TiCDC のアーキテクチャと原理
TiCDCアーキテクチャ
複数の TiCDC ノードで構成される TiCDC クラスターは、分散型のステートレスアーキテクチャを使用します。 TiCDC とそのコンポーネントの設計は次のとおりです。
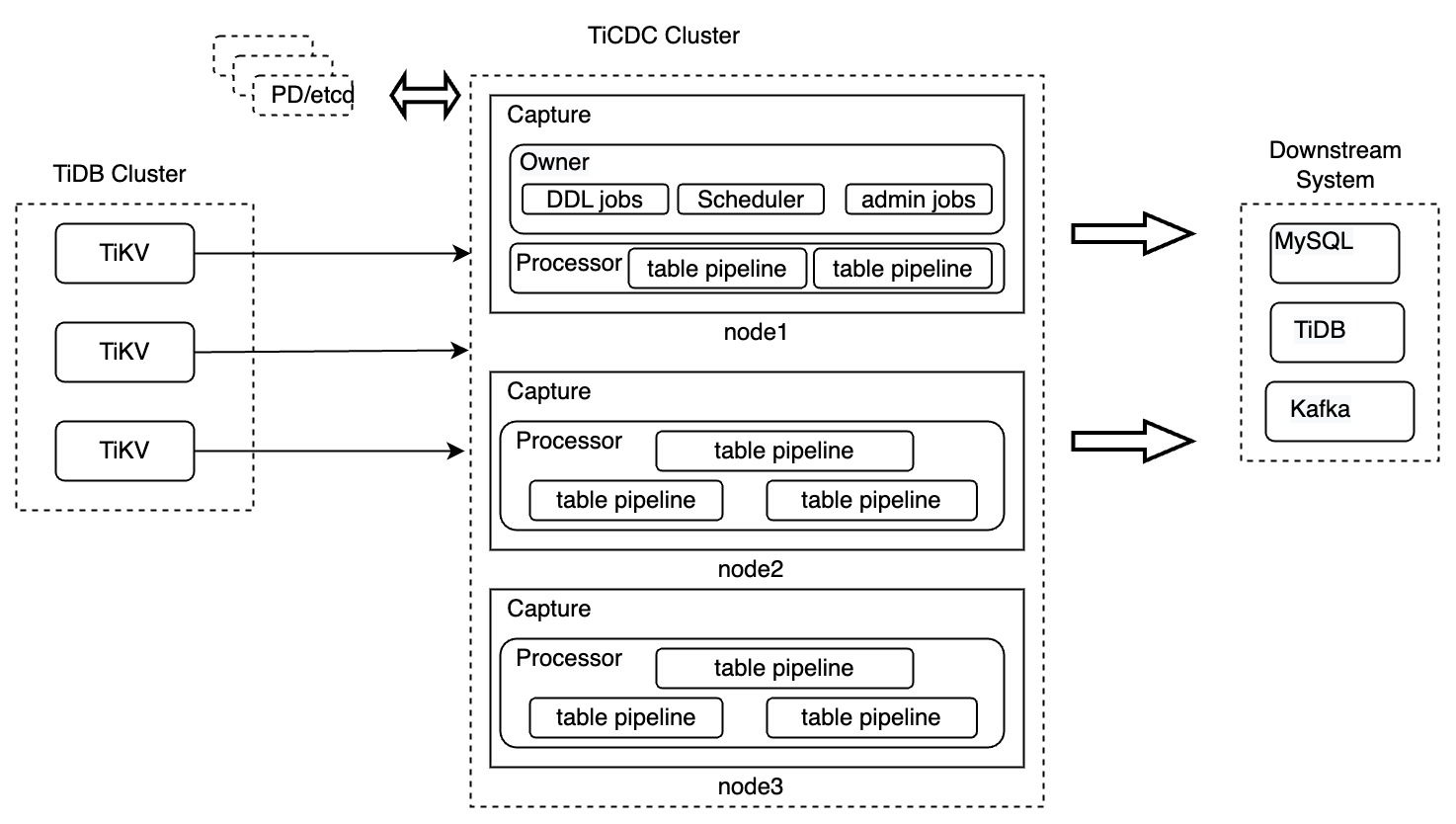
TiCDC コンポーネント
前の図では、TiCDC クラスターは、TiCDC インスタンスを実行する複数のノードで構成されています。各 TiCDC インスタンスは Capture プロセスを実行します。 Capture プロセスの 1 つが所有者 Capture として選出され、ワークロードのスケジューリング、DDL ステートメントの複製、および管理タスクの実行を担当します。
各キャプチャ プロセスには、上流の TiDB 内のテーブルからデータを複製するための 1 つまたは複数のプロセッサ スレッドが含まれています。テーブルは TiCDC におけるデータ複製の最小単位であるため、プロセッサは複数のテーブル パイプラインで構成されます。
各パイプラインには、次のコンポーネントが含まれています: Puller、Sorter、Mounter、および Sink。
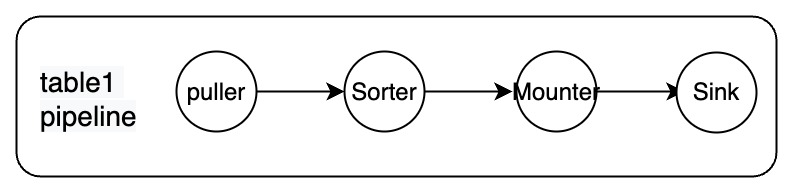
これらのコンポーネントは、データのプル、データの並べ替え、データのロード、アップストリームからダウンストリームへのデータの複製など、複製プロセスを完了するために相互に連続して動作します。コンポーネントは次のように説明されています。
- プラー: TiKV ノードから DDL と行の変更をプルします。
- ソーター: TiKV ノードから受信した変更をタイムスタンプの昇順で並べ替えます。
- Mounter: スキーマ情報に基づいて、TiCDC シンクが処理できる形式に変更を変換します。
- シンク: ダウンストリーム システムに変更をレプリケートします。
高可用性を実現するために、各 TiCDC クラスターは複数の TiCDC ノードを実行します。これらのノードは定期的にそのステータスを PD の etcd クラスターに報告し、ノードの 1 つを TiCDC クラスターの所有者として選出します。所有者ノードは、etcd に保存されているステータスに基づいてデータをスケジュールし、スケジュール結果を etcd に書き込みます。プロセッサは、etcd のステータスに従ってタスクを完了します。プロセッサを実行しているノードに障害が発生した場合、クラスターはテーブルを他のノードにスケジュールします。所有者ノードに障害が発生すると、他のノードの Capture プロセスが新しい所有者を選択します。次の図を参照してください。
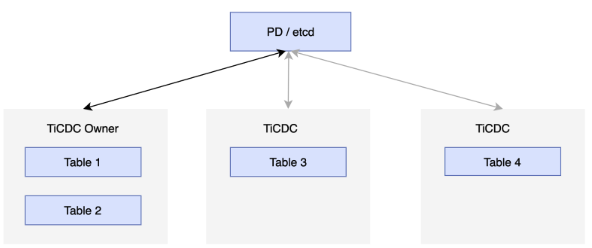
変更フィードとタスク
TiCDC の Changefeed と Task は、2 つの論理的な概念です。具体的な説明は次のとおりです。
- Changefeed: レプリケーション タスクを表します。レプリケートされるテーブルとダウンストリームに関する情報を運びます。
- タスク: TiCDC がレプリケーション タスクを受け取ると、このタスクをいくつかのサブタスクに分割します。このようなサブタスクはタスクと呼ばれます。これらのタスクは、処理のために TiCDC ノードのキャプチャ プロセスに割り当てられます。
例えば:
cdc cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://127.0.0.1:9092/cdc-test?kafka-version=2.4.0&partition-num=6&max-message-bytes=67108864&replication-factor=1"
cat changefeed.toml
......
[sink]
dispatchers = [
{matcher = ['test1.tab1', 'test2.tab2'], topic = "{schema}_{table}"},
{matcher = ['test3.tab3', 'test4.tab4'], topic = "{schema}_{table}"},
]
上記のcdc cli changefeed createコマンドのパラメーターの詳細な説明については、 TiCDC Changefeedコンフィグレーションパラメータを参照してください。
上記のcdc cli changefeed createコマンドは、 test1.tab1 、 test1.tab2 、 test3.tab3 、およびtest4.tab4を Kafka クラスターにレプリケートする changefeed タスクを作成します。 TiCDC がこのコマンドを受信した後の処理の流れは次のとおりです。
- TiCDC は、このタスクを所有者の Capture プロセスに送信します。
- 所有者の Capture プロセスは、この changefeed タスクに関する情報を PD の etcd に保存します。
- 所有者の Capture プロセスは、changefeed タスクをいくつかのタスクに分割し、完了すべきタスクを他の Capture プロセスに通知します。
- キャプチャ プロセスは、TiKV ノードからのデータのプルを開始し、データを処理して、レプリケーションを完了します。
以下は、Changefeed と Task を含む TiCDCアーキテクチャ図です。
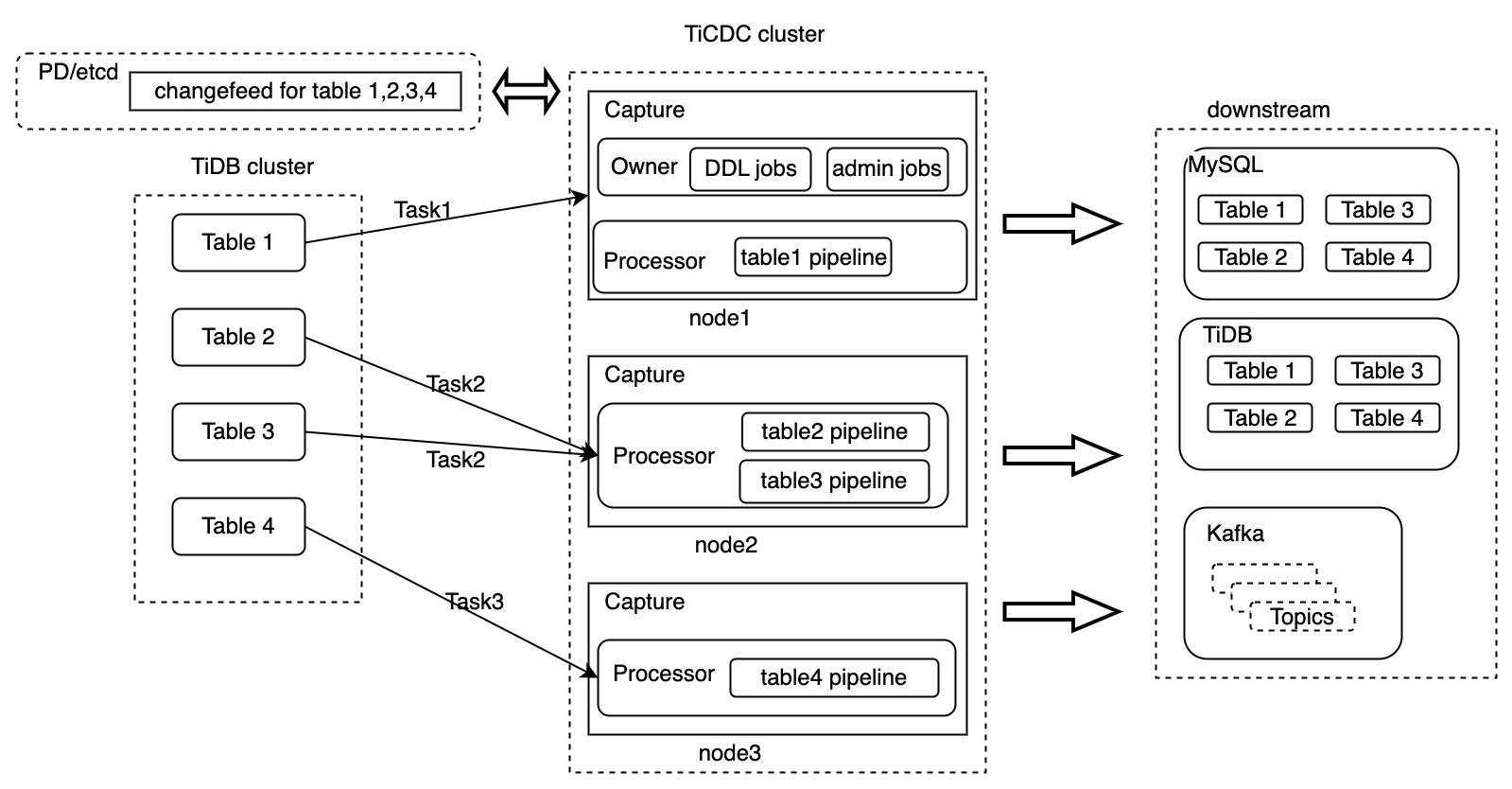
前の図では、4 つのテーブルをダウンストリームにレプリケートするための変更フィードが作成されています。この変更フィードは 3 つのタスクに分割され、TiCDC クラスター内の 3 つの Capture プロセスにそれぞれ送信されます。 TiCDC がデータを処理した後、データはダウンストリーム システムに複製されます。
TiCDC は、MySQL、TiDB、および Kafka データベースへのデータの複製をサポートしています。前の図は、changefeed レベルでのデータ転送のプロセスのみを示しています。次のセクションでは、TiCDC がデータを処理する方法について詳しく説明します。例として、テーブルtable1をレプリケートする Task1 を使用します。
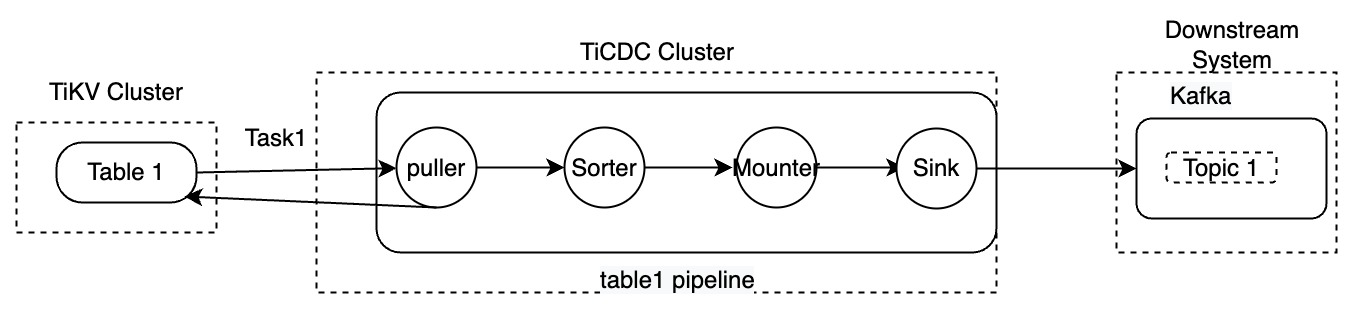
- データのプッシュ: データの変更が発生すると、TiKV はデータを Puller モジュールにプッシュします。
- 増分データのスキャン: Puller モジュールは、受信したデータの変更が連続していないことを検出すると、TiKV からデータをプルします。
- データの並べ替え: Sorter モジュールは、タイムスタンプに基づいて TiKV から受信したデータを並べ替え、並べ替えられたデータを Mounter モジュールに送信します。
- データのマウント: データの変更を受け取った後、Mounter モジュールは TiCDC シンクが理解できる形式でデータをロードします。
- データのレプリケート: シンク モジュールは、データの変更をダウンストリームにレプリケートします。
TiCDC のアップストリームは、トランザクションをサポートする分散リレーショナル データベース TiDB です。 TiCDC がデータをレプリケートする場合、複数のテーブルをレプリケートするときにデータとトランザクションの一貫性を確保する必要がありますが、これは大きな課題です。次のセクションでは、この課題に対処するために TiCDC が使用する主要なテクノロジと概念を紹介します。
TiCDCのキーコンセプト
ダウンストリームのリレーショナル データベースの場合、TiCDC は、単一のテーブルでのトランザクションの一貫性と、複数のテーブルでの最終的なトランザクションの一貫性を保証します。さらに、TiCDC は、アップストリームの TiDB クラスターで発生したすべてのデータ変更をダウンストリームに少なくとも 1 回レプリケートできるようにします。
アーキテクチャ関連の概念
- キャプチャ: TiCDC ノードを実行するプロセス。複数の Capture プロセスが TiCDC クラスターを構成します。各 Capture プロセスは、データ変更の受信とアクティブなプル、ダウンストリームへのデータの複製など、TiKV でのデータ変更の複製を担当します。
- Capture 所有者: 複数の Capture プロセスの所有者である Capture。一度に TiCDC クラスターに存在する所有者ロールは 1 つだけです。 Capture Owner は、クラスター内のデータのスケジューリングを担当します。
- プロセッサー: Capture 内の論理スレッド。各プロセッサは、同じレプリケーション ストリーム内の 1 つ以上のテーブルのデータを処理します。キャプチャ ノードは、複数のプロセッサを実行できます。
- Changefeed: 上流の TiDB クラスターから下流のシステムにデータをレプリケートするタスク。変更フィードには複数のタスクが含まれており、各タスクは Capture ノードによって処理されます。
タイムスタンプ関連の概念
TiCDC では、一連のタイムスタンプ (TS) を導入して、データ レプリケーションのステータスを示します。これらのタイムスタンプは、データが少なくとも 1 回ダウンストリームにレプリケートされ、データの一貫性が保証されるようにするために使用されます。
解決済みTS
このタイムスタンプは、TiKV と TiCDC の両方に存在します。
TiKV の ResolvedTS:リージョンリーダーで最も早いトランザクションの開始時刻を表します。つまり、
ResolvedTS= max(ResolvedTS, min(StartTS)) です。 TiDB クラスターには複数の TiKV ノードが含まれているため、すべての TiKV ノード上のリージョンリーダーの最小 ResolvedTS は、グローバル ResolvedTS と呼ばれます。 TiDB クラスターは、グローバルな ResolvedTS より前のすべてのトランザクションが確実にコミットされるようにします。または、このタイムスタンプより前にコミットされていないトランザクションはないと想定できます。TiCDC で解決された TS:
- table ResolvedTS: 各テーブルにはテーブル レベルの ResolvedTS があり、Resolved TS より小さいテーブル内のすべてのデータ変更が受信されたことを示します。簡単にするために、このタイムスタンプは、TiKV ノード上のこのテーブルに対応するすべてのリージョンの ResolvedTS の最小値と同じです。
- global ResolvedTS: すべての TiCDC ノード上のすべてのプロセッサの最小 ResolvedTS。各 TiCDC ノードには 1 つ以上のプロセッサがあるため、各プロセッサは複数のテーブル パイプラインに対応します。
TiCDC の場合、TiKV によって送信される ResolvedTS は
<resolvedTS: timestamp>の形式の特別なイベントです。一般に、ResolvedTS は次の制約を満たします。table ResolvedTS >= global ResolvedTS
チェックポイントTS
このタイムスタンプは TiCDC にのみ存在します。これは、このタイムスタンプより前に発生したデータ変更がダウンストリーム システムに複製されたことを意味します。
- table CheckpointTS: TiCDC はテーブル内のデータをレプリケートするため、テーブル checkpointTS は、CheckpointTS がテーブル レベルでレプリケートされる前に発生したすべてのデータ変更を示します。
- processor CheckpointTS: プロセッサ上の最小テーブル CheckpointTS を示します。
- global CheckpointTS: すべてのプロセッサの中で最小の CheckpointTS を示します。
通常、checkpointTS は次の制約を満たします。
table CheckpointTS >= global CheckpointTS
TiCDC はグローバル ResolvedTS より小さいデータのみをダウンストリームに複製するため、完全な制約は次のようになります。
table ResolvedTS >= global ResolvedTS >= table CheckpointTS >= global CheckpointTS
データの変更とトランザクションがコミットされた後、TiKV ノードの ResolvedTS は続行し、TiCDC ノードの Puller モジュールは TiKV によってプッシュされたデータを受信し続けます。 Puller モジュールは、受信したデータ変更に基づいて増分データをスキャンするかどうかも決定します。これにより、すべてのデータ変更が TiCDC ノードに確実に送信されます。
ソーター モジュールは、プラー モジュールが受信したデータをタイムスタンプに従って昇順に並べ替えます。このプロセスにより、テーブル レベルでのデータの一貫性が保証されます。次に、Mounter モジュールは、上流からのデータ変更を Sink モジュールが使用できる形式にアセンブルし、Sink モジュールに送信します。 Sink モジュールは、タイムスタンプの順序で CheckpointTS と ResolvedTS の間のデータ変更をダウンストリームに複製し、ダウンストリームがデータ変更を受信した後に checkpointTS を進めます。
前のセクションでは、DML ステートメントのデータ変更のみを取り上げており、DDL ステートメントは含まれていません。次のセクションでは、DDL ステートメントに関連するタイムスタンプを紹介します。
バリアTS
バリア TS は、DDL 変更イベントがあるか、同期点が使用されている場合に生成されます。
- DDL 変更イベント: Barrier TS は、DDL ステートメントの前のすべての変更がダウンストリームに複製されることを保証します。この DDL ステートメントが実行されてレプリケートされた後、TiCDC は他のデータ変更のレプリケートを開始します。 DDL ステートメントは Capture Owner によって処理されるため、DDL ステートメントに対応する Barrier TS は所有者ノードによってのみ生成されます。
- 同期点: TiCDC の同期点機能を有効にすると、指定した
sync-point-intervalに従って、TiCDC によってバリア TS が生成されます。この Barrier TS がレプリケートされる前にすべてのテーブルが変更されると、TiCDC は現在のグローバル CheckpointTS をプライマリ TS としてダウンストリームの tsMap を記録するテーブルに挿入します。その後、TiCDC はデータのレプリケーションを続行します。
バリア TS が生成された後、TiCDC は、このバリア TS の前に発生したデータ変更のみがダウンストリームに複製されることを保証します。これらのデータ変更がダウンストリームにレプリケートされる前に、レプリケーション タスクは続行されません。所有者の TiCDC は、グローバル CheckpointTS と Barrier TS を継続的に比較することにより、すべてのターゲット データが複製されたかどうかを確認します。グローバル CheckpointTS が Barrier TS と等しい場合、TiCDC は、指定された操作 (DDL ステートメントの実行やグローバル CheckpointTS ダウンストリームの記録など) を実行した後、レプリケーションを続行します。それ以外の場合、TiCDC は、バリア TS がダウンストリームに複製される前に発生するすべてのデータ変更を待機します。
主な工程
このセクションでは、TiCDC の主要なプロセスについて説明し、その動作原理をよりよく理解できるようにします。
次のプロセスは TiCDC 内でのみ発生し、ユーザーに対して透過的であることに注意してください。したがって、起動する TiCDC ノードを気にする必要はありません。
TiCDCを開始
所有者ではない TiCDC ノードの場合、次のように機能します。
- キャプチャ プロセスを開始します。
- プロセッサを起動します。
- 所有者によって実行されたタスク スケジューリング コマンドを受け取ります。
- スケジューリング コマンドに従って、tablePipeline を開始または停止します。
所有者の TiCDC ノードの場合、次のように機能します。
- キャプチャ プロセスを開始します。
- ノードが所有者として選出され、対応するスレッドが開始されます。
- changefeed 情報を読み取ります。
- changefeed 管理プロセスを開始します。
- changefeed 構成と最新の CheckpointTS に従って、TiKV のスキーマ情報を読み取り、複製するテーブルを決定します。
- 各プロセッサによって現在レプリケートされているテーブルのリストを読み取り、追加するテーブルを配布します。
- レプリケーションの進行状況を更新します。
TiCDC を停止
通常、TiCDC ノードをアップグレードしたり、計画的なメンテナンス操作を実行したりする必要がある場合は、TiCDC ノードを停止します。 TiCDC ノードを停止するプロセスは次のとおりです。
- ノードは、自身を停止するコマンドを受け取ります。
- ノードは、そのサービス ステータスを使用不可に設定します。
- ノードは新しいレプリケーション タスクの受信を停止します。
- ノードは、所有者ノードに、そのデータ レプリケーション タスクを他のノードに転送するように通知します。
- レプリケーション タスクが他のノードに転送された後、ノードは停止します。