パフォーマンス分析とチューニング
このドキュメントでは、データベース時間によるチューニング アプローチについて説明し、TiDB パフォーマンス概要ダッシュボードを使用してパフォーマンス分析とチューニングを行う方法を示します。
このドキュメントで説明する方法を使用すると、グローバルおよびトップダウンの観点からユーザー応答時間とデータベース時間を分析して、ユーザー応答時間のボトルネックがデータベースの問題によって引き起こされているかどうかを確認できます。ボトルネックがデータベースにある場合は、データベース時間の概要と SQLレイテンシーの内訳を使用して、ボトルネックを特定し、パフォーマンスを調整できます。
データベース時間に基づくパフォーマンス チューニング
TiDB は、SQL 処理パスとデータベース時間を常に測定および収集しています。したがって、TiDB でのデータベース パフォーマンスのボトルネックを特定するのは簡単です。データベース時間メトリックに基づいて、ユーザー応答時間に関するデータがなくても、次の 2 つの目標を達成できます。
- トランザクション内の TiDB 接続のアイドル時間と SQL 処理の平均レイテンシーを比較して、ボトルネックが TiDB にあるかどうかを判断します。
- ボトルネックが TiDB にある場合は、データベース時間の概要、色ベースのパフォーマンス データ、主要なメトリック、リソース使用率、およびトップダウンのレイテンシーの内訳に基づいて、分散システム内の正確なモジュールをさらに特定します。
TiDB がボトルネックですか?
トランザクション内の TiDB 接続の平均アイドル時間が SQL 処理の平均レイテンシーよりも長い場合、データベースはアプリケーションのトランザクションレイテンシーの原因ではありません。データベース時間は、ユーザー応答時間のごく一部しか占めていません。これは、ボトルネックがデータベースの外にあることを示しています。
この場合、データベースの外部コンポーネントを確認してください。たとえば、アプリケーションサーバーに十分なハードウェア リソースがあるかどうか、およびアプリケーションからデータベースへのネットワークレイテンシーが過度に長いかどうかを判断します。
SQL 処理の平均レイテンシーが、トランザクション内の TiDB 接続の平均アイドル時間よりも長い場合、トランザクションのボトルネックは TiDB にあり、データベース時間はユーザー応答時間の大部分を占めています。
ボトルネックが TiDB にある場合、それを特定する方法は?
次の図は、典型的な SQL プロセスを示しています。ほとんどの SQL 処理パスが TiDB パフォーマンス メトリックでカバーされていることがわかります。データベース時間はさまざまな次元に分類され、それに応じて色が付けられます。ワークロードの特性をすばやく理解し、データベース内のボトルネックがあればそれをキャッチできます。
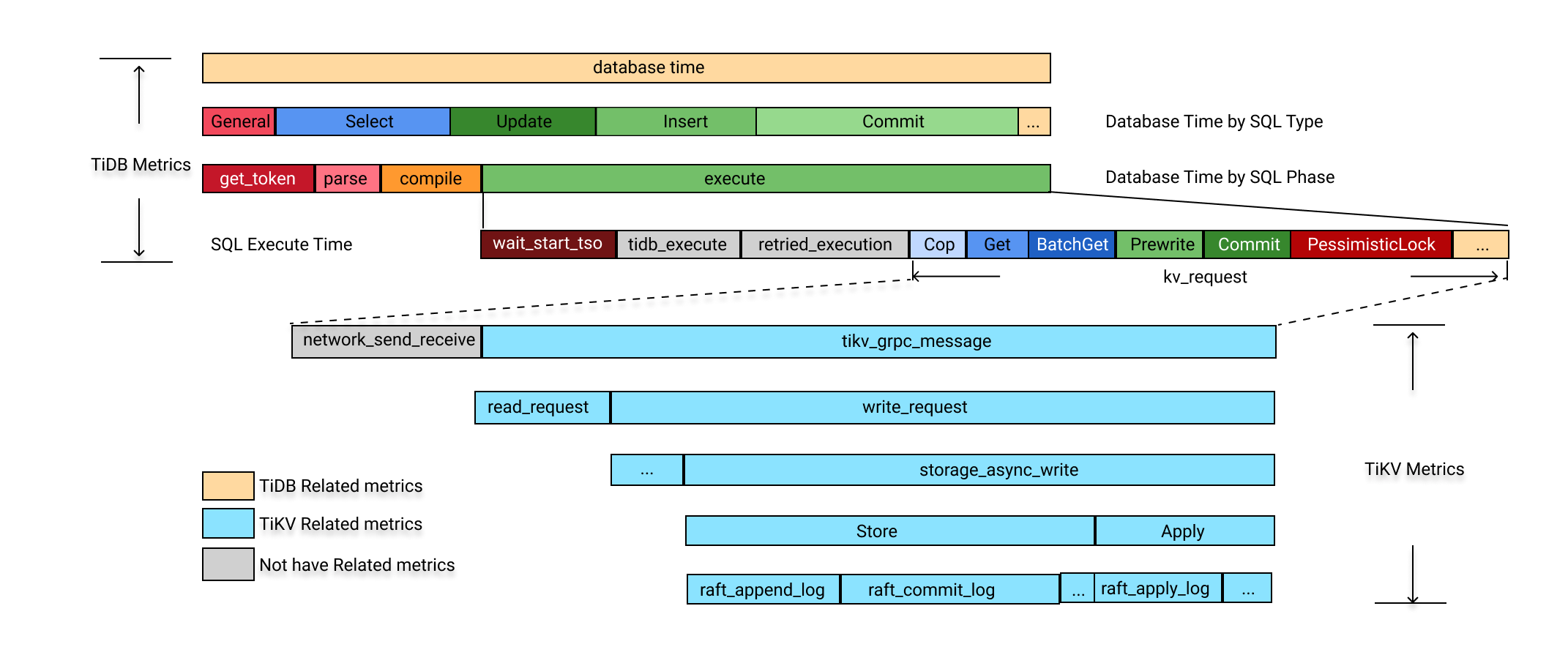
データベース時間は、すべての SQL 処理時間の合計です。データベース時間を次の 3 つの次元に分類すると、TiDB のボトルネックをすばやく特定するのに役立ちます。
SQL 処理タイプ別: どのタイプの SQL ステートメントが最もデータベース時間を消費しているかを判別します。式は次のとおりです。
DB Time = Select Time + Insert Time + Update Time + Delete Time + Commit Time + ...SQL 処理の 4 つのステップ (get_token/parse/compile/execute) によって、どのステップが最も時間を消費するかを判別します。式は次のとおりです。
DB Time = Get Token Time + Parse Time + Compile Time + Execute Timeエグゼキューター時間、TSO 待機時間、KV 要求時間、および実行再試行時間によって: どの実行ステップがボトルネックを構成しているかを判別します。式は次のとおりです。
Execute Time ~= TiDB Executor Time + KV Request Time + PD TSO Wait Time + Retried execution time
パフォーマンス概要ダッシュボードを使用したパフォーマンス分析とチューニング
このセクションでは、Grafana のパフォーマンス概要ダッシュボードを使用して、データベース時間に基づいてパフォーマンス分析とチューニングを実行する方法について説明します。
Performance Overview ダッシュボードは、TiDB、PD、および TiKV のメトリックを調整し、それぞれを次のセクションに示します。
- データベース時間と SQL 実行時間の概要: 色分けされた SQL の種類、SQL 実行フェーズごとのデータベース時間、およびさまざまな要求のデータベース時間により、データベースのワークロードの特性とパフォーマンスのボトルネックをすばやく特定できます。
- 主要なメトリックとリソース使用率: データベース QPS、接続情報、アプリケーションとデータベース間の要求コマンド タイプ、データベース内部 TSO および KV 要求 OPS、および TiDB/TiKV リソース使用率が含まれます。
- トップダウンレイテンシー内訳: クエリレイテンシーと接続アイドル時間の比較、クエリレイテンシーの内訳、SQL 実行における TSO リクエストと KV リクエストのレイテンシー、および TiKV 内部書き込みレイテンシーの内訳などを含みます。
データベース時間と SQL 実行時間の概要
データベース時間メトリックは、TiDB が 1 秒あたりに SQL を処理するレイテンシーの合計です。これは、TiDB が 1 秒あたりにアプリケーション SQL 要求を同時に処理する合計時間でもあります (アクティブな接続の数に等しい)。
Performance Overview ダッシュボードには、次の 3 つの積み上げ面グラフが表示されます。これらは、データベースのワークロード プロファイルを理解し、ステートメント、SQL フェーズ、および SQL 実行中の TiKV または PD リクエスト タイプに関してボトルネックの原因を迅速に特定するのに役立ちます。
- SQL タイプ別のデータベース時間
- SQLフェーズ別データベース時間
- SQL 実行時間の概要
色で調整
データベース時間の内訳と実行時間の概要の図は、予想される時間消費と予想外の時間消費の両方を直感的に示します。したがって、パフォーマンスのボトルネックをすばやく特定し、ワークロード プロファイルを学習できます。緑と青のエリアは、通常の消費時間とリクエストを表します。これらの 2 つの図で緑色または青色以外の領域がかなりの割合を占めている場合、データベースの時間分布は不適切です。
SQL タイプ別のデータベース時間:
- 青:
Selectのステートメント - 緑:
Update、Insert、Commitおよびその他の DML ステートメント - 赤:
StmtPrepare、StmtReset、StmtFetch、およびStmtCloseを含む一般的な SQL タイプ
- 青:
SQL フェーズ別のデータベース時間: 一般的に、SQL 実行フェーズは緑色で、その他のフェーズは赤色で表示されます。緑以外の領域が大きい場合は、実行フェーズ以外のフェーズで多くのデータベース時間が費やされていることを意味し、さらなる原因分析が必要です。一般的なシナリオは、準備されたプラン キャッシュが利用できないために、オレンジ色で示されたコンパイル フェーズが大きな領域を占有することです。
SQL 実行時間の概要: 緑色のメトリックは一般的な KV 書き込み要求 (
PrewriteやCommitなど) を表し、青色のメトリックは一般的な KV 読み取り要求 (Cop や Get など) を表し、他の色のメトリックは、必要な予期しない状況を表します。注意を払う。たとえば、悲観的ロック KV 要求は赤でマークされ、TSO 待機は濃い茶色でマークされます。青または緑以外の領域が大きい場合は、SQL 実行中にボトルネックがあることを意味します。例えば:- 重大なロック競合が発生した場合、赤い領域が大きな割合を占めます。
- TSO の待機に過度の時間が費やされると、こげ茶色の領域が大きな割合を占めます。
例 1: TPC-C ワークロード

SQL タイプ別のデータベース時間: 最も時間がかかるステートメントは、
commit、update、select、およびinsertステートメントです。SQL フェーズごとのデータベース時間: 最も時間がかかるフェーズは、緑の SQL 実行です。
SQL 実行時間の概要: SQL 実行で最も時間がかかる KV 要求は、緑色の
PrewriteとCommitです。ノート:
KV 要求の合計時間が実行時間よりも長くなるのは正常です。 TiDB executor が KV リクエストを複数の TiKV に同時に送信する可能性があるため、KV リクエストの合計待機時間が実行時間よりも長くなります。前述の TPC-C ワークロードでは、トランザクションがコミットされると、TiDB は
PrewriteつとCommitのリクエストを複数の TiKV に同時に送信します。したがって、この例のPrewrite、Commit、およびPessimisticsLockリクエストの合計時間は、実行時間よりも明らかに長くなります。execute時間は、KV 要求の合計時間にtso_wait時間を加えた時間よりも大幅に長くなる場合もあります。これは、SQL 実行時間のほとんどが TiDB executor 内で費やされることを意味します。次に、2 つの一般的な例を示します。
> - Example 1: After TiDB executor reads a large amount of data from TiKV, it needs to do complex join and aggregation inside TiDB, which consumes a lot of time.> - Example 2: The application experiences serious write statement lock conflicts. Frequent lock retries result in long `Retried execution time`.
例 2: OLTP 読み取り負荷の高いワークロード

- SQL タイプ別のデータベース時間: 時間のかかる主なステートメントは
SELECT、COMMIT、UPDATE、およびINSERTであり、そのうちSELECTが最も多くのデータベース時間を消費します。 - SQL フェーズごとのデータベース時間: ほとんどの時間は、緑の
executeフェーズで消費されます。 - SQL 実行時間の概要: SQL 実行フェーズでは、濃い茶色の
pd tso_wait、青色のKV Get、緑色のPrewriteとCommitが時間がかかります。
例 3: 読み取り専用の OLTP ワークロード

- SQL タイプ別のデータベース時間: 主に
SELECTのステートメントです。 - SQL フェーズごとのデータベース時間: 時間のかかる主要なフェーズは、オレンジ色の
compileと緑色のexecuteです。compileフェーズのレイテンシーが最も高く、TiDB が実行計画を生成するのに時間がかかりすぎており、その後のパフォーマンス データに基づいて根本原因をさらに特定する必要があることを示しています。 - SQL 実行時間の概要: 青色の KV BatchGet リクエストは、SQL 実行中に最も多くの時間を消費します。
ノート:
例 3 では、
SELECTのステートメントで複数の TiKV から同時に数千行を読み取る必要があります。したがって、BatchGetの要求の合計時間は、実行時間よりもはるかに長くなります。
例 4: ロック競合ワークロード

- SQL タイプ別のデータベース時間: 主に
UPDATEのステートメントです。 - SQL フェーズごとのデータベース時間: ほとんどの時間は実行フェーズで緑色で消費されます。
- SQL 実行時間の概要: 赤で示されている KV リクエスト PessimisticLock は、SQL 実行中に最も多くの時間を消費し、実行時間は KV リクエストの合計時間よりも明らかに長くなります。これは、書き込みステートメントでの重大なロック競合が原因で発生し、頻繁なロックの再試行が長引きます
Retried execution time。現在、TiDB はRetried execution timeを測定していません。
TiDB の主要なメトリックとクラスター リソースの使用率
1 秒あたりのクエリ、1 秒あたりのコマンド、Prepared-Plan-Cache
パフォーマンスの概要で次の 3 つのパネルを確認することで、アプリケーションのワークロードの種類、アプリケーションが TiDB と対話する方法、およびアプリケーションが TiDB 準備済みプラン キャッシュを十分に活用しているかどうかを知ることができます。
QPS: Query Per Second の略。アプリケーションによって実行された SQL ステートメントの数を示します。
タイプ別 CPS: Command Per Second の略。 Command は、MySQL プロトコル固有のコマンドを示します。クエリ ステートメントは、クエリ コマンドまたはプリペアドステートメントのいずれかによって TiDB に送信できます。
プラン キャッシュを使用したクエリ OPS: TiDB クラスターが準備されたプラン キャッシュにヒットした 1 秒あたりの数。準備済みプラン キャッシュは
prepared statementコマンドのみをサポートします。準備済みプラン キャッシュが TiDB で有効になっている場合、次の 3 つのシナリオが発生します。- 準備されたプラン キャッシュがヒットしません: 1 秒あたりのプラン キャッシュ ヒット数は 0 です。
- 準備されたすべてのプラン キャッシュがヒットする: 1 秒あたりのヒット数は、1 秒あたりの StmtExecute コマンドの数と同じです。
- 一部の準備済みプラン キャッシュがヒットしました: 1 秒あたりのヒット数は、1 秒あたりの StmtExecute コマンドの数よりも少なくなっています。準備済みプラン キャッシュには既知の制限があります。
例 1: TPC-C ワークロード
TPC-C ワークロードは、主にUPDATE 、 SELECT 、およびINSERTステートメントです。合計 QPS は 1 秒あたりの StmtExecute の数に等しく、後者は Plan Cache OPS を使用したクエリとほぼ同じです。理想的には、クライアントはプリペアドステートメントのオブジェクトをキャッシュします。このように、SQL ステートメントが実行されると、キャッシュされたステートメントが直接呼び出されます。すべての SQL 実行は準備されたプラン キャッシュにヒットし、実行プランを生成するために再コンパイルする必要はありません。

例 2: 読み取り専用の OLTP ワークロードでクエリ コマンドに使用できない準備済みプラン キャッシュ
このワークロードでは、 Commit QPS = Rollback QPS = Select QPSです。アプリケーションは自動コミット同時実行を有効にしており、接続が接続プールからフェッチされるたびにロールバックが実行されます。その結果、これら 3 つのステートメントは同じ回数実行されます。

- QPS パネルの赤い太線は失敗したクエリを表し、右側の Y 軸は失敗したクエリの数を示します。 0 以外の値は、失敗したクエリが存在することを意味します。
- 合計 QPS は、CPS By Type パネルのクエリ数と等しく、クエリ コマンドはアプリケーションによって使用されています。
- プラン キャッシュを使用したクエリ OPS パネルにはデータがありません。これは、準備されたプラン キャッシュがクエリ コマンドで使用できないためです。これは、TiDB がクエリ実行ごとに実行計画を解析して生成する必要があることを意味します。その結果、TiDB による CPU 消費の増加に伴い、コンパイル時間が長くなります。
例 3: 準備プリペアドステートメントが OLTP ワークロードに対して有効になっているため、準備済みプラン キャッシュを使用できない
StmtPreare回= StmtExecute回= StmtClose回~= StmtFetch回。アプリケーションは、準備 > 実行 > フェッチ > クローズ ループを使用します。プリペアドステートメントオブジェクトのリークを防ぐために、多くのアプリケーション フレームワークはexecuteフェーズの後にcloseを呼び出します。これにより、2 つの問題が生じます。
- SQL の実行には、4 つのコマンドと 4 つのネットワーク ラウンド トリップが必要です。
- プラン キャッシュを使用するクエリ OPS は 0 であり、準備されたプラン キャッシュのヒットがゼロであることを示します。
StmtCloseコマンドはデフォルトでキャッシュされた実行計画をクリアし、次のStmtPreareコマンドは実行計画を再度生成する必要があります。
ノート:
TiDB v6.0.0 以降では、グローバル変数 (
set global tidb_ignore_prepared_cache_close_stmt=on;) を介してStmtCloseコマンドがキャッシュされた実行プランをクリアするのを防ぐことができます。このようにして、後続の実行は、準備されたプラン キャッシュにヒットする可能性があります。

KV/TSO リクエスト OPS および接続情報
KV/TSO Request OPS パネルでは、1 秒あたりの KV および TSO 要求の統計を表示できます。統計の中で、 kv request totalは TiDB から TiKV へのすべてのリクエストの合計を表します。 TiDB から PD および TiKV へのリクエストのタイプを観察することで、クラスター内のワークロード プロファイルを把握できます。
[接続数] パネルでは、接続の総数と TiDB ごとの接続数を表示できます。このカウントは、合計接続数が正常であるか、TiDB ごとの接続数が偶数であるかを判断するのに役立ちます。 active connectionsは、1 秒あたりのデータベース時間に等しいアクティブな接続の数を記録します。
例 1: ビジー ワークロード

この TPC-C ワークロードでは:
- 1 秒あたりの KV リクエストの総数は 104,200 です。上位のリクエスト タイプは、リクエスト数の順に
PessimisticsLock、Prewrite、Commit、およびBatchGetです。 - 接続の総数は 810 で、3 つの TiDB インスタンスに均等に分散されています。アクティブな接続の数は 787.1 です。したがって、接続の 97% がアクティブであり、データベースがこのシステムのボトルネックであることを示しています。
例 2: アイドル ワークロード

このワークロードでは:
- 1 秒あたりの KV 要求の総数は 2600 で、1 秒あたりの TSO 要求の数は 1100 です。
- 接続の総数は 410 で、3 つの TiDB インスタンスに均等に分散されています。アクティブな接続の数はわずか 2.5 であり、データベース システムが比較的アイドル状態であることを示しています。
TiDB CPU、TiKV CPU、および IO 使用率
TiDB CPU および TiKV CPU/IO MBps パネルでは、TiDB および TiKV の論理 CPU 使用率と IO スループットを観察できます。これには、平均、最大、デルタ (最大 CPU 使用率から最小 CPU 使用率を差し引いたもの) が含まれます。 TiDB と TiKV の全体的な CPU 使用率。
deltaの値に基づいて、TiDB の CPU 使用率が不均衡であるかどうか (通常、アプリケーション接続の不均衡を伴う)、およびクラスター内に読み取り/書き込みのホット スポットがあるかどうかを判断できます。- TiDB と TiKV のリソース使用量の概要を使用すると、クラスターにリソースのボトルネックがあるかどうか、および TiKV または TiDB にスケールアウトが必要かどうかをすばやく判断できます。
例 1: TiDB リソースの使用率が高い
このワークロードでは、TiDB と TiKV はそれぞれ 8 個の CPU で構成されています。

- TiDB の平均、最大、デルタ CPU 使用率は、それぞれ 575%、643%、136% です。
- TiKV の平均、最大、デルタ CPU 使用率は、それぞれ 146%、215%、118% です。 TiKV の平均、最大、デルタ I/O スループットは、それぞれ 9.06 MB/秒、19.7 MB/秒、17.1 MB/秒です。
明らかに、TiDB はより多くの CPU を消費します。これは、ボトルネックのしきい値である 8 CPU に近づいています。 TiDB をスケールアウトすることをお勧めします。
例 2: TiKV リソースの使用率が高い
以下の TPC-C ワークロードでは、TiDB と TiKV はそれぞれ 16 個の CPU で構成されています。

- TiDB の平均、最大、デルタ CPU 使用率は、それぞれ 883%、962%、153% です。
- TiKV の平均、最大、デルタ CPU 使用率は、それぞれ 1288%、1360%、126% です。 TiKV の平均、最大、デルタ I/O スループットは、それぞれ 130 MB/秒、153 MB/秒、53.7 MB/秒です。
明らかに、TiKV はより多くの CPU を消費します。これは、TPC-C が書き込みの多いシナリオであるためです。パフォーマンスを向上させるために、TiKV をスケールアウトすることをお勧めします。
クエリレイテンシーの内訳と主要なレイテンシーメトリック
レイテンシーパネルには、平均値と 99 パーセンタイルが表示されます。平均値は全体的なボトルネックを特定するのに役立ちますが、99 パーセンタイルまたは 999 パーセンタイルまたは 999 番目の値は、重大なレイテンシージッターがあるかどうかを判断するのに役立ちます。
期間と接続アイドル期間
[期間] パネルには、すべてのステートメントの平均および P99レイテンシーと、各 SQL タイプの平均レイテンシーが含まれています。 Connection Idle Duration パネルには、平均および P99 接続アイドル時間が含まれています。接続のアイドル期間には、次の 2 つの状態が含まれます。
- in-txn: 接続がトランザクション内にある場合に、前の SQL を処理してから次の SQL ステートメントを受信するまでの間隔。
- not-in-txn: 接続がトランザクション内にない場合に、前の SQL を処理してから次の SQL ステートメントを受信するまでの間隔。
アプリケーションは、同じデータベース接続でトランザクションを実行します。クエリの平均レイテンシーと接続のアイドル時間を比較することで、TiDB がシステム全体のボトルネックになっているかどうか、またはユーザー応答時間のジッターが TiDB によって引き起こされているかどうかを判断できます。
- アプリケーションのワークロードが読み取り専用ではなく、トランザクションが含まれている場合、クエリの平均レイテンシーを
avg-in-txnと比較することで、データベース内外でトランザクションを処理する割合を判断し、ユーザー応答時間のボトルネックを特定できます。 - アプリケーションのワークロードが読み取り専用であるか、自動コミット モードがオンの場合、平均クエリレイテンシーを
avg-not-in-txnと比較できます。
実際の顧客のシナリオでは、ボトルネックがデータベースの外部にあることは珍しくありません。たとえば、次のようになります。
- クライアントサーバーの構成が低すぎて、CPU リソースが使い果たされています。
- HAProxy は TiDB クラスター プロキシとして使用され、HAProxy の CPU リソースが使い果たされます。
- HAProxy は TiDB クラスター プロキシとして使用され、ワークロードが高いと HAProxyサーバーのネットワーク帯域幅が使い果たされます。
- アプリケーションサーバーからデータベースへのネットワークレイテンシーが高い。たとえば、パブリック クラウドの展開では、アプリケーションと TiDB クラスターが同じリージョンにないか、dns ワークロード バランサーと TiDB クラスターが同じリージョンにないため、ネットワークレイテンシーが高くなります。
- ボトルネックはクライアント アプリケーションにあります。アプリケーション サーバーの CPU コアと Numa リソースを十分に活用できません。たとえば、TiDB への何千もの JDBC 接続を確立するために、1 つの JVM だけが使用されます。
例 1: TiDB がユーザー応答時間のボトルネックになっている

この TPC-C ワークロードでは:
- すべての SQL ステートメントの平均レイテンシーと P99レイテンシーは、それぞれ 477 us と 3.13 ms です。 commit ステートメント、insert ステートメント、query ステートメントの平均レイテンシは、それぞれ 2.02 ms、609 ms、468 us です。
- トランザクション
avg-in-txnの平均接続アイドル時間は 171 us です。
平均クエリレイテンシーはavg-in-txnを大幅に上回っています。これは、トランザクションの主なボトルネックがデータベース内にあることを意味します。
例 2: ユーザー応答時間のボトルネックは TiDB にはない

このワークロードでは、平均クエリレイテンシーは 1.69 ミリ秒で、 avg-in-txnは 18 ミリ秒です。これは、TiDB がトランザクションで SQL ステートメントを処理するために平均 1.69 ミリ秒を費やし、次のステートメントを受信するために 18 ミリ秒待機する必要があることを示しています。
クエリの平均レイテンシーはavg-in-txnよりも大幅に低くなっています。ユーザー応答時間のボトルネックは TiDB にはありません。この例はパブリック クラウド環境にあります。この環境では、アプリケーションとデータベースが同じリージョンにないため、アプリケーションとデータベース間のネットワークレイテンシー時間が長くなり、接続のアイドル時間が非常に長くなります。
解析、コンパイル、および実行時間
TiDB では、クエリ ステートメントを送信してから結果を返すまでが典型的な処理の流れです。
TiDB での SQL 処理は、 get token 、 parse 、 compile 、およびexecuteの 4 つのフェーズで構成されます。
get token: 通常は数マイクロ秒であり、無視できます。トークンは、1 つの TiDB インスタンスへの接続数がトークン制限の制限に達した場合にのみ制限されます。parse: クエリ ステートメントは抽象構文ツリー (AST) に解析されます。compile: 実行計画は、parseフェーズの AST と統計に基づいてコンパイルされます。compileフェーズには、論理最適化と物理最適化が含まれます。論理最適化は、関係代数に基づく列の刈り込みなどのルールによってクエリ プランを最適化します。物理的最適化は、コストベースのオプティマイザーによる統計によって実行計画のコストを見積もり、コストが最も低い物理的な実行計画を選択します。execute: SQL ステートメントの実行にかかる時間。 TiDB はまず、グローバルに一意のタイムスタンプ TSO を待ちます。次に、エグゼキュータは、実行計画のオペレータのキー範囲に基づいて TiKV API リクエストを構築し、それを TiKV に配布します。execute時間には、TSO 待機時間、KV 要求時間、および TiDB エグゼキューターがデータの処理に費やした時間が含まれます。
アプリケーションがqueryつまたはStmtExecuteの MySQL コマンド インターフェイスのみを使用する場合、次の式を使用して、平均レイテンシーのボトルネックを特定できます。
avg Query Duration = avg Get Token + avg Parse Duration + avg Compile Duration + avg Execute Duration
通常、 executeフェーズはqueryのレイテンシーの大部分を占めます。ただし、次の場合には、第parseフェーズとcompileフェーズも大きな役割を果たします。
parseフェーズのレイテンシーが長い: たとえば、queryステートメントが長い場合、SQL テキストを解析するために多くの CPU が消費されます。- 第
compileフェーズでの長いレイテンシー時間: 準備されたプラン キャッシュがヒットしない場合、TiDB は SQL 実行ごとに実行プランをコンパイルする必要があります。第compileフェーズのレイテンシーは、数ミリ秒または数十ミリ秒、あるいはそれ以上になる可能性があります。準備されたプラン キャッシュがヒットしない場合、compileフェーズで論理的および物理的な最適化が行われます。これは、多くの CPU とメモリを消費し、Go ランタイム (TiDB はGoで記述されます) を圧迫し、他の TiDB コンポーネントのパフォーマンスに影響を与えます。準備されたプラン キャッシュは、TiDB で OLTP ワークロードを効率的に処理するために重要です。
例 1: compile段階でのデータベースのボトルネック

前の図では、 parse 、 compile 、およびexecuteフェーズの平均時間は、それぞれ 17.1 us、729 us、および 681 us です。アプリケーションはqueryコマンド インターフェイスを使用し、準備されたプラン キャッシュを使用できないため、 compileのレイテンシーは高くなります。
例 2: executeフェーズでのデータベースのボトルネック

この TPC-C ワークロードでは、 parse 、およびcompileフェーズの平均時間は、それぞれexecute us、38.1 us、および 12.8 ms です。 executeフェーズはqueryレイテンシーのボトルネックです。
KV および TSO 要求期間
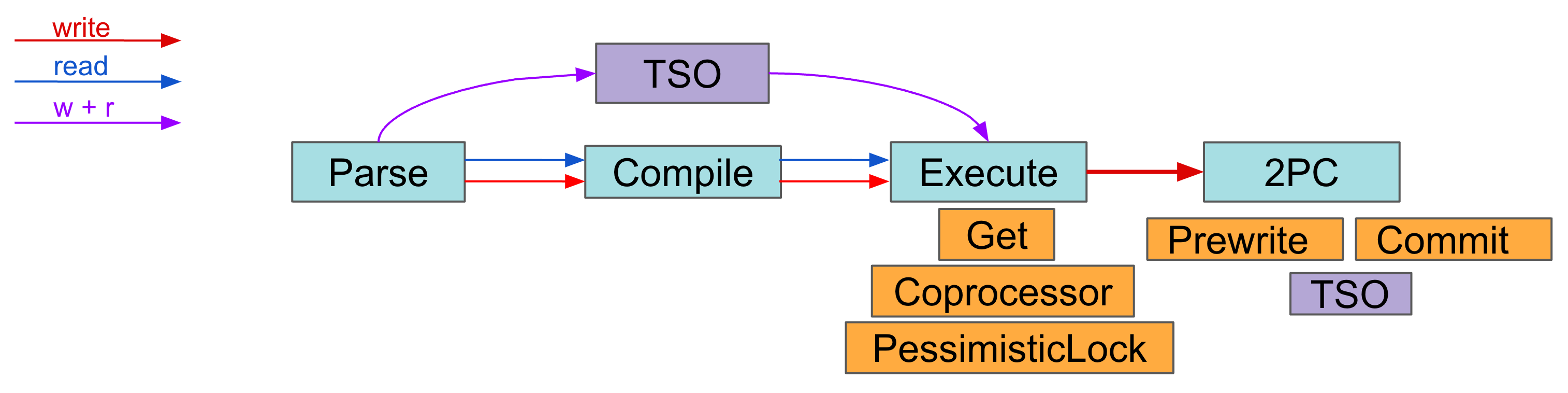
TiDB は、第executeフェーズで PD および TiKV と相互作用します。次の図に示すように、SQL 要求を処理する場合、TiDB はparseフェーズとcompileフェーズに入る前に TSO を要求します。 PD クライアントは呼び出し元をブロックしませんが、 TSFutureを返し、バックグラウンドで TSO 要求を非同期的に送受信します。 PD クライアントが TSO 要求の処理を完了すると、 TSFutureが返されます。 TSFutureの所有者は、Wait メソッドを呼び出して最終的な TSO を取得する必要があります。 TiDB がparseおよびcompileフェーズを終了すると、次の 2 つの状況が発生する可能性があるexecuteフェーズに入ります。
- TSO 要求が完了すると、Wait メソッドはすぐに使用可能な TSO またはエラーを返します。
- TSO 要求がまだ完了していない場合、TSO が使用可能になるかエラーが表示されるまで、Wait メソッドはブロックされます (gRPC 要求は送信されましたが、結果が返されず、ネットワークのレイテンシーが長くなります)。
TSO 待機時間はTSO WAITとして記録され、TSO 要求のネットワーク時間はTSO RPCとして記録されます。 TSO 待機が完了すると、TiDB エグゼキューターは通常、読み取りまたは書き込み要求を TiKV に送信します。
- 一般的な KV 読み取り要求:
Get、BatchGet、およびCop - 一般的な KV 書き込み要求: 2 フェーズ コミットの場合は
PessimisticLock、PrewriteおよびCommit
このセクションのインジケーターは、次の 3 つのパネルに対応しています。
- Avg TiDB KV Request Duration: TiDB によって測定された KV リクエストの平均レイテンシー
- Avg TiKV GRPC Duration: TiKV で gPRC メッセージを処理する際の平均レイテンシー
- PD TSO 待機/RPC 期間: TiDB エグゼキューター TSO 待機時間と TSO 要求 (RPC) のネットワークレイテンシー
Avg TiDB KV Request DurationとAvg TiKV GRPC Durationの関係は次のとおりです。
Avg TiDB KV Request Duration = Avg TiKV GRPC Duration + Network latency between TiDB and TiKV + TiKV gRPC processing time + TiDB gRPC processing time and scheduling latency
Avg TiDB KV Request DurationとAvg TiKV GRPC Durationの違いは、ネットワーク トラフィック、ネットワークレイテンシー、および TiDB と TiKV によるリソースの使用に密接に関連しています。
- 同じデータセンター内: 通常、差は 2 ミリ秒未満です。
- 同じリージョン内の異なるアベイラビリティ ゾーン: 通常、差は 5 ミリ秒未満です。
例 1: 同じデータセンターにデプロイされたクラスターの低ワークロード

このワークロードでは、TiDB の平均Prewriteレイテンシーは 925 us で、TiKV 内の平均kv_prewrite処理レイテンシーは 720 us です。その差は約 200 us で、これは同じデータセンターでは正常です。平均 TSOレイテンシーは 206 us で、RPC 時間は 144 us です。
例 2: パブリック クラウド クラスターでの通常のワークロード

この例では、TiDB クラスターは同じリージョン内の異なるデータ センターにデプロイされています。 TiDB の平均commitレイテンシーは 12.7 ミリ秒、TiKV 内部の平均kv_commit処理レイテンシーは 10.2 ミリ秒で、約 2.5 ミリ秒の差があります。平均 TSO 待機レイテンシーは 3.12 ミリ秒で、RPC 時間は 693 ミリ秒です。
例 3: パブリック クラウド クラスターで過負荷になっているリソース

この例では、TiDB クラスターは同じリージョン内の異なるデータ センターにデプロイされており、TiDB ネットワークと CPU リソースは非常に過負荷になっています。 TiDB の平均BatchGetレイテンシーは 38.6 ミリ秒で、TiKV 内の平均kv_batch_get処理レイテンシーは 6.15 ミリ秒です。その差は 32 ミリ秒以上あり、通常の値よりもはるかに高くなっています。平均 TSO 待機レイテンシーは 9.45 ミリ秒で、RPC 時間は 14.3 ミリ秒です。
ストレージの非同期書き込み期間、保存期間、および適用期間
TiKV は、次の手順で書き込み要求を処理します。
scheduler workerは書き込み要求を処理し、トランザクションの整合性チェックを実行し、書き込み要求をキーと値のペアに変換してraftstoreモジュールに送信します。TiKV コンセンサス モジュール
raftstoreは、 Raftコンセンサス アルゴリズムを適用して、ストレージレイヤー(複数の TiKV で構成される) をフォールト トレラントにします。Raftstore は
StoreスレッドとApplyスレッドで構成されます。StoreスレッドはRaftメッセージと新しいproposalsを処理します。新しいproposalsを受信すると、リーダー ノードのStoreスレッドがローカルのRaft DB に書き込み、メッセージを複数のフォロワー ノードにコピーします。このproposalsがほとんどのインスタンスで正常に永続化されると、proposalsが正常にコミットされます。Applyスレッドは、コミットされたproposalsを KV DB に書き込みます。コンテンツが KV DB に正常に書き込まれると、Applyスレッドは書き込み要求が完了したことを外部に通知します。
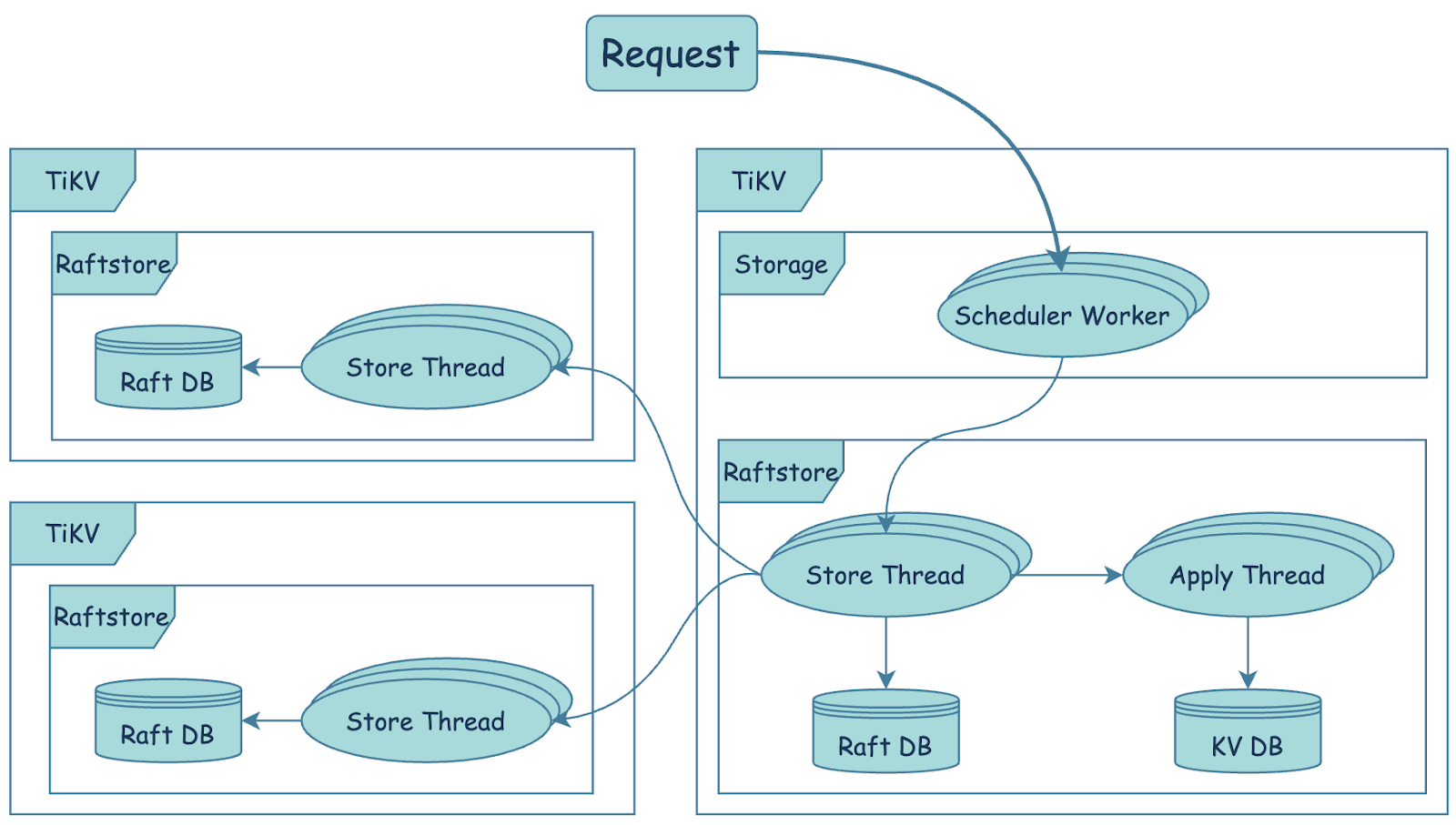
Storage Async Write Durationメトリクスは、書き込みリクエストが raftstore に入った後のレイテンシーを記録します。データはリクエストごとに収集されます。
Storage Async Write DurationメトリックにはStore DurationとApply Durationの 2 つの部分が含まれます。次の式を使用して、書き込み要求のボトルネックがStoreまたはApply番目のステップにあるかどうかを判断できます。
avg Storage Async Write Duration = avg Store Duration + avg Apply Duration
ノート:
Store DurationとApply Durationは v5.3.0 以降でサポートされています。
例 1: v5.3.0 と v5.4.0 での同じ OLTP ワークロードの比較
前の式によると、v5.4.0 の書き込みが多い OLTP ワークロードの QPS は、v5.3.0 よりも 14% 高くなります。
- v5.3.0: 24.4 ミリ秒 ~= 17.7 ミリ秒 + 6.59 ミリ秒
- v5.4.0: 21.4 ミリ秒 ~= 14.0 ミリ秒 + 7.33 ミリ秒
v5.4.0 では、gPRC モジュールがRaftログ レプリケーションを高速化するように最適化されており、v5.3.0 と比較してStore Duration減少しています。
v5.3.0:

v5.4.0:

例 2: 保存期間がボトルネック
前の式を適用します: 10.1 ミリ秒 ~= 9.81 ミリ秒 + 0.304 ミリ秒。この結果は、書き込みリクエストのレイテンシーのボトルネックがStore Durationであることを示しています。

コミット ログ期間、追加ログ期間、および適用ログ期間
Commit Log Duration 、 Append Log Duration 、およびApply Log Durationは、raftstore 内の主要な操作のレイテンシーメトリックです。これらのレイテンシーはバッチ操作レベルでキャプチャされ、各操作は複数の書き込み要求を組み合わせます。したがって、レイテンシは上記のStore DurationとApply Durationに直接対応しません。
Storeスレッドで実行された操作のCommit Log DurationおよびAppend Log Duration記録時間。Commit Log Durationには、 Raftログを他の TiKV ノードにコピーする時間が含まれています (raft-log の永続性を確保するため)。Commit Log Durationには通常、リーダー用とフォロワー用の 2 つのAppend Log Duration操作が含まれます。Commit Log Durationは通常Append Log Durationよりも大幅に高くなります。これは、前者にはRaftログをネットワーク経由で他の TiKV ノードにコピーする時間が含まれているためです。Apply Log Durationは、ApplyのスレッドによるapplyのRaftログのレイテンシーを記録します。
Commit Log Durationが長い一般的なシナリオ:
- TiKV の CPU リソースにボトルネックがあり、スケジューリングのレイテンシーが高い
raftstore.store-pool-sizeは小さすぎるか大きすぎる (大きすぎる値もパフォーマンスの低下を引き起こす可能性があります)- I/Oレイテンシーが高いため、
Append Log Durationレイテンシーが高くなります - TiKV ノード間のネットワークレイテンシーが大きい
- gRPC スレッドの数が少なすぎます。CPU 使用率は GRPC スレッド間で不均一です。
Apply Log Durationが長い一般的なシナリオ:
- TiKV の CPU リソースにボトルネックがあり、スケジューリングのレイテンシーが高い
raftstore.apply-pool-sizeは小さすぎるか大きすぎる (大きすぎる値もパフォーマンスの低下を引き起こす可能性があります)- I/Oレイテンシーが高い
例 1: v5.3.0 と v5.4.0 での同じ OLTP ワークロードの比較
v5.4.0 の書き込み負荷の高い OLTP ワークロードの QPS は、v5.3.0 と比較して 14% 向上しています。次の表は、3 つの主要なレイテンシを比較したものです。
| 平均継続時間 | v5.3.0 (ミリ秒) | v5.4.0 (ミリ秒) |
|---|---|---|
| ログ期間の追加 | 0.27 | 0.303 |
| コミット ログの期間 | 13 | 8.68 |
| ログ期間の適用 | 0.457 | 0.514 |
v5.4.0 では、gPRC モジュールがRaftログ レプリケーションを高速化するように最適化されており、v5.3.0 と比較してCommit Log DurationとStore Durationが減少しています。
v5.3.0:

v5.4.0:

例 2: コミット ログの期間がボトルネックである

- 平均
Append Log Duration= 4.38 ミリ秒 - 平均
Commit Log Duration= 7.92 ミリ秒 - 平均
Apply Log Duration= 172 us
Storeスレッドの場合、 Commit Log Durationは明らかにApply Log Durationよりも高くなります。一方、 Append Log DurationはApply Log Durationよりも大幅に高く、 Storeスレッドが CPU と I/O の両方でボトルネックに悩まされている可能性があることを示しています。 Commit Log DurationとAppend Log Durationを減らすには、次の方法が考えられます。
- TiKV CPU リソースが十分な場合は、
raftstore.store-pool-sizeの値を増やしてStoreスレッドを追加することを検討してください。 - TiDB が v5.4.0 以降の場合は、
raft-engine.enable: trueを設定してRaft Engineを有効にすることを検討してください。 Raft Engineには軽い実行パスがあります。これにより、一部のシナリオでは、I/O 書き込みと書き込みのロングテールレイテンシーを削減できます。 - TiKV の CPU リソースが十分にあり、TiDB が v5.3.0 以降の場合は、
raftstore.store-io-pool-size: 1を設定してStoreWriterを有効にすることを検討してください。
TiDB のバージョンが v6.1.0 より前の場合、Performance Overview ダッシュボードを使用するにはどうすればよいですか?
v6.1.0 以降、Grafana にはデフォルトでパフォーマンス概要ダッシュボードが組み込まれています。このダッシュボードは、TiDB v4.x および v5.x バージョンと互換性があります。 TiDB が v6.1.0 より前の場合は、次の図に示すように、手動でperformance_overview.jsonをインポートする必要があります。