB を超える値のサイズは大きな値と見なされます。場合によっては、この数値 (1 KB) が 512 B になることがあります。TiKV Raftレイヤーの制限により、TiKV に書き込まれる単一の値が 8 MB を超えることはできないことに注意してください。
raft-entry-max-size構成値を調整して制限を緩和できます。 - 範囲クエリは実行されないか、範囲クエリのパフォーマンスを高くする必要はありません。 Titan に格納されたデータは適切に整理されていないため、範囲クエリのパフォーマンスは RocksDB のパフォーマンスよりも低く、特に大きな範囲のクエリでは低下します。 PingCAP の内部テストによると、Titan の範囲クエリのパフォーマンスは、RocksDB のパフォーマンスよりも 40% から数倍低くなります。
- 十分なディスク容量 (同じデータ量で RocksDB ディスク消費量の 2 倍の容量を予約することを検討してください)。これは、Titan がディスク容量を犠牲にして書き込み増幅を減らすためです。また、Titan は値を 1 つずつ圧縮しますが、その圧縮率は RocksDB よりも低くなります。 RocksDB はブロックを 1 つずつ圧縮します。したがって、Titan は RocksDB よりも多くのstorageスペースを消費しますが、これは予想されることであり、通常のことです。状況によっては、Titan のstorage消費量が RocksDB の 2 倍になることがあります。
Titan のパフォーマンスを向上させたい場合は、ブログ投稿Titan: 書き込み増幅を減らすための RocksDB プラグインを参照してください。
アーキテクチャと実装
次の図は、Titan のアーキテクチャを示しています。
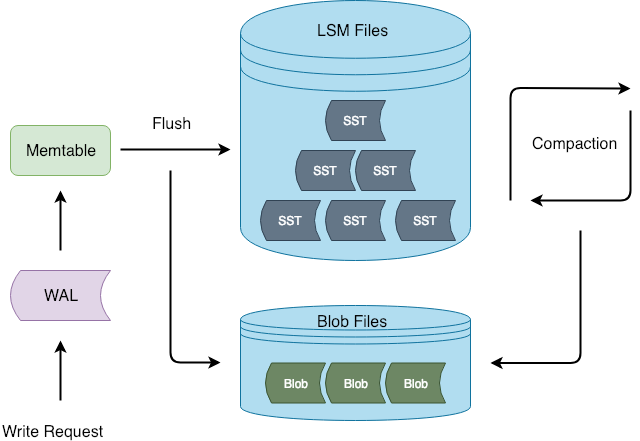
フラッシュおよび圧縮操作中に、Titan は LSM ツリーから値を分離します。このアプローチの利点は、書き込みプロセスが RocksDB と一貫性があることです。これにより、RocksDB への侵襲的な変更の可能性が減少します。
ブロブファイル
Titan は値ファイルを LSM ツリーから分離するときに、値ファイルを BlobFile に格納します。次の図は、BlobFile 形式を示しています。
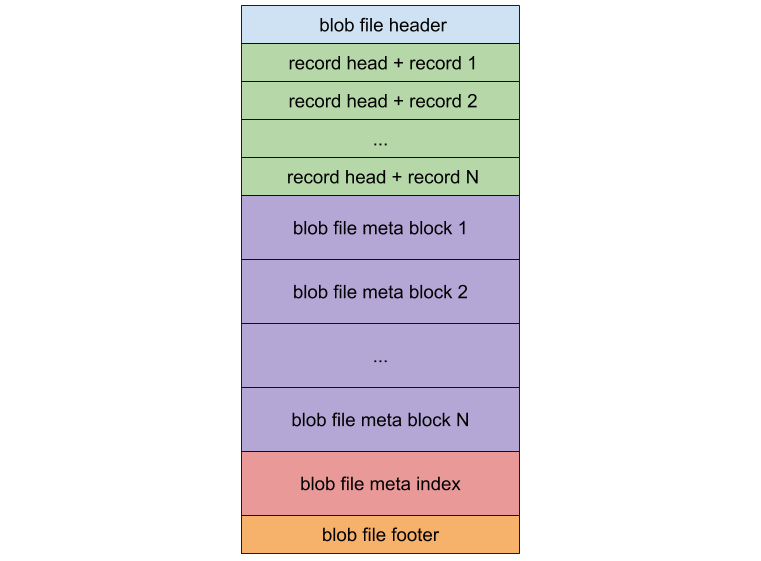
BLOB ファイルは、主に BLOB レコード、メタ ブロック、メタ インデックス ブロック、およびフッターで構成されます。各ブロック レコードには、キーと値のペアが格納されます。メタ ブロックはスケーラビリティのために使用され、BLOB ファイルに関連するプロパティを格納します。メタ インデックス ブロックは、メタ ブロックの検索に使用されます。
ノート:
- blob ファイル内の Key-Value ペアは順番に格納されるため、Iterator を実装すると、プリフェッチによって順次読み取りのパフォーマンスを向上させることができます。
- 各 BLOB レコードは、値に対応するユーザー キーのコピーを保持します。このようにして、Titan がガベージ コレクション (GC) を実行するときに、ユーザー キーを照会し、対応する値が古いかどうかを識別できます。ただし、このプロセスでは、書き込み増幅が発生します。
- BlobFile は、BLOB レコード レベルでの圧縮をサポートしています。 Titan は、 スナッピー 、 LZ4 、 Zstdなどの複数の圧縮アルゴリズムをサポートしています。現在、Titan が使用するデフォルトの圧縮アルゴリズムは LZ4 です。
TitanTableBuilder
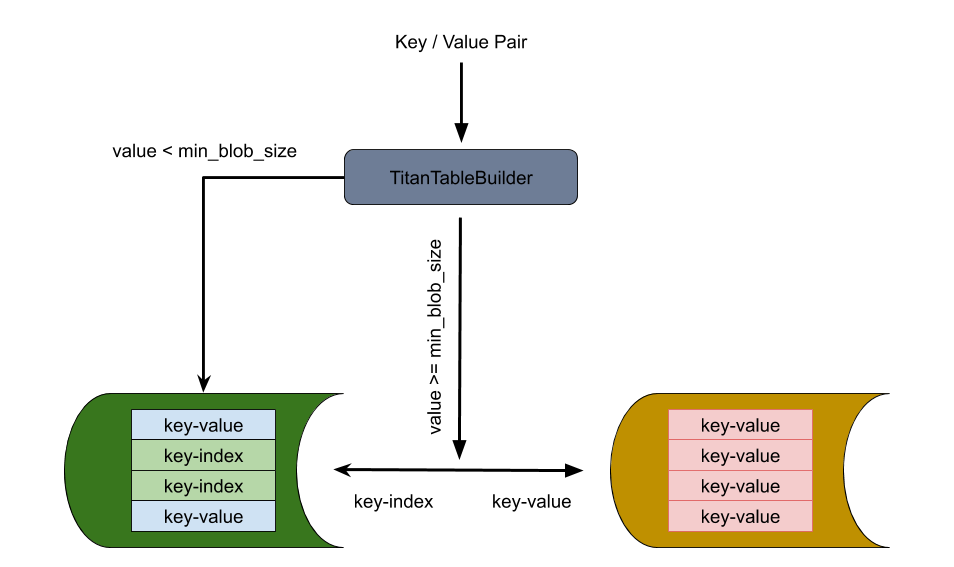
TitanTableBuilder は、キーと値の分離を実現するための鍵です。 TitanTableBuilder は、キー ペアの値のサイズを決定し、それに基づいて、キーと値のペアから値を分離して blob ファイルに格納するかどうかを決定します。
- 値のサイズが
min_blob_size以上の場合、TitanTableBuilder は値を分離して blob ファイルに格納します。また、TitanTableBuilder はインデックスを生成し、それを SST に書き込みます。 - 値のサイズが
min_blob_sizeより小さい場合、TitanTableBuilder は値を SST に直接書き込みます。
上記のプロセスで、Titan を RocksDB にダウングレードすることもできます。 RocksDB が圧縮を実行しているときに、分離された値を新しく生成された SST ファイルに書き戻すことができます。
ガベージ コレクション
Titan はガベージ コレクション (GC) を使用してスペースを再利用します。キーは LSM ツリーの圧縮で再利用されるため、BLOB ファイルに格納されている一部の値は同時に削除されません。したがって、Titan は定期的に GC を実行して古い値を削除する必要があります。 Titan は、次の 2 種類の GC を提供します。
- Blob ファイルは定期的に統合され、古い値を削除するために書き換えられます。これは、GC を実行する通常の方法です。
- BLOB ファイルは、LSM ツリーの圧縮が同時に実行されている間に書き換えられます。これがレベルマージの特徴です。
通常のGC
Titan は、RocksDB の TablePropertiesCollector および EventListener コンポーネントを使用して、GC の情報を収集します。
テーブル プロパティ コレクター
RocksDB は、対応する SST ファイルに書き込まれる SST からプロパティを収集するために、カスタム テーブル プロパティ コレクターである BlobFileSizeCollector の使用をサポートします。収集されたプロパティには、BlobFileSizeProperties という名前が付けられます。次の図は、BlobFileSizeCollector のワークフローとデータ形式を示しています。
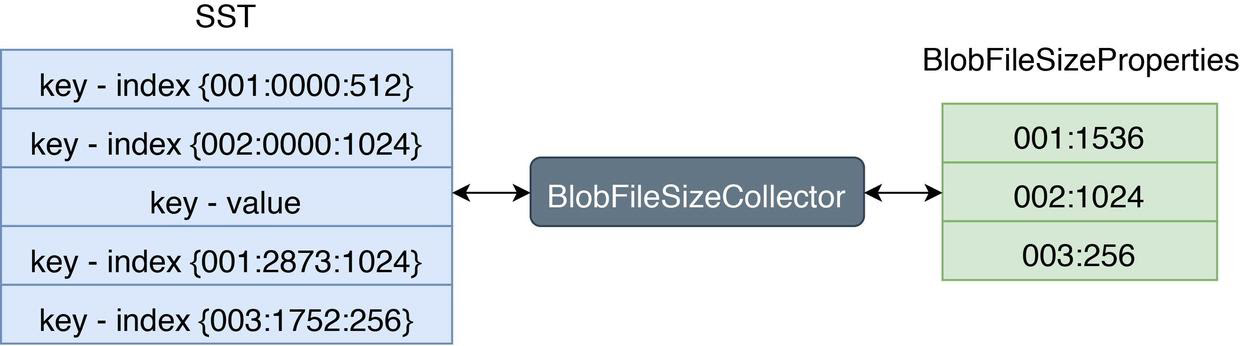
左側は SST インデックス形式です。最初の列は BLOB ファイル ID です。 2 番目の列は、BLOB ファイル内の BLOB レコードのオフセットです。 3 番目の列は BLOB レコードのサイズです。
右側は BlobFileSizeProperties 形式です。各行は、BLOB ファイルと、この BLOB ファイルに保存されるデータの量を表します。最初の列は BLOB ファイル ID です。 2 列目はデータのサイズです。
イベントリスナー
RocksDB は圧縮を使用して古いデータを破棄し、スペースを再利用します。各圧縮の後、Titan の一部の BLOB ファイルには、部分的または完全に古いデータが含まれる場合があります。したがって、圧縮イベントをリッスンすることで GC をトリガーできます。圧縮中に、SST の入力/出力 BLOB ファイル サイズ プロパティを収集して比較し、GC が必要な BLOB ファイルを特定できます。次の図は、一般的なプロセスを示しています。
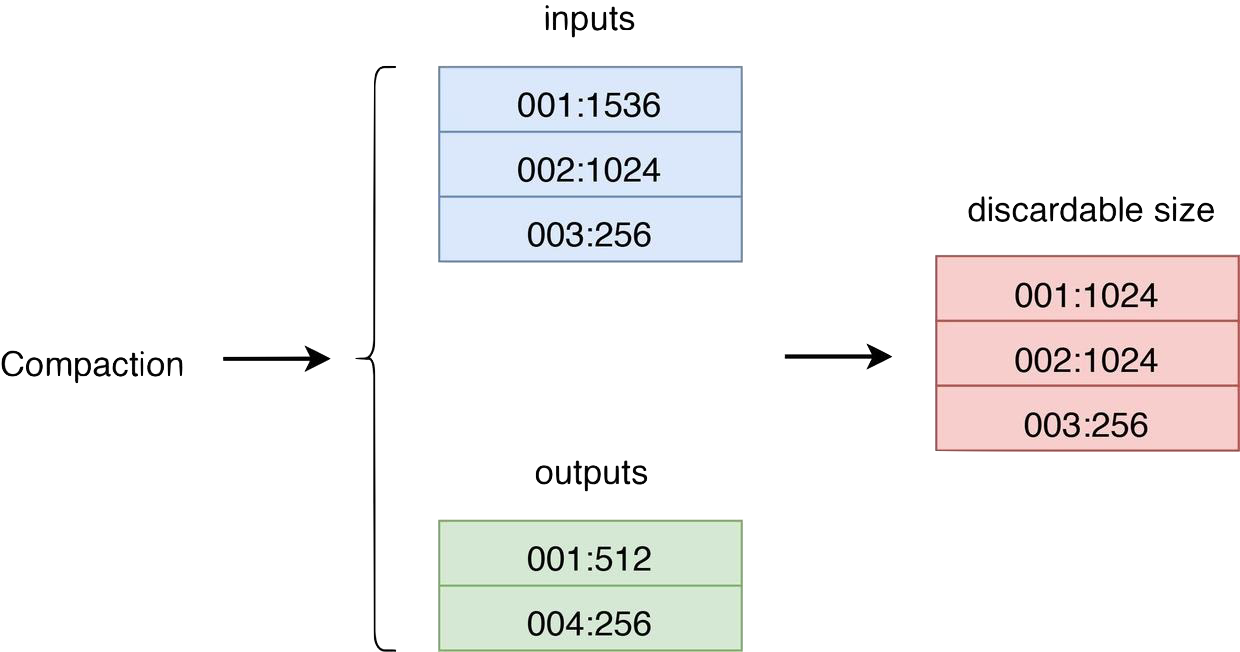
- 入力は、圧縮に参加するすべての SST の BLOB ファイル サイズ プロパティを表します。
- 出力は、圧縮で生成されたすべての SST の BLOB ファイル サイズ プロパティを表します。
- 破棄可能なサイズは、入力と出力に基づいて計算された、BLOB ファイルごとに破棄されるファイルのサイズです。最初の列は BLOB ファイル ID です。 2 番目の列は、破棄されるファイルのサイズです。
有効なブロブ ファイルごとに、Titan は破棄可能なサイズ変数をメモリに保持します。各圧縮の後、この変数は対応する BLOB ファイルに蓄積されます。 GC が開始されるたびに、破棄可能なサイズが最大の BLOB ファイルが GC の候補ファイルとして選択されます。書き込み増幅を減らすために、一定レベルのスペース増幅が許可されます。つまり、破棄可能なファイルのサイズが特定の比率に達した場合にのみ、BLOB ファイルで GC を開始できます。
選択された BLOB ファイルについて、Titan は、各値に対応するキーの BLOB インデックスが存在するかどうか、または更新されているかどうかをチェックして、この値が古いかどうかを判断します。値が古くない場合、Titan は値をマージして新しい BLOB ファイルに並べ替え、WriteCallback または MergeOperator を使用して更新された BLOB インデックスを SST に書き込みます。次に、Titan は RocksDB の最新のシーケンス番号を記録し、最も古いスナップショットのシーケンスが記録されたシーケンス番号を超えるまで古い BLOB ファイルを削除しません。その理由は、BLOB インデックスが SST に書き戻された後でも、以前のスナップショットを介して古い BLOB インデックスにアクセスできるためです。したがって、GC が対応する BLOB ファイルを安全に削除する前に、スナップショットが古い BLOB インデックスにアクセスしないようにする必要があります。
レベルマージ
レベル マージは、Titan で新しく導入されたアルゴリズムです。 Level Merge の実装原理に従い、Titan は SST ファイルに対応する blob ファイルをマージして書き換え、LSM-tree で圧縮を行いながら新しい blob ファイルを生成します。次の図は、一般的なプロセスを示しています。
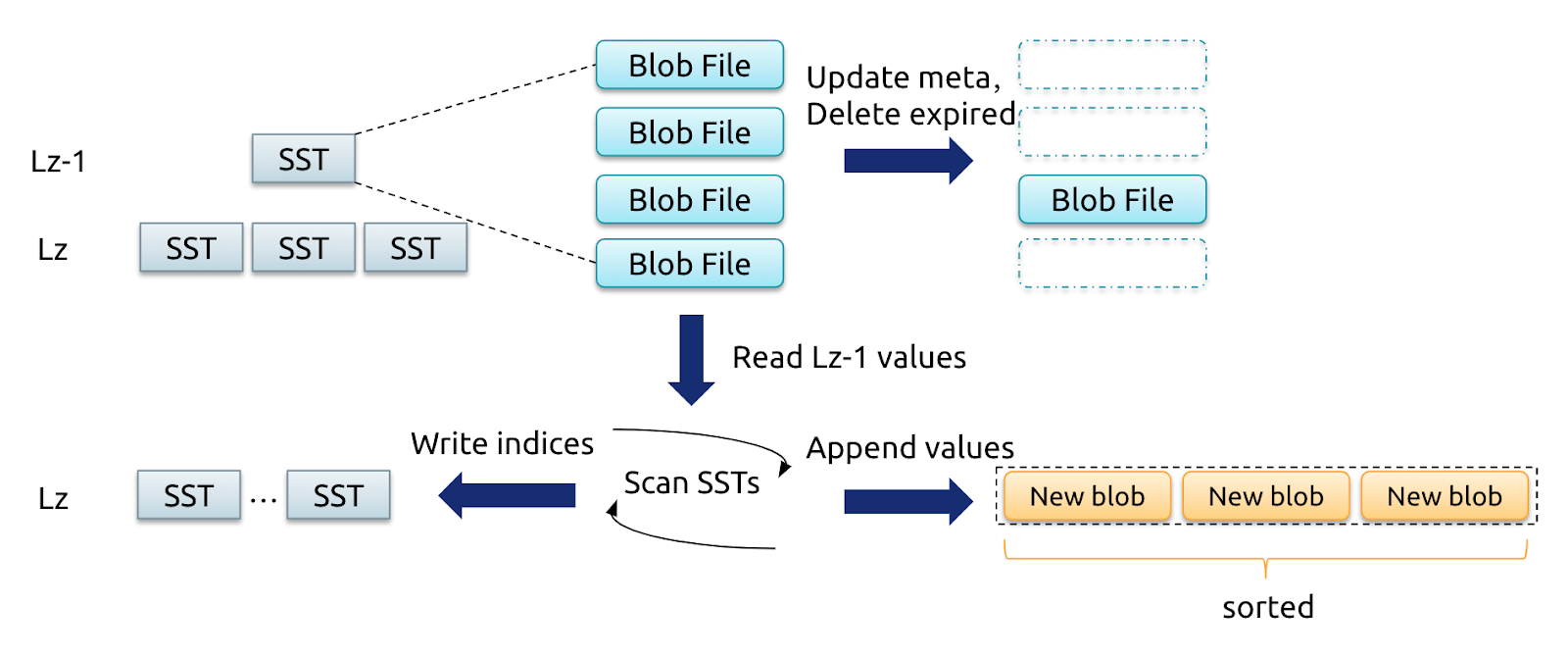
レベル z-1 とレベル z の SST で圧縮が実行されると、Titan はキーと値のペアを順番に読み書きします。次に、選択した BLOB ファイルの値を新しい BLOB ファイルに順番に書き込み、新しい SST が生成されるとキーの BLOB インデックスを更新します。コンパクションで削除されたキーの場合、対応する値は新しい BLOB ファイルに書き込まれません。これは GC と同様に機能します。
GC の通常の方法と比較して、レベル マージ アプローチは、圧縮が LSM ツリーで実行されている間にブロブ GC を完了します。このようにして、Titan は LSM ツリーの BLOB インデックスのステータスをチェックしたり、新しい BLOB インデックスを LSM ツリーに書き込んだりする必要がなくなりました。これにより、フォアグラウンド操作に対する GC の影響が軽減されます。 BLOB ファイルは繰り返し書き換えられるため、重複するファイルが少なくなり、システム全体の秩序が整い、スキャンのパフォーマンスが向上します。
ただし、階層化コンパクションと同様に BLOB ファイルを階層化すると、書き込みが増幅されます。 LSM ツリーのデータの 99% は最下位 2 レベルに格納されるため、Titan は、LSM ツリーの最下位 2 レベルにのみ圧縮されたデータに対応する BLOB ファイルに対してレベル マージ操作を実行します。
レンジマージ
Range Merge は、Level Merge に基づく GC の最適化されたアプローチです。ただし、次の状況では、LSM ツリーの最下位レベルの順序が悪くなる可能性があります。
level_compaction_dynamic_level_bytesを有効にすると、LSM ツリーの各レベルのデータ量が動的に増加し、最下位レベルでソートされたランが増加し続けます。- 特定の範囲のデータが頻繁に圧縮されるため、その範囲で多くの並べ替えが実行されます。

したがって、並べ替えられた実行の数を特定のレベル内に保つには、Range Merge 操作が必要です。 OnCompactionComplete の時点で、Titan は範囲内の並べ替えられた実行の数をカウントします。数が多い場合、Titan は対応する BLOB ファイルを ToMerge としてマークし、次の圧縮でそれを書き換えます。