OLTP シナリオの性能チューニングプラクティス
TiDB は、TiDB ダッシュボードのTop SQLと継続的なプロファイリングの機能、および TiDB パフォーマンス概要ダッシュボードなど、包括的なパフォーマンス診断および分析機能を提供します。
このドキュメントでは、これらの機能を一緒に使用して、7 つの異なるランタイム シナリオで同じ OLTP ワークロードのパフォーマンスを分析および比較する方法について説明します。これは、TiDB のパフォーマンスを効率的に分析および調整するのに役立つパフォーマンス調整プロセスを示しています。
ノート:
デフォルトでは、 Top SQLと継続的なプロファイリングは有効になっていません。事前に有効にする必要があります。
このドキュメントでは、これらのシナリオで異なる JDBC 構成を使用して同じアプリケーションを実行することにより、アプリケーションとデータベース間のさまざまな相互作用がシステム全体のパフォーマンスにどのように影響するかを示し、 TiDB で Java アプリケーションを開発するためのベスト プラクティスを適用してパフォーマンスを向上させることができます。
環境の説明
このドキュメントでは、デモンストレーションのためにコア バンキング OLTP ワークロードを使用します。シミュレーション環境の構成は次のとおりです。
- ワークロードのアプリケーション開発言語: JAVA
- ビジネスで使用するSQL文:合計200文、そのうち9割がSELECT文。これは典型的な読み取り負荷の高い OLTP ワークロードです。
- トランザクションで使用されるテーブル: 合計 60 テーブル。 12 個のテーブルには更新操作が含まれ、残りの 48 個のテーブルは読み取り専用です。
- アプリケーションが使用する分離レベル:
read committed。 - TiDB クラスター構成: 3 つの TiDB ノードと 3 つの TiKV ノードで、各ノードに 16 個の CPU が割り当てられます。
- クライアントサーバー構成: 36 個の CPU。
シナリオ 1. Query インターフェイスを使用する
アプリケーション構成
アプリケーションは、次の JDBC 構成を使用して、Query インターフェースを介してデータベースに接続します。
useServerPrepStmts=false
パフォーマンス分析
TiDB ダッシュボード
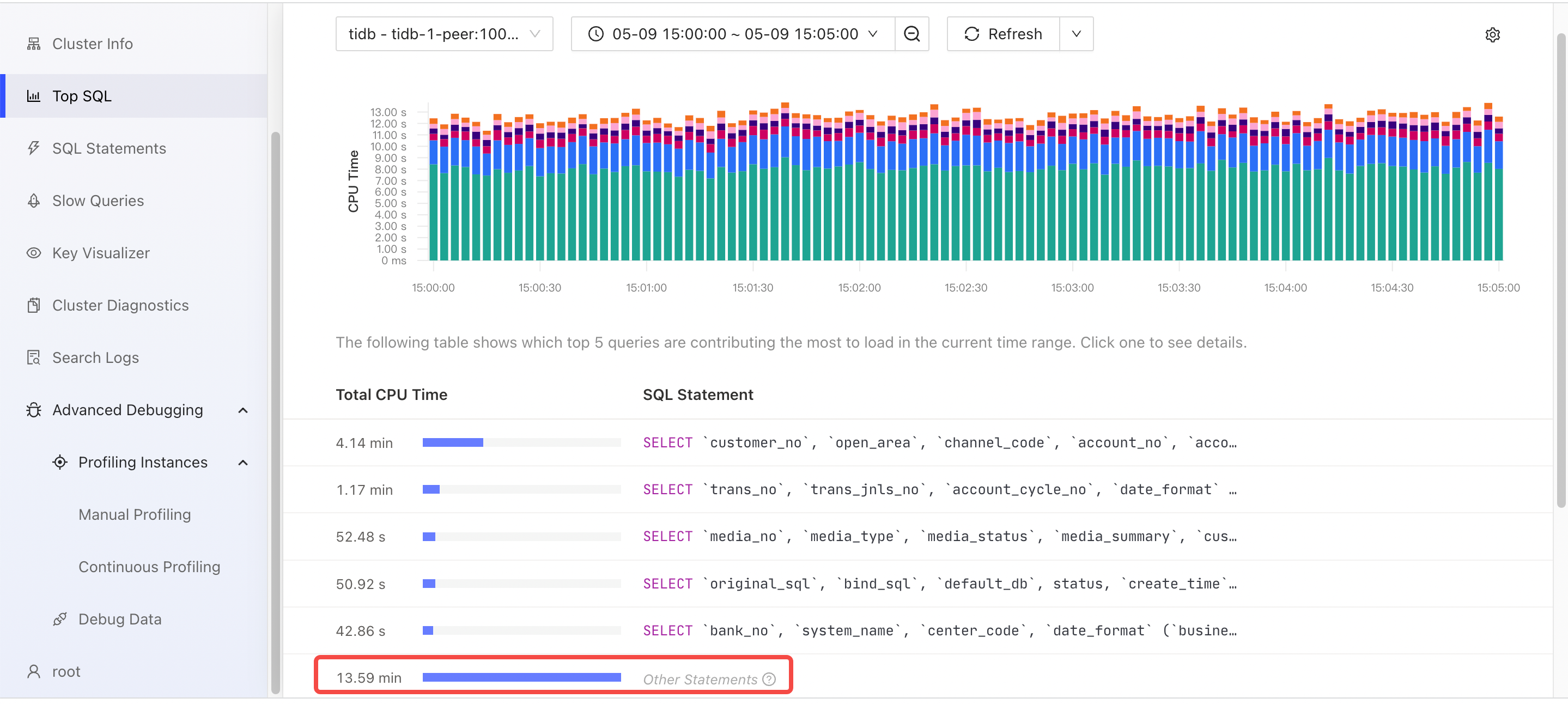
以下の TiDB ダッシュボードのTop SQLページから、非ビジネス SQL タイプSELECT @@session.tx_isolationが最も多くのリソースを消費していることがわかります。 TiDB はこれらのタイプの SQL ステートメントを迅速に処理しますが、これらのタイプの SQL ステートメントは実行回数が最も多く、全体的な CPU 時間の消費が最も高くなります。
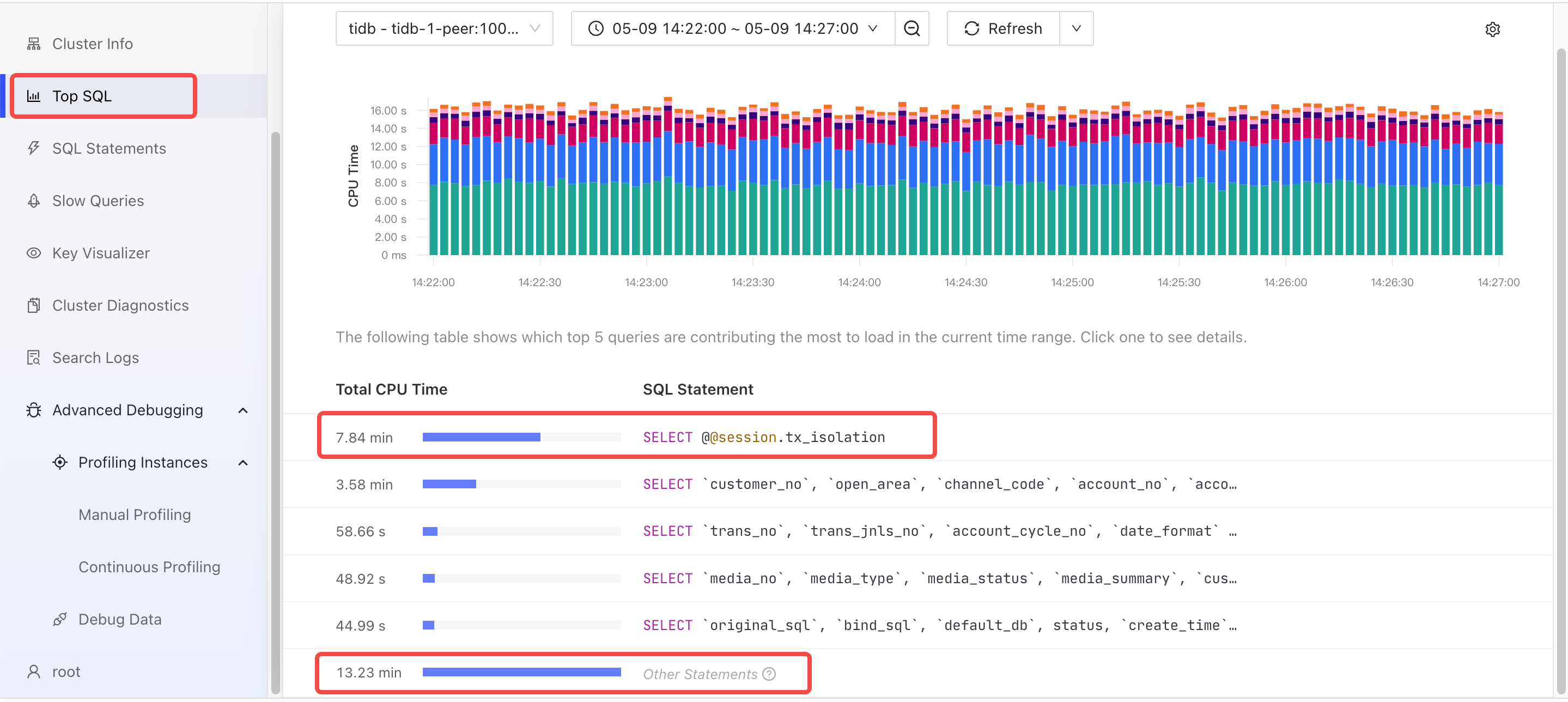
以下の TiDB のフレーム チャートから、SQL 実行時にCompileやOptimizeなどの関数の CPU 消費が顕著であることがわかります。アプリケーションは Query インターフェイスを使用するため、TiDB は実行計画キャッシュを使用できません。 TiDB は、SQL ステートメントごとに実行計画をコンパイルして生成する必要があります。
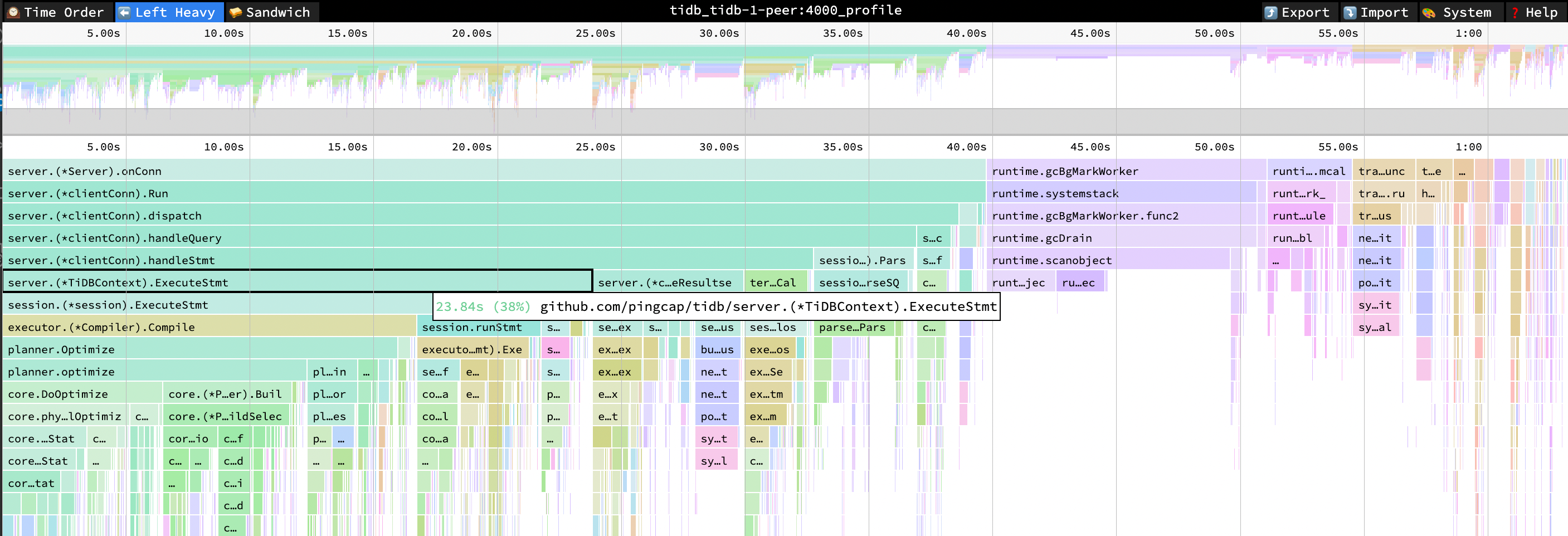
- ExecuteStmt CPU = 38% CPU 時間 = 23.84 秒
- コンパイル CPU = 27% CPU 時間 = 17.17 秒
- CPU の最適化 = 26% CPU 時間 = 16.41 秒
パフォーマンス概要ダッシュボード
次の Performance Overview ダッシュボードで、データベース時間の概要と QPS を確認します。
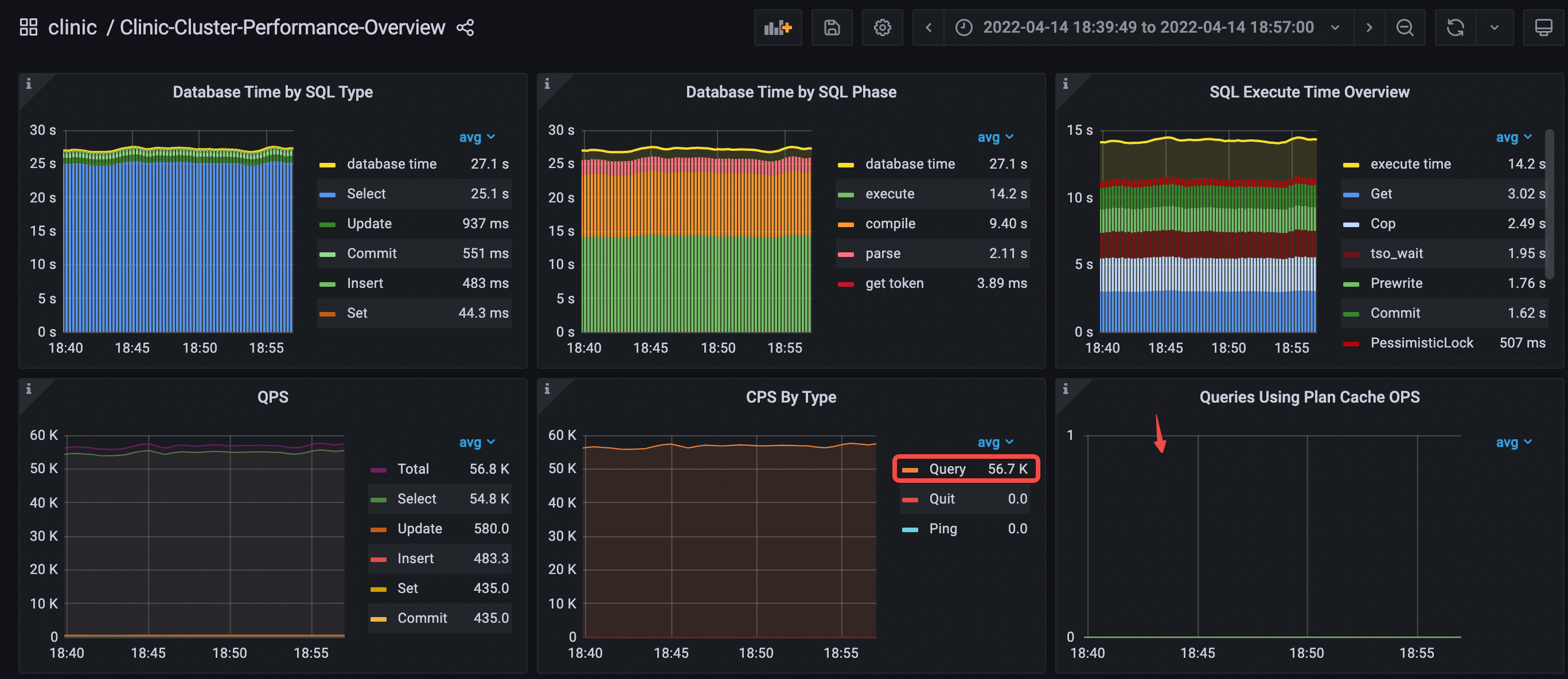
- SQL タイプ別のデータベース時間:
Selectステートメント タイプが最も時間がかかります。 - SQL フェーズごとのデータベース時間:
executeフェーズとcompileフェーズに最も時間がかかります。 - SQL 実行時間の概要:
Get、Cop、およびtso waitが最も時間がかかります。 - タイプ別 CPS:
Queryコマンドのみが使用されます。 - Plan Cache を使用したクエリ OPS: no data は、実行プラン キャッシュがヒットしていないことを示します。
- クエリ期間では、
executeとcompileのレイテンシーが最も高い割合を占めています。 - 平均 QPS = 56.8k
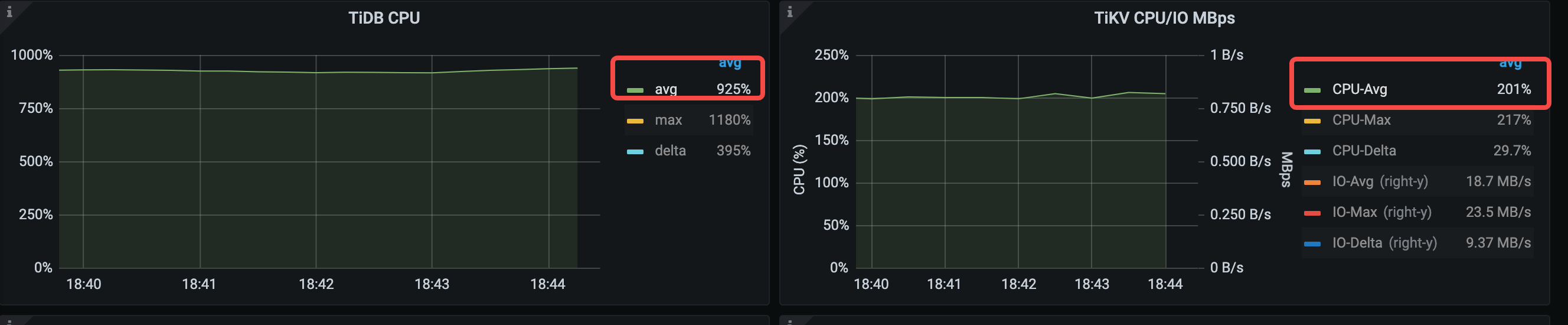
クラスターのリソース消費を確認します。TiDB CPU の平均使用率は 925%、TiKV CPU の平均使用率は 201%、TiKV IO の平均スループットは 18.7 MB/秒です。 TiDB のリソース消費は大幅に高くなります。
分析の結論
実行回数が多く、TiDB の CPU 使用率が高くなるこれらの無駄な非ビジネス SQL ステートメントを排除する必要があります。
シナリオ 2. maxPerformance 構成を使用する
アプリケーション構成
アプリケーションは、シナリオ 1 の JDBC 接続文字列に新しいパラメーターuseConfigs=maxPerformanceを追加します。このパラメーターを使用して、JDBC からデータベースに送信される SQL ステートメント (たとえば、 select @@session.transaction_read_only ) を排除できます。完全な構成は次のとおりです。
useServerPrepStmts=false&useConfigs=maxPerformance
パフォーマンス分析
TiDB ダッシュボード
以下の TiDB ダッシュボードのTop SQLページから、最も多くのリソースを消費したSELECT @@session.tx_isolationが消えていることがわかります。
以下の TiDB のフレーム チャートから、SQL 実行中のCompileやOptimizeなどの関数の CPU 消費が依然として大きいことがわかります。
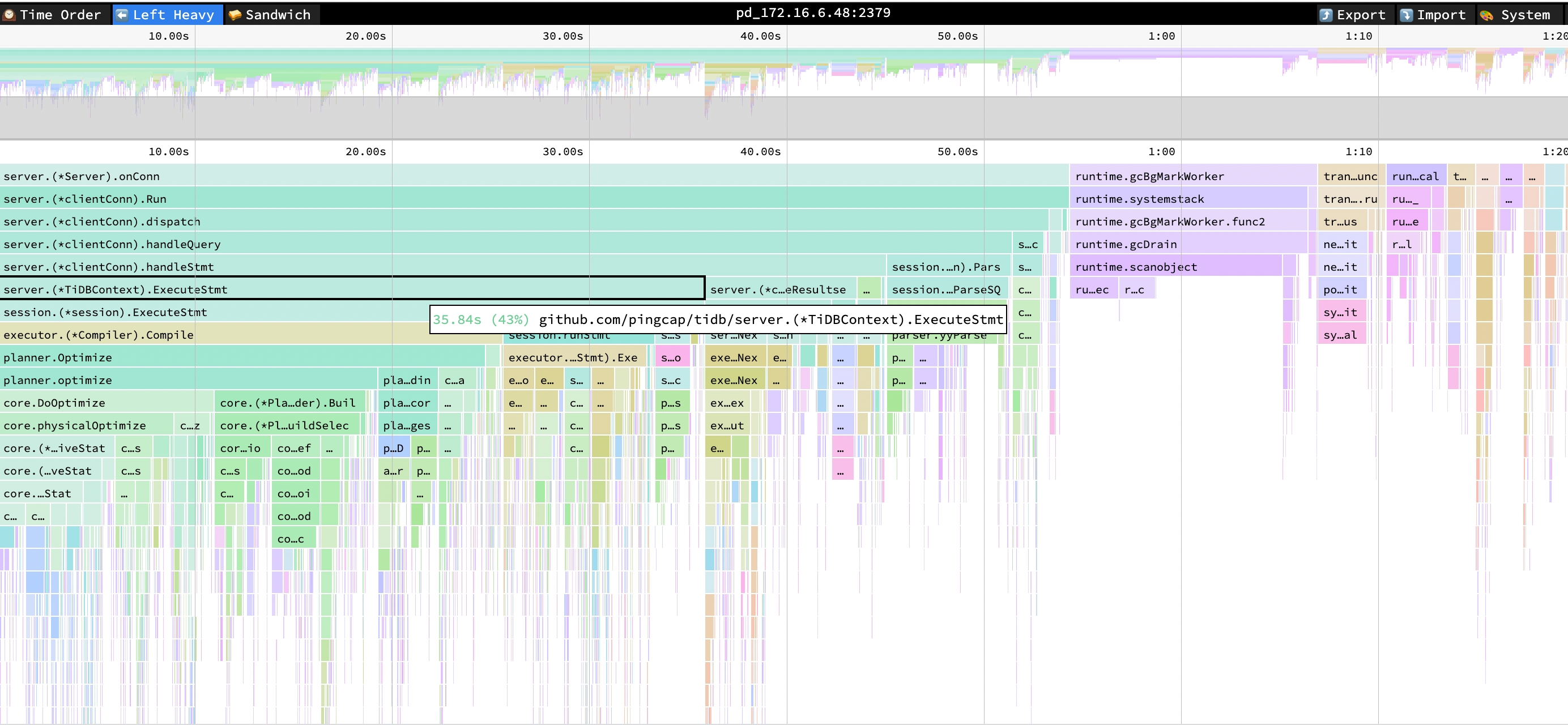
- ExecuteStmt CPU = 43% CPU 時間 = 35.84 秒
- コンパイル CPU = 31% CPU 時間 = 25.61 秒
- CPU の最適化 = 30% CPU 時間 = 24.74 秒
パフォーマンス概要ダッシュボード
データベース時間の概要と QPS のデータは次のとおりです。
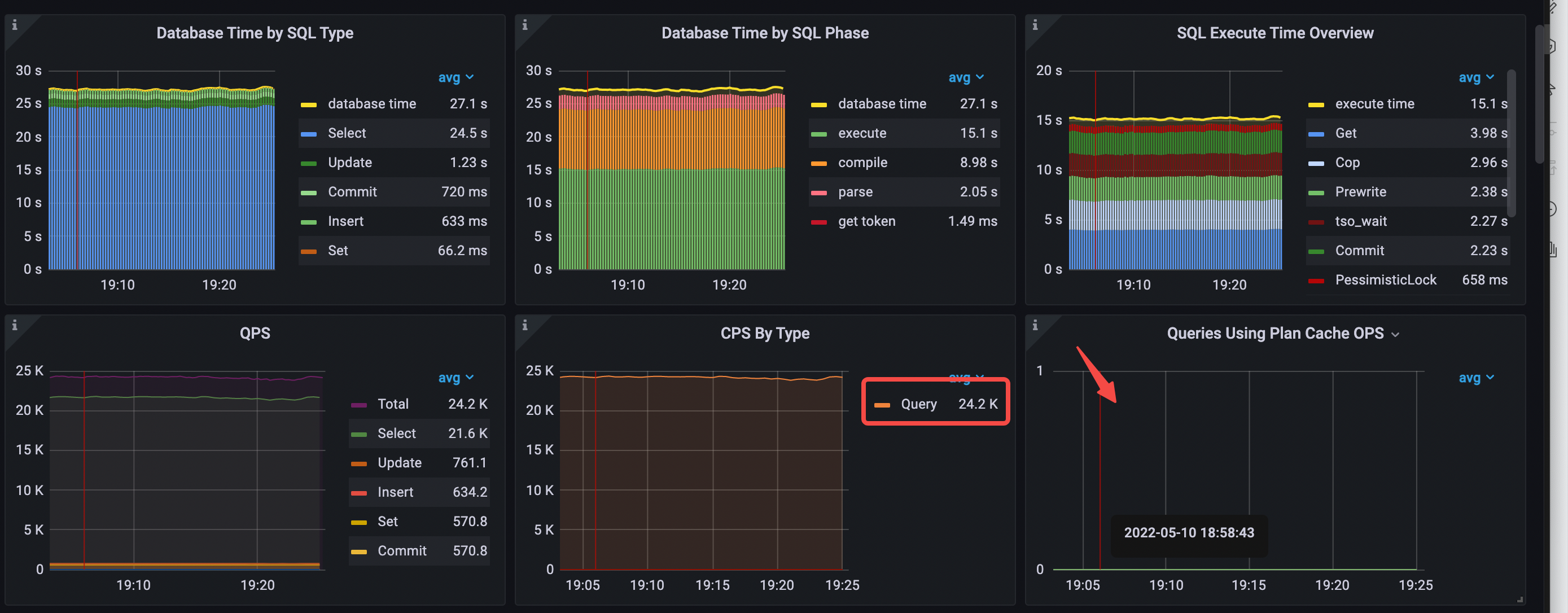
- SQL タイプ別のデータベース時間:
Selectステートメント タイプが最も時間がかかります。 - SQL フェーズごとのデータベース時間:
executeフェーズとcompileフェーズに最も時間がかかります。 - SQL 実行時間の概要:
Get、Cop、Prewrite、およびtso waitが最も時間がかかります。 - データベース時間では、
executeとcompileのレイテンシーが最も高い割合を占めています。 - タイプ別 CPS:
Queryコマンドのみが使用されます。 - 平均 QPS = 24.2k (56.3k から 24.2k へ)
- 実行計画のキャッシュはヒットしません。
シナリオ 1 からシナリオ 2 にかけて、平均 TiDB CPU 使用率は 925% から 874% に低下し、平均 TiKV CPU 使用率は 201% から約 250% に増加します。

主なレイテンシーメトリックの変更点は次のとおりです。
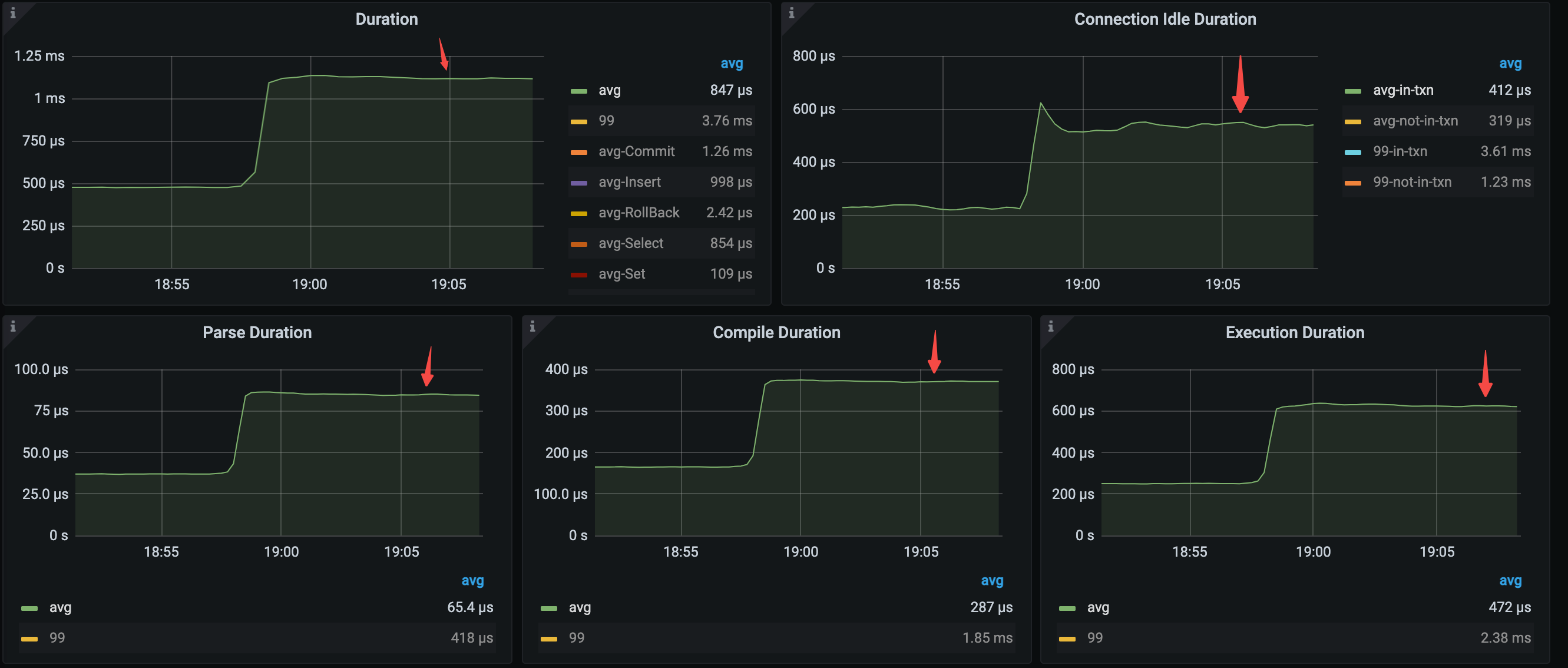
- 平均クエリ時間 = 1.12ms (479μs から 1.12ms まで)
- 平均解析時間 = 84.7μs (37.2μs から 84.7μs へ)
- 平均コンパイル時間 = 370μs (166μs から 370μs へ)
- 平均実行時間 = 626μs (251μs から 626μs へ)
分析の結論
シナリオ 1 と比較して、シナリオ 2 の QPS は大幅に減少しています。平均クエリ期間と平均parse 、 compile 、およびexecute期間が大幅に増加しました。これは、シナリオ 1 のselect @@session.transaction_read_onlyのように、実行回数が多く処理時間が速い SQL ステートメントが平均パフォーマンス データを下げるためです。シナリオ 2 がそのようなステートメントをブロックした後、ビジネス関連の SQL ステートメントのみが残るため、平均所要時間は長くなります。
アプリケーションが Query インターフェースを使用する場合、TiDB は実行計画キャッシュを使用できないため、TiDB は実行計画をコンパイルするために大量のリソースを消費します。この場合、TiDB の実行計画キャッシュを使用して、実行計画のコンパイルによる TiDB の CPU 消費を減らし、レイテンシーを短縮する Prepared Statement インターフェイスを使用することをお勧めします。
シナリオ 3. 実行計画のキャッシュを有効にせずに Prepared Statement インターフェイスを使用する
アプリケーション構成
アプリケーションは、次の接続構成を使用します。シナリオ 2 と比較すると、JDBC パラメータuseServerPrepStmtsの値がtrueに変更されており、Prepared Statement インターフェースが有効になっていることを示しています。
useServerPrepStmts=true&useConfigs=maxPerformance"
パフォーマンス分析
TiDB ダッシュボード
次の TiDB のフレーム チャートから、 CompileExecutePreparedStmtとOptimizeの CPU 消費は、Prepared Statement インターフェイスが有効になった後も依然として重要であることがわかります。
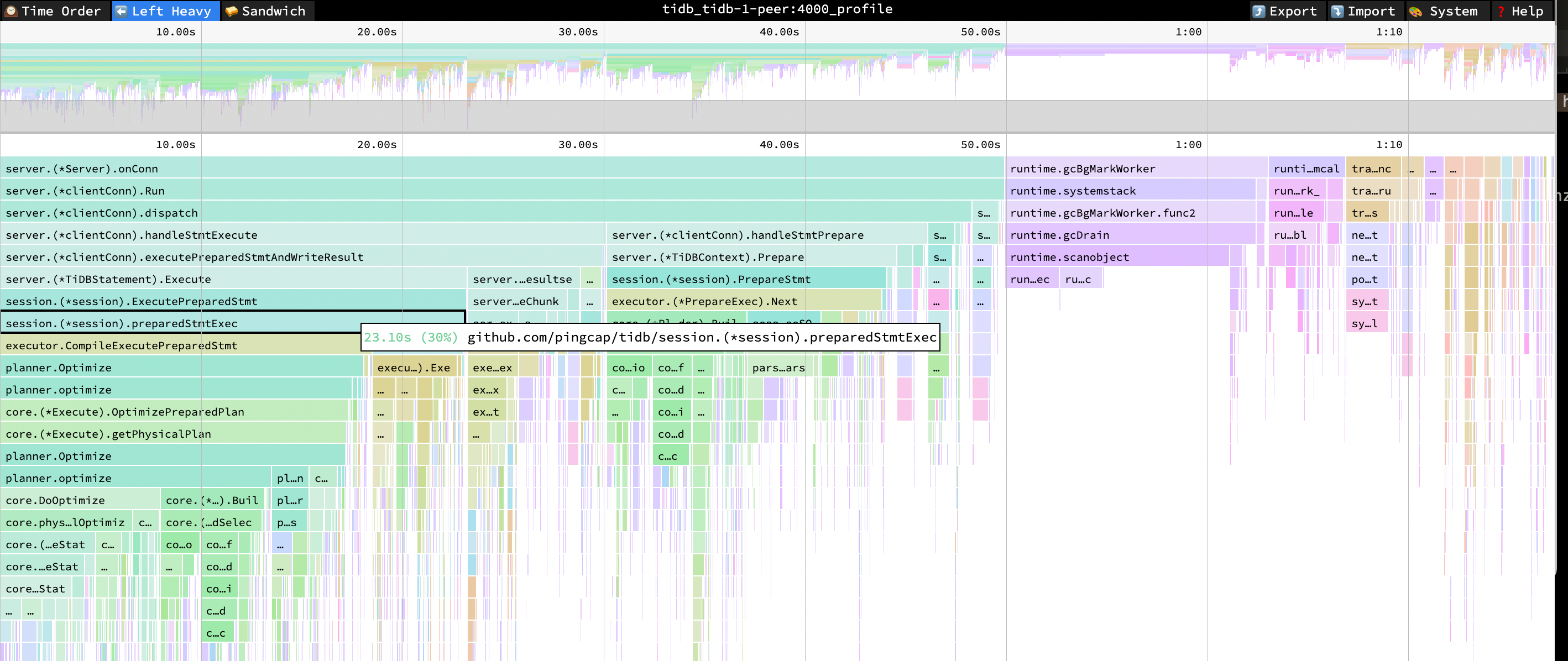
- ExecutePreparedStmt CPU = 31% CPU 時間 = 23.10 秒
- 準備されたStmtExec CPU = 30% CPU 時間 = 22.92 秒
- CompileExecutePreparedStmt CPU = 24% CPU 時間 = 17.83 秒
- CPU の最適化 = 23% CPU 時間 = 17.29 秒
パフォーマンス概要ダッシュボード
プリペアド ステートメント インターフェイスを使用した後、データベース時間の概要と QPS のデータは次のようになります。
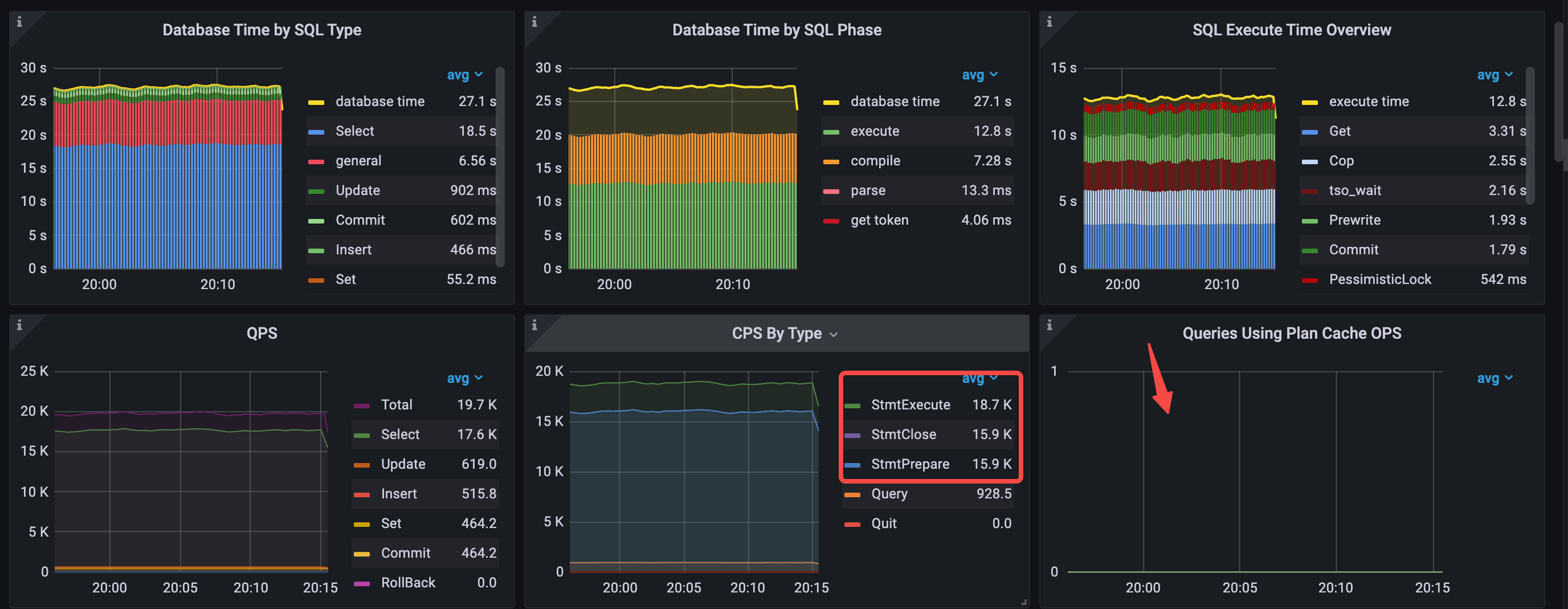
QPS は 24.4k から 19.7k に低下します。データベース時間の概要から、アプリケーションが 3 種類のプリペアド コマンドを使用していることがわかりますgeneralステートメント タイプ ( StmtPrepareやStmtCloseなどのコマンドの実行時間を含む) は、SQL タイプ別のデータベース時間で 2 位です。これは、Prepared Statement インターフェースを使用しても、実行プランのキャッシュにヒットしないことを示しています。その理由は、 StmtCloseコマンドが実行されると、TiDB が内部処理で SQL ステートメントの実行計画キャッシュをクリアするためです。
- SQL タイプ別のデータベース時間:
Selectのステートメント タイプに最も時間がかかり、その後にgeneralのステートメントが続きます。 - SQL フェーズごとのデータベース時間:
executeフェーズとcompileフェーズに最も時間がかかります。 - SQL 実行時間の概要:
Get、Cop、Prewrite、およびtso waitが最も時間がかかります。 - CPS By Type: 3 種類のコマンド (
StmtPrepare、StmtExecute、StmtClose) が使用されます。 - 平均 QPS = 19.7k (24.4k から 19.7k へ)
- 実行計画のキャッシュはヒットしません。
TiDB の平均 CPU 使用率は 874% から 936% に増加します。
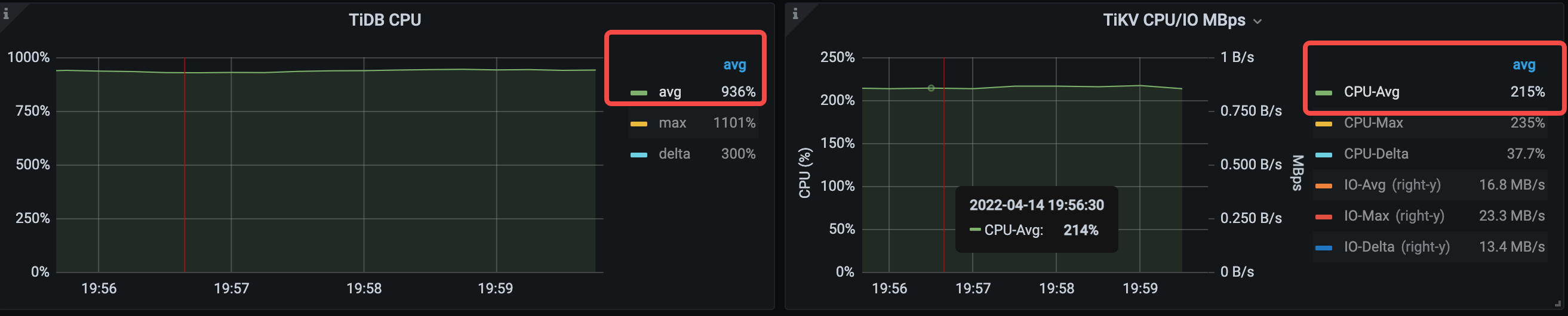
主なレイテンシーメトリックは次のとおりです。
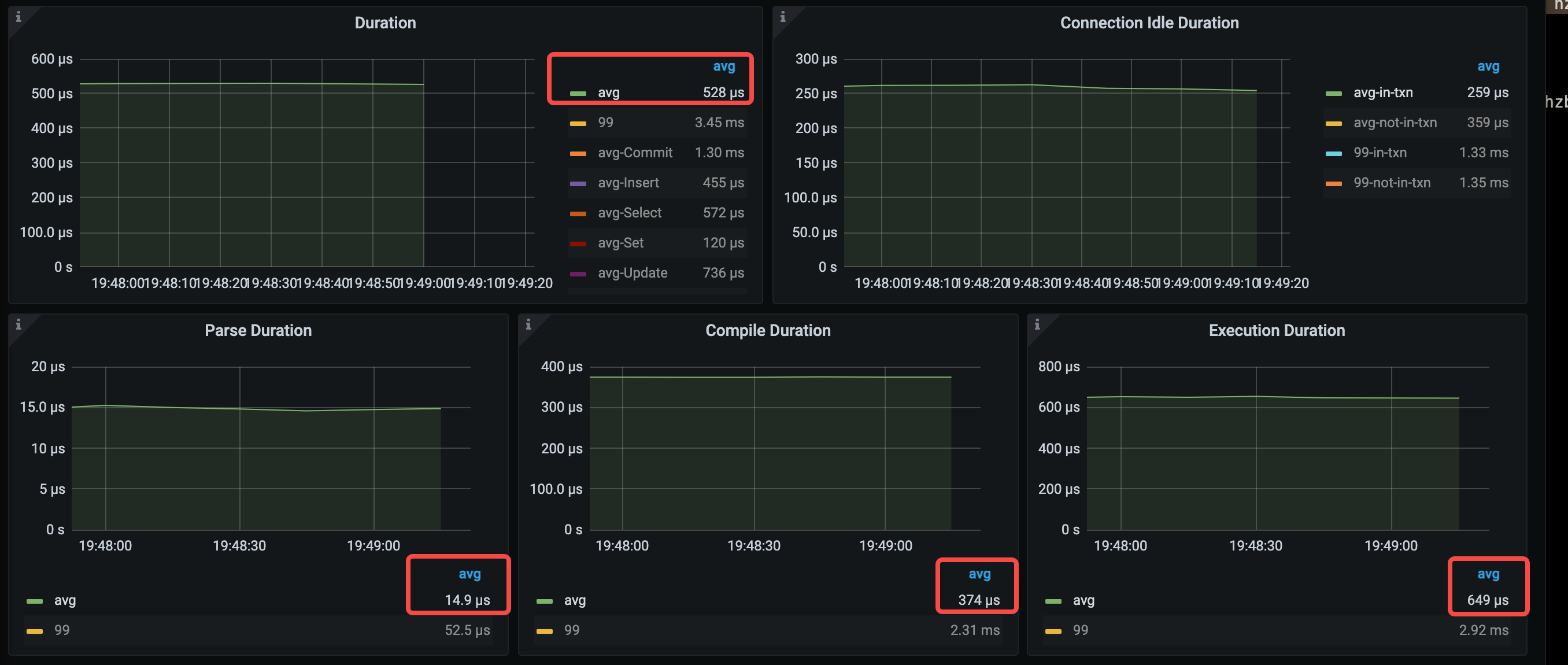
- 平均クエリ時間 = 528μs (1.12ms から 528μs まで)
- 平均解析時間 = 14.9μs (84.7μs から 14.9μs へ)
- 平均コンパイル時間 = 374μs (370μs から 374μs へ)
- 平均実行時間 = 649μs (626μs から 649μs へ)
分析の結論
シナリオ 2 とは異なり、シナリオ 3 のアプリケーションはプリペアド ステートメント インターフェイスを有効にしますが、それでもキャッシュにヒットしません。さらに、シナリオ 2 には CPS By Type コマンド タイプ ( Query ) が 1 つしかありませんが、シナリオ 3 にはさらに 3 つのコマンド タイプ ( StmtPrepare 、 StmtExecute 、 StmtClose ) があります。シナリオ 2 と比較すると、シナリオ 3 ではネットワーク ラウンドトリップの遅延が 2 回増えています。
- QPS の減少の分析: CPS By Typeペインから、シナリオ 2 には 1 つの CPS By Type コマンド タイプ (
Query) しかないのに対し、シナリオ 3 にはさらに 3 つのコマンド タイプ (StmtPrepare、StmtExecute、StmtClose) があることがわかります。StmtPrepareとStmtCloseは、QPS でカウントされない非従来型のコマンドであるため、QPS が減少します。異例のコマンドStmtPrepareとStmtCloseはgeneralの SQL タイプにカウントされるため、シナリオ 3 のデータベース概要ではgeneral時間が表示され、データベース時間の 4 分の 1 以上を占めます。 - 平均クエリ所要時間の大幅な減少の分析: シナリオ 3 で新たに追加された
StmtPrepareおよびStmtCloseのコマンド タイプについて、それらのクエリ所要時間は TiDB 内部処理で個別に計算されます。 TiDB はこれら 2 種類のコマンドを非常に高速に実行するため、クエリの平均所要時間は大幅に短縮されます。
シナリオ 3 では Prepared Statement インターフェイスを使用していますが、多くのアプリケーション フレームワークはメモリ リークを防ぐためにStmtExecuteの後にStmtCloseメソッドを呼び出すため、実行プラン キャッシュはヒットしません。 v6.0.0 以降、グローバル変数tidb_ignore_prepared_cache_close_stmt=on;を設定できます。その後、アプリケーションがStmtCloseメソッドを呼び出しても、TiDB はキャッシュされた実行計画をクリアしないため、次の SQL 実行では既存の実行計画を再利用でき、実行計画を繰り返しコンパイルする必要がなくなります。
シナリオ 4. Prepared Statement インターフェイスを使用し、実行計画のキャッシュを有効にする
アプリケーション構成
アプリケーション構成はシナリオ 3 と同じままです。アプリケーションがトリガーしてもキャッシュにヒットしない問題を解決するためにStmtClose 、次のパラメーターが構成されます。
- TiDB グローバル変数
set global tidb_ignore_prepared_cache_close_stmt=on;を設定します (TiDB v6.0.0 から導入され、デフォルトではoff)。 - TiDB 構成項目
prepared-plan-cache: {enabled: true}を設定して、プラン キャッシュ機能を有効にします。
パフォーマンス分析
TiDB ダッシュボード
TiDB の CPU 使用率のフレーム チャートから、 CompileExecutePreparedStmtとOptimizeには有意な CPU 使用率がないことがわかります。 CPU の 25% がPrepareコマンドによって消費されます。このコマンドには、 PlanBuilderやparseSQLなどの解析関連の Prepare の関数が含まれています。
PreparseStmt CPU = 25% CPU 時間 = 12.75 秒
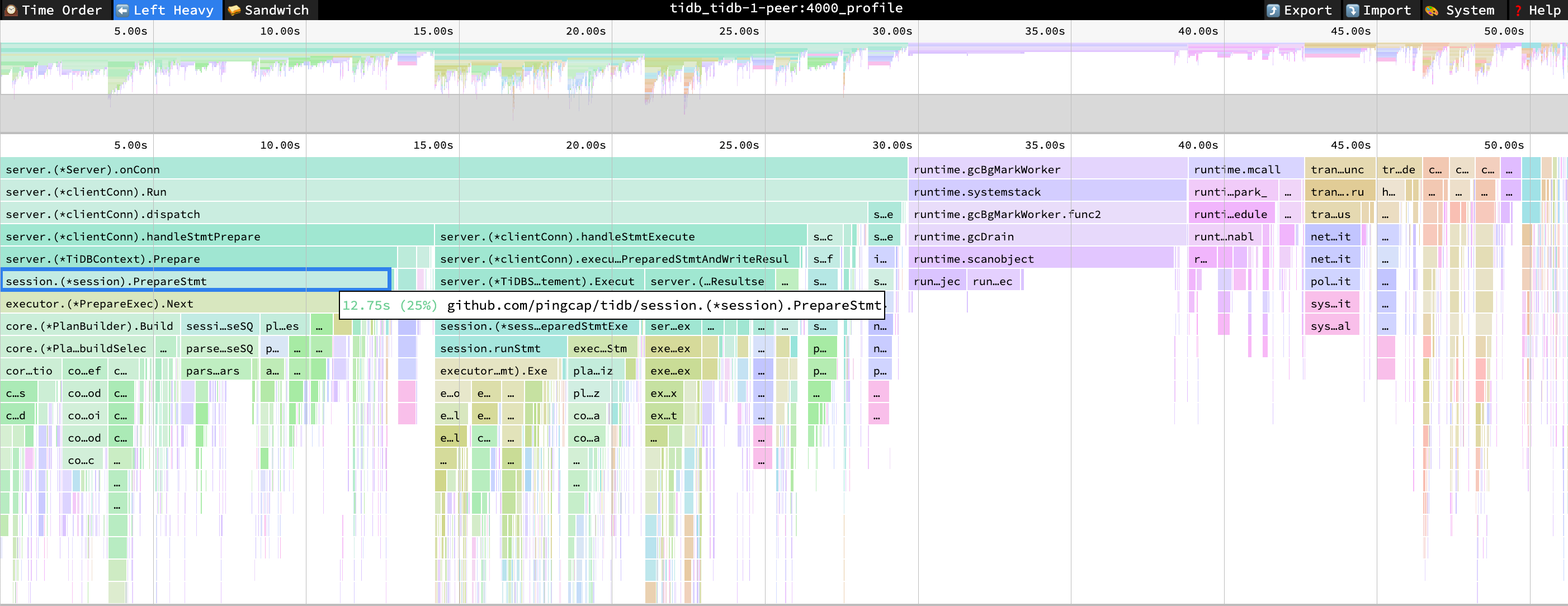
パフォーマンス概要ダッシュボード
Performance Overview ダッシュボードで最も重要な変化は、第compileフェーズの平均時間で、シナリオ 3 の 8.95 秒/秒から 1.18 秒/秒に短縮されています。実行計画キャッシュを使用するクエリの数は、値StmtExecuteにほぼ等しくなります。 QPS の増加に伴い、1 秒あたりSelectステートメントで消費されるデータベース時間は減少し、1 秒あたりgeneralステートメント タイプで消費されるデータベース時間は増加します。
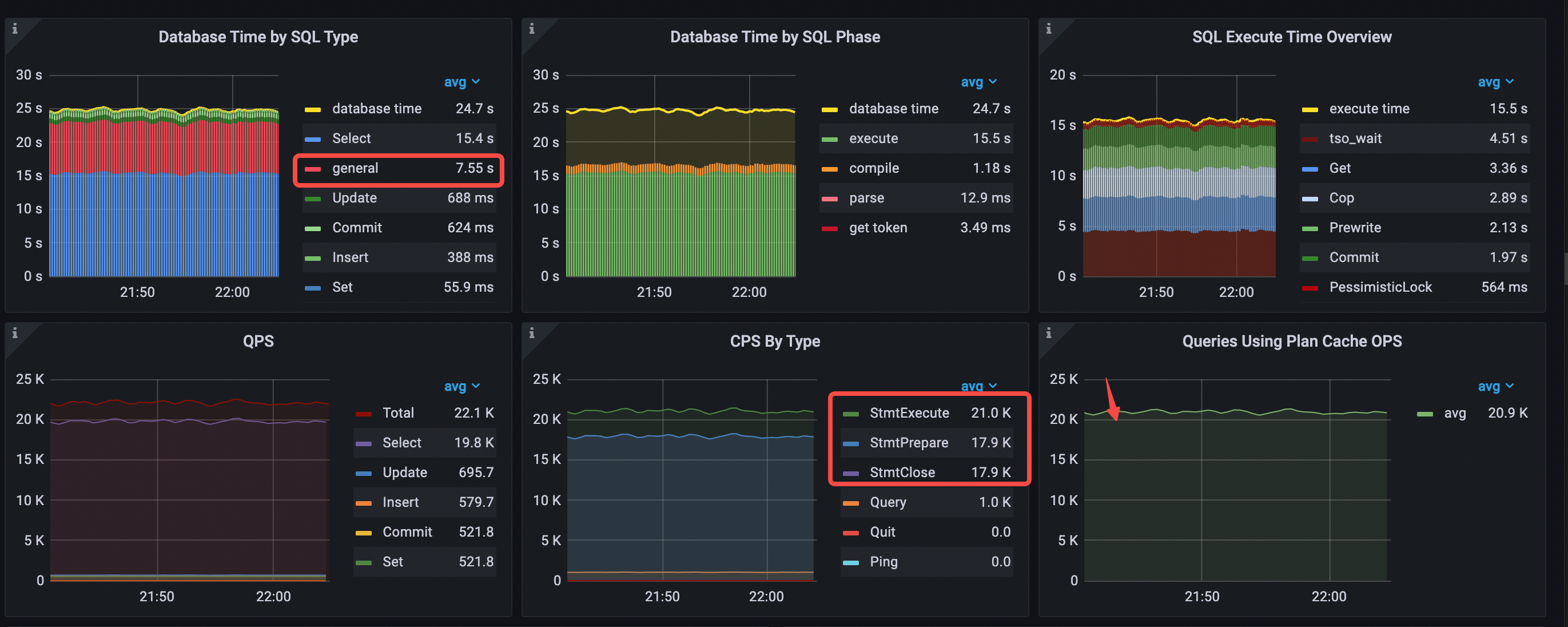
- SQL タイプ別のデータベース時間:
Selectステートメント タイプが最も時間がかかります。 - SQL フェーズごとのデータベース時間:
executeフェーズにほとんどの時間がかかります。 - SQL 実行時間の概要:
tso wait、Get、およびCopが最も時間がかかります。 - 実行プランのキャッシュにヒットしました。 Plan Cache OPS を使用したクエリの値は、およそ
StmtExecute秒あたり 1 に相当します。 - タイプ別 CPS: 3 種類のコマンド (シナリオ 3 と同じ)
- シナリオ 3 と比較すると、QPS が増加したため、
generalのステートメントで消費される時間が長くなります。 - 平均 QPS = 22.1k (19.7k から 22.1k へ)
平均 TiDB CPU 使用率は 936% から 827% に低下します。
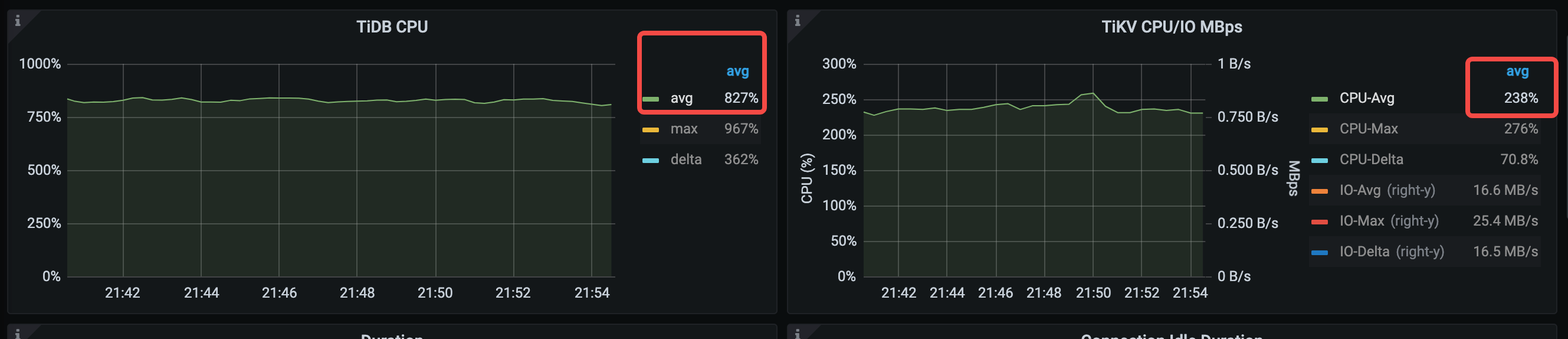
平均compile時間は、374 us から 53.3 us に大幅に減少します。 QPS が増加するため、平均execute時間も増加します。
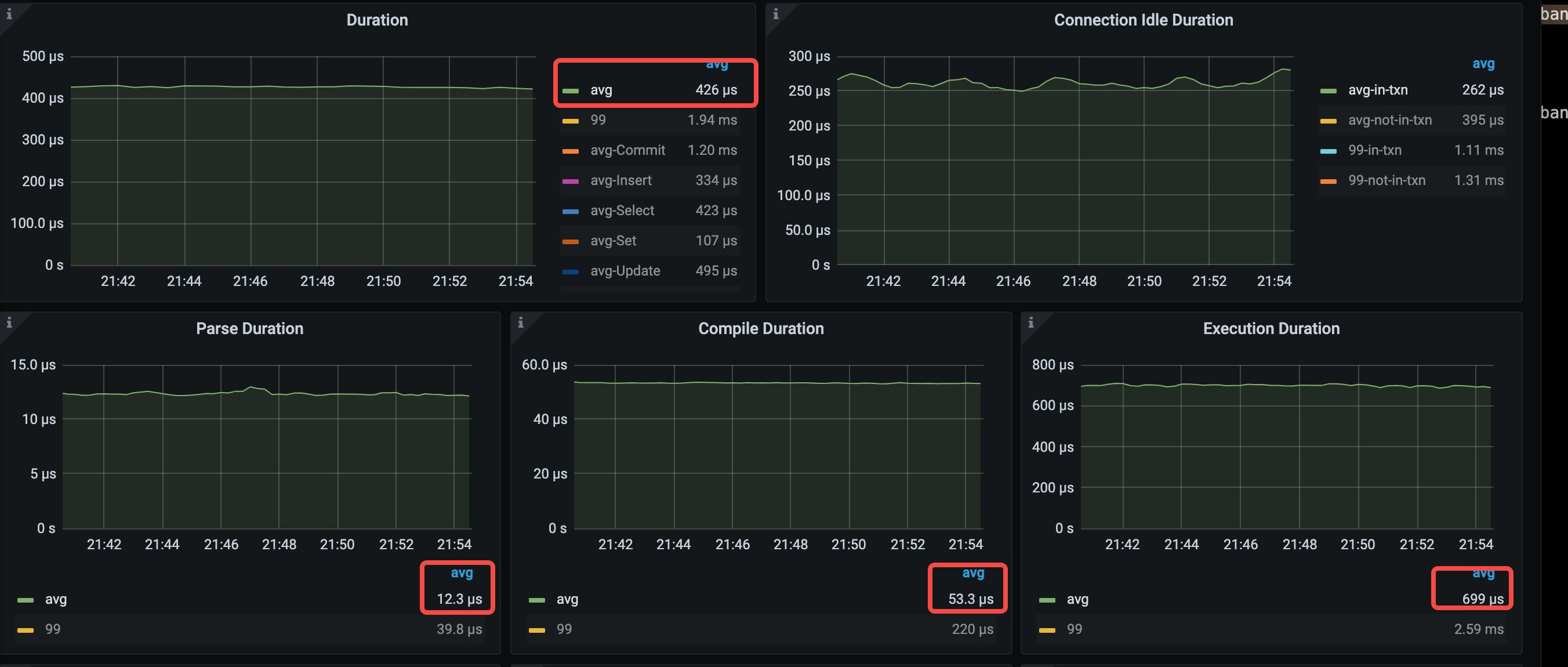
- 平均クエリ時間 = 426μs (528μs から 426μs へ)
- 平均解析時間 = 12.3μs (14.8μs から 12.3μs へ)
- 平均コンパイル時間 = 53.3μs (374μs から 53.3μs へ)
- 平均実行時間 = 699μs (649μs から 699us まで)
分析の結論
シナリオ 3 と比較して、シナリオ 4 も 3 つのコマンド タイプを使用します。違いは、シナリオ 4 が実行プラン キャッシュにヒットすることです。これにより、コンパイル時間が大幅に短縮され、クエリ時間が短縮され、QPS が向上します。
StmtPrepareとStmtCloseのコマンドはかなりのデータベース時間を消費し、アプリケーションが SQL ステートメントを実行するたびに、アプリケーションと TiDB の間の対話の数が増えるためです。次のシナリオでは、JDBC 構成を介してこれら 2 つのコマンドの呼び出しを排除することで、パフォーマンスをさらに調整します。
シナリオ 5. クライアント側で準備済みオブジェクトをキャッシュする
アプリケーション構成
シナリオ 4 と比較すると、以下で説明するように、3 つの新しい JDBC パラメータcachePrepStmts=true&prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480が設定されています。
cachePrepStmts = true: クライアント側で Prepared Statement オブジェクトをキャッシュします。これにより、StmtPrepare と StmtClose の呼び出しがなくなります。prepStmtCacheSize: 値は 0 より大きい必要があります。prepStmtCacheSqlLimit: 値は SQL テキストの長さより大きくなければなりません。
シナリオ 5 の完全な JDBC 構成は次のとおりです。
useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480&useConfigs=maxPerformance
パフォーマンス分析
TiDB ダッシュボード
以下の TiDB のフレーム チャートから、 Prepareコマンドの CPU 消費量が高くなっていることがなくなりました。
- ExecutePreparedStmt CPU = 22% CPU 時間 = 8.4 秒
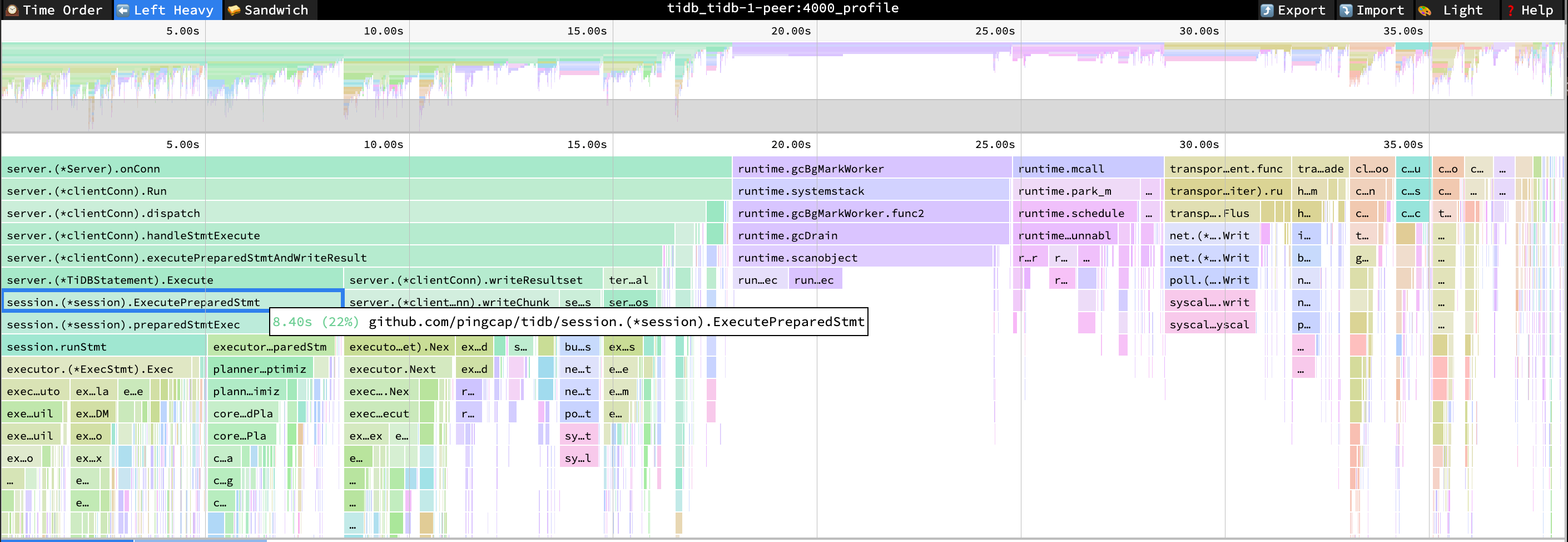
パフォーマンス概要ダッシュボード
Performance Overview ダッシュボードで最も注目すべき変更点は、[ CPS By Type ] ペインの 3 つの Stmt コマンド タイプが 1 つのタイプにドロップされ、[ Database Time by SQL Type ] ペインのgeneralのステートメント タイプが削除され、[ QPS]ペインの QPS が削除されたことです。 30.9k に増加します。
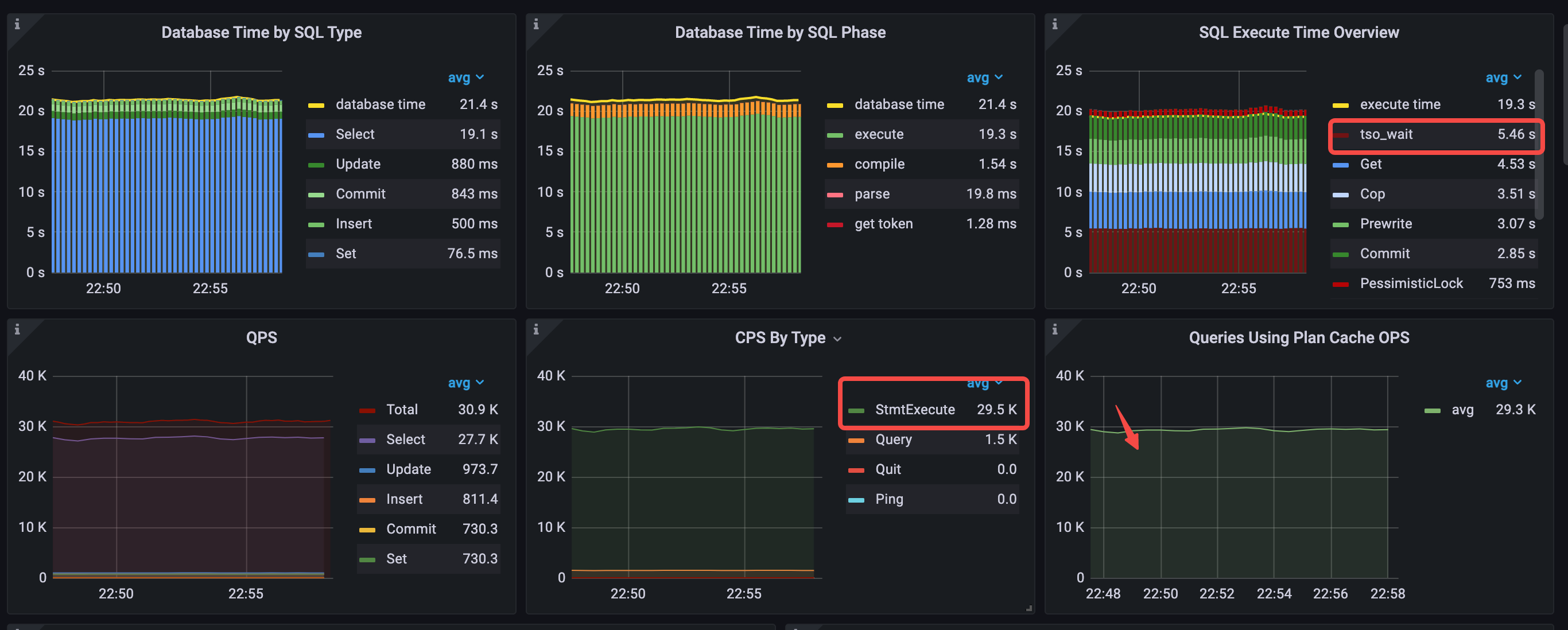
- SQL タイプ別のデータベース時間:
Selectステートメント タイプが最も時間がかかり、generalステートメント タイプは消えます。 - SQL フェーズごとのデータベース時間:
executeフェーズにほとんどの時間がかかります。 - SQL 実行時間の概要:
tso wait、Get、およびCopが最も時間がかかります。 - 実行プランのキャッシュにヒットしました。 Plan Cache OPS を使用したクエリの値は、およそ
StmtExecute秒あたり 1 に相当します。 - タイプ別 CPS:
StmtExecuteコマンドのみが使用されます。 - 平均 QPS = 30.9k (22.1k から 30.9k へ)
平均 TiDB CPU 使用率は 827% から 577% に低下します。 QPS が増加すると、平均 TiKV CPU 使用率は 313% に増加します。
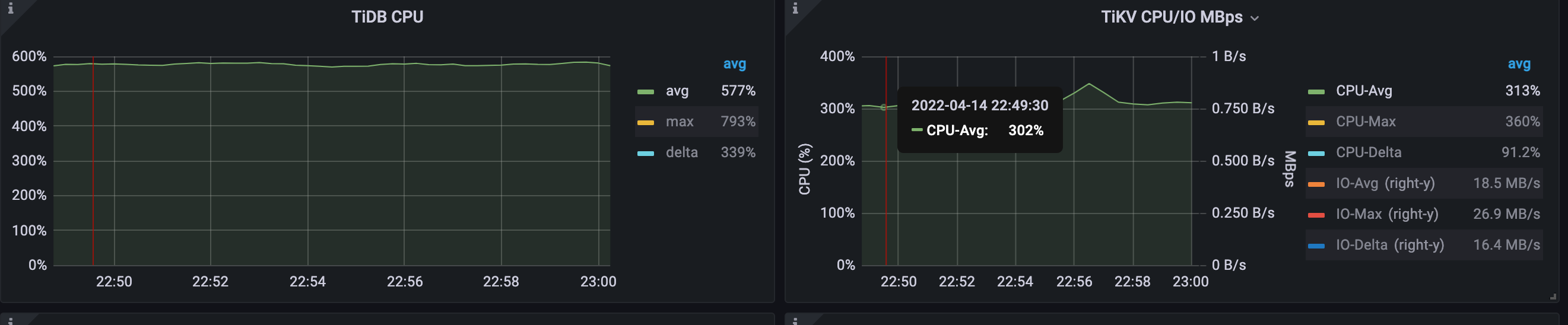
主なレイテンシーメトリックは次のとおりです。
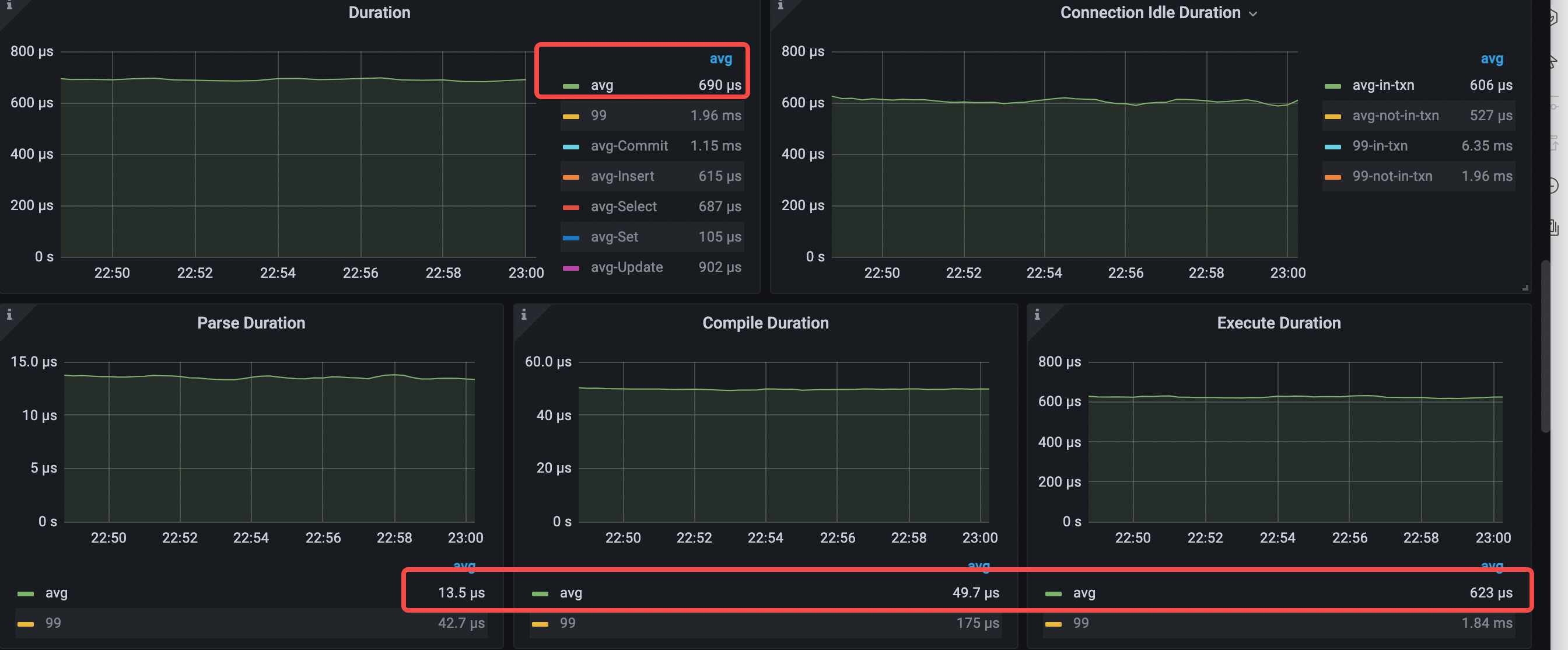
- 平均クエリ時間 = 690μs (426μs から 690μs へ)
- 平均解析時間 = 13.5μs (12.3μs から 13.5μs へ)
- 平均コンパイル時間 = 49.7μs (53.3μs から 49.7μs へ)
- 平均実行時間 = 623μs (699us から 623μs まで)
- 平均 pd tso 待機時間 = 196μs (224μs から 196μs へ)
- 接続アイドル時間 avg-in-txn = 608μs (250μs から 608μs へ)
分析の結論
- シナリオ 4 と比較すると、シナリオ 5 のCPS By Typeペインには
StmtExecuteコマンドしかないため、2 つのネットワーク ラウンド トリップが回避され、システム全体の QPS が向上します。 - QPS が増加した場合、解析時間、コンパイル時間、および実行時間に関してレイテンシーは減少しますが、クエリ時間は代わりに増加します。これは、TiDB が
StmtPrepareとStmtCloseを非常に迅速に処理するためであり、これら 2 つのコマンド タイプを排除すると、クエリの平均時間が長くなります。 - SQL フェーズ別のデータベース時間では、
executeが最も時間がかかり、データベース時間に近くなっています。 SQL 実行時間の概要では、tso waitがほとんどの時間を要し、executeの 4 分の 1 以上の時間が TSO の待機に費やされています。 - 合計
tso wait秒あたりの時間は 5.46 秒です。平均tso wait回は 196us、1 秒あたりのtso cmd回の回数は 28k で、QPS の 30.9k に非常に近い値です。これは、TiDB でのread committed分離レベルの実装によると、トランザクション内のすべての SQL ステートメントが PD から TSO を要求する必要があるためです。
TiDB v6.0 はrc readを提供し、これはtso cmdを減らすことによってread committed分離レベルを最適化します。この機能は、グローバル変数set global tidb_rc_read_check_ts=on;によって制御されます。この変数が有効になっている場合、TiDB のデフォルトの動作は、PD から取得する必要があるのはstart-tsとcommit-tsのみであるrepeatable-read分離レベルと同じように機能します。トランザクション内のステートメントは、最初にstart-tsを使用して TiKV からデータを読み取ります。 TiKV から読み取ったデータがstart-tsより前の場合、データは直接返されます。 TiKV から読み取ったデータがstart-tsより後の場合、データは破棄されます。 TiDB は PD に TSO を要求し、読み取りを再試行します。後続のfor update ts個のステートメントは、最新の PD TSO を使用します。
シナリオ 6: tidb_rc_read_check_ts変数を有効にして TSO 要求を減らす
アプリケーション構成
シナリオ 5 と比較すると、アプリケーション構成は同じままです。唯一の違いは、TSO 要求を減らすようにset global tidb_rc_read_check_ts=on;変数が構成されていることです。
パフォーマンス分析
ダッシュボード
TiDB CPU のフレーム チャートには大きな変更はありません。
- ExecutePreparedStmt CPU = 22% CPU 時間 = 8.4 秒
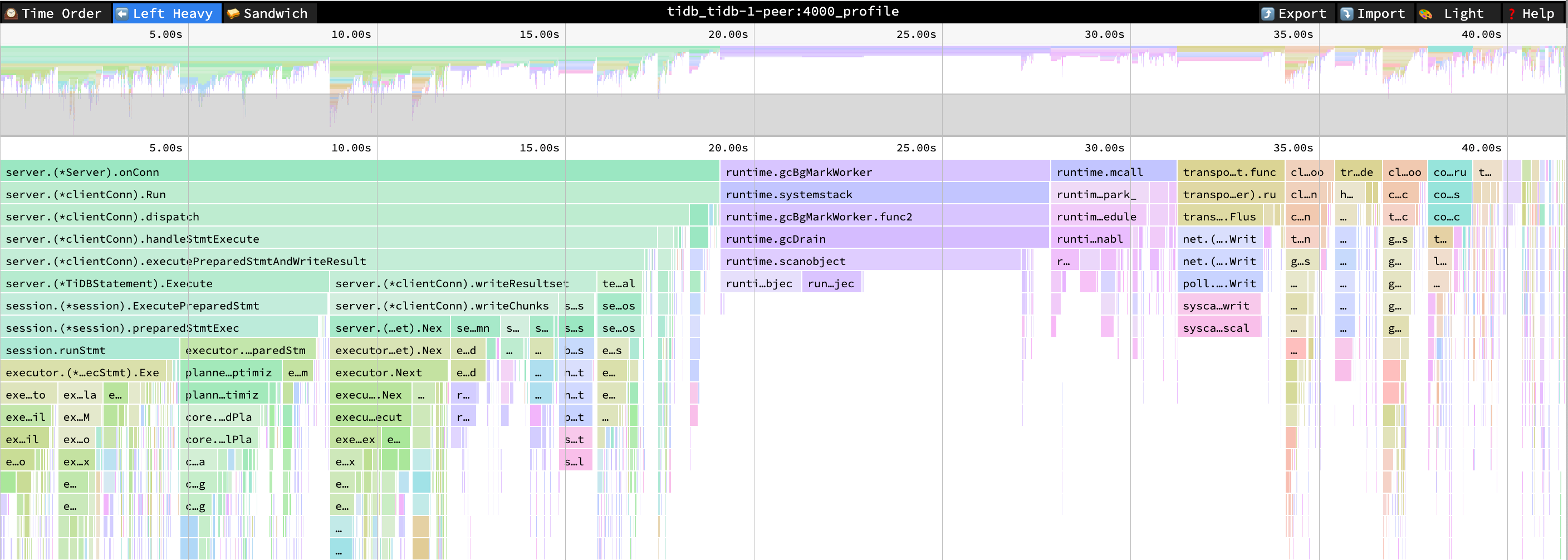
パフォーマンス概要ダッシュボード
RC 読み取りを使用した後、QPS は 30.9k から 34.9k に増加し、 tso wait秒あたりの消費時間は 5.46 秒から 456 ミリ秒に減少します。
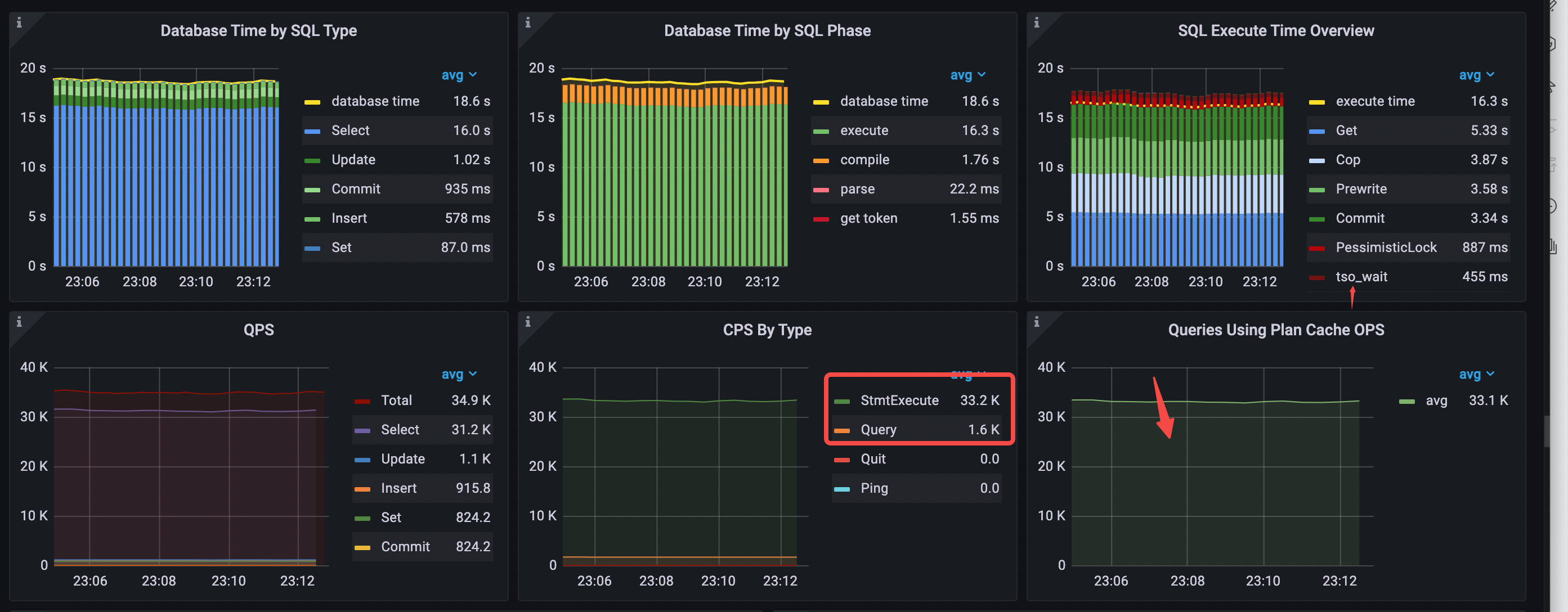
- SQL タイプ別のデータベース時間:
Selectステートメント タイプが最も時間がかかります。 - SQL フェーズごとのデータベース時間:
executeフェーズにほとんどの時間がかかります。 - SQL 実行時間の概要:
Get、Cop、およびPrewriteが最も時間がかかります。 - 実行プランのキャッシュにヒットしました。 Plan Cache OPS を使用したクエリの値は、およそ
StmtExecute秒あたり 1 に相当します。 - タイプ別 CPS:
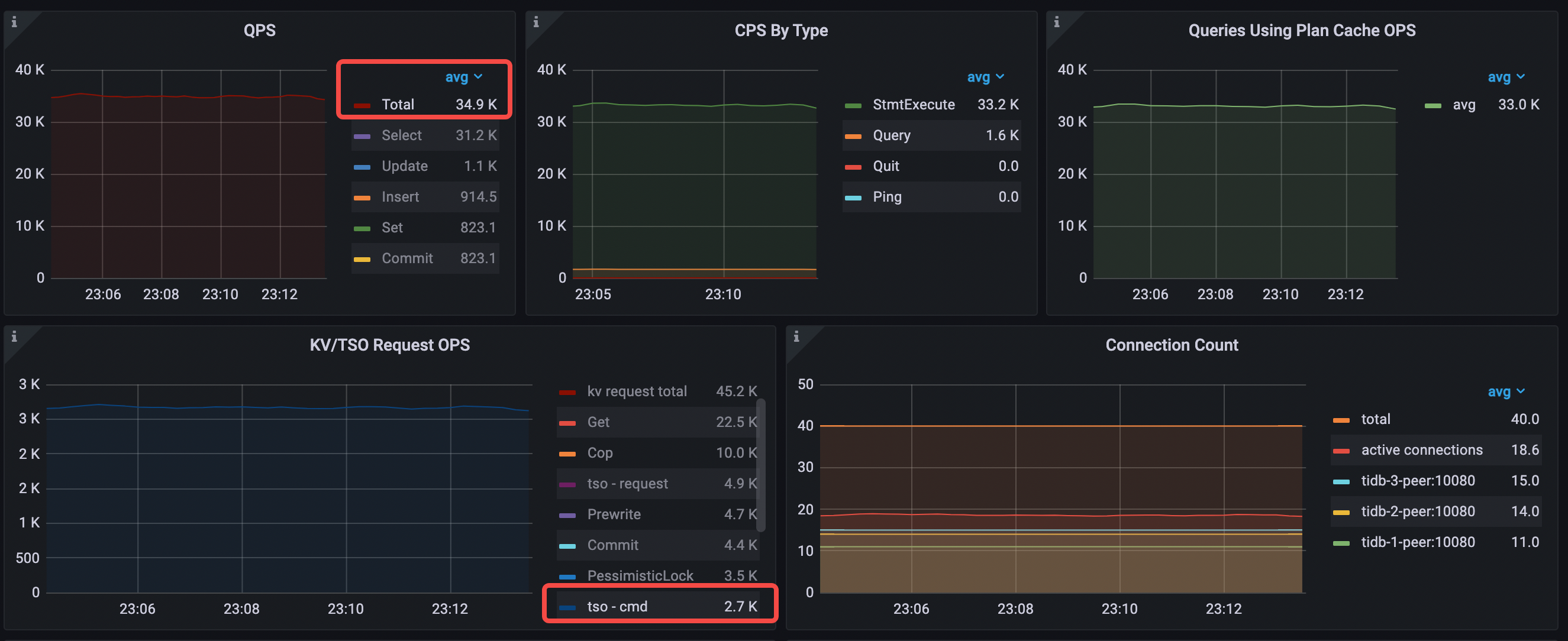
StmtExecuteコマンドのみが使用されます。 - 平均 QPS = 34.9k (30.9k から 34.9k へ)
tso cmd秒あたりの速度は 28.3k から 2.7k に低下します。
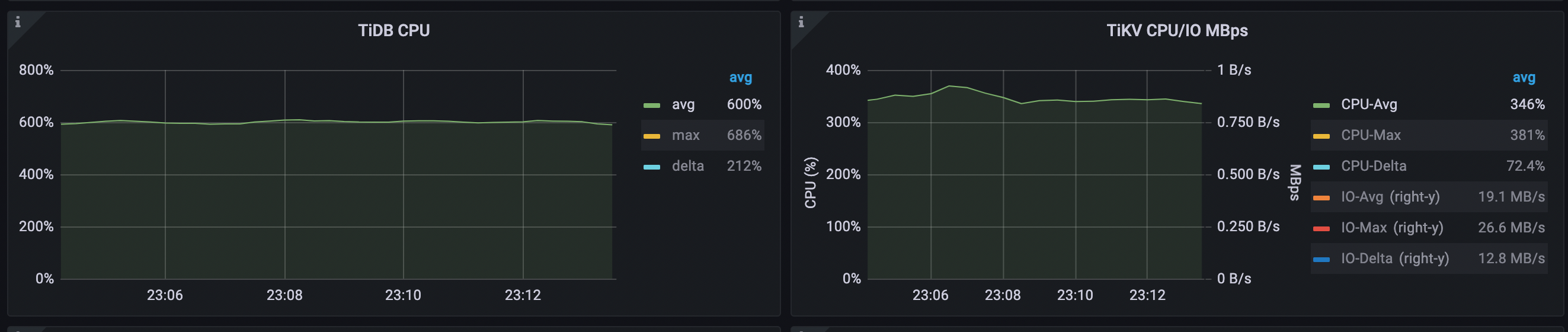
平均 TiDB CPU は 603% に増加します (577% から 603% へ)。
主なレイテンシーメトリックは次のとおりです。
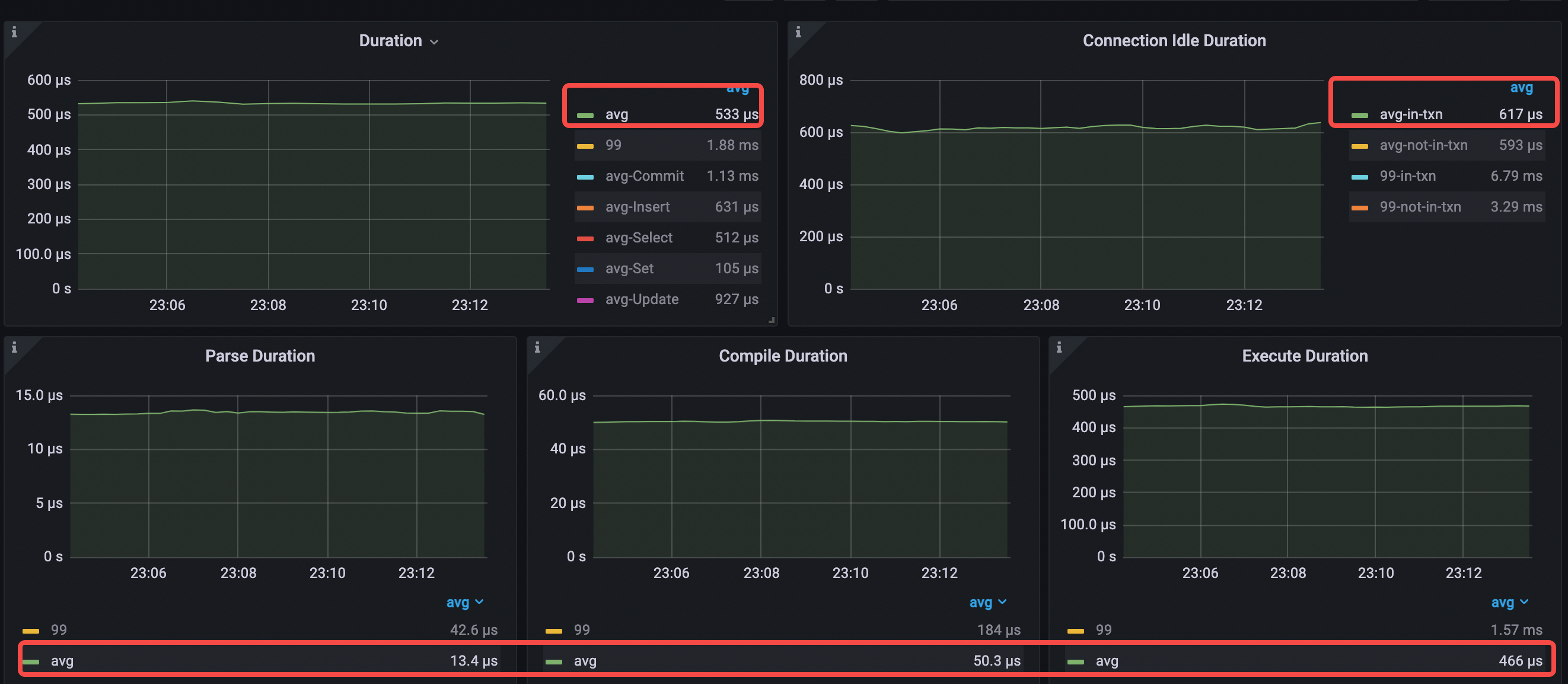
- 平均クエリ時間 = 533μs (690μs から 533μs へ)
- 平均解析時間 = 13.4μs (13.5μs から 13.4μs へ)
- 平均コンパイル時間 = 50.3μs (49.7μs から 50.3μs へ)
- 平均実行時間 = 466μs (623μs から 466μs へ)
- 平均 pd tso 待機時間 = 171μs (196μs から 171μs へ)
分析の結論
RC Read by set global tidb_rc_read_check_ts=on;を有効にすると、RC Read によってtso cmdの時間が大幅に短縮されるため、 tso waitと平均クエリ時間が短縮され、QPS が向上します。
現在のデータベース時間とレイテンシー時間の両方のボトルネックはexecuteフェーズにあり、 GetとCopの読み取り要求の割合が最も高くなります。このワークロードのほとんどのテーブルは読み取り専用であるか、めったに変更されないため、TiDB v6.0.0 以降でサポートされている小さなテーブル キャッシュ機能を使用して、これらの小さなテーブルのデータをキャッシュし、KV 読み取り要求の待機時間とリソース消費を削減できます。 .
シナリオ 7: 小さなテーブル キャッシュを使用する
アプリケーション構成
シナリオ 6 と比較すると、アプリケーション構成は同じままです。唯一の違いは、シナリオ 7 ではalter table t1 cache;などの SQL ステートメントを使用して、ビジネス用の読み取り専用テーブルをキャッシュすることです。
パフォーマンス分析
TiDB ダッシュボード
TiDB CPU のフレーム チャートには大きな変更はありません。
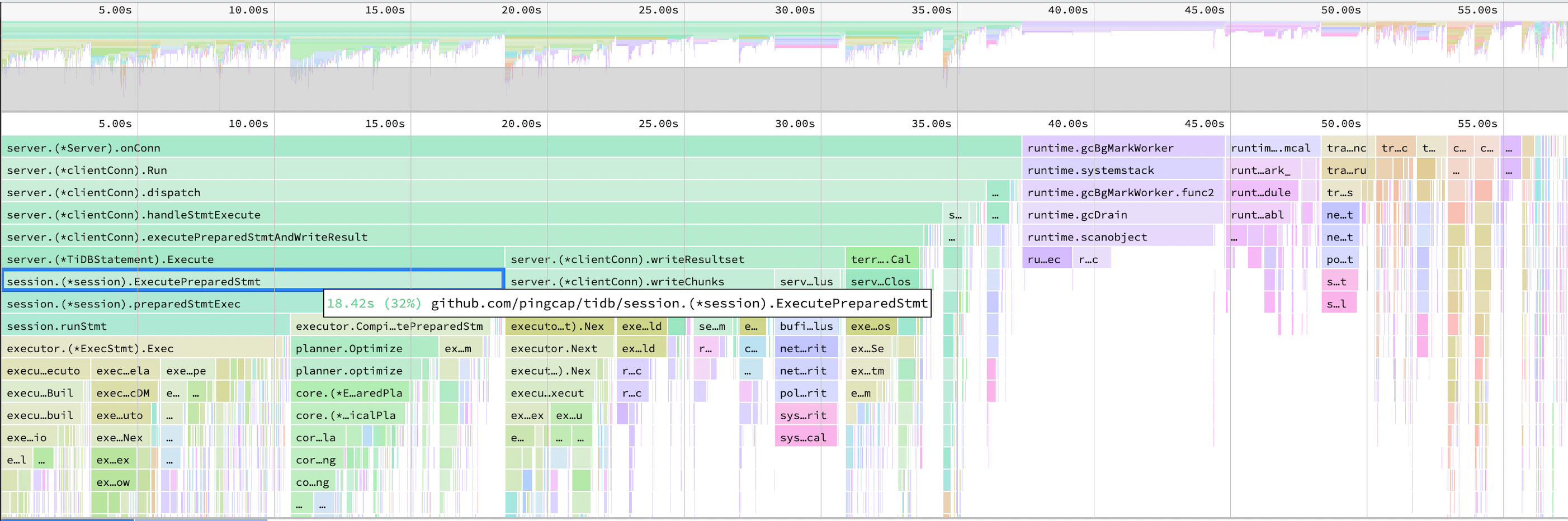
パフォーマンス概要ダッシュボード
QPS は 34.9k から 40.9k に増加し、KV リクエスト タイプはPrewriteおよびCommitへのexecuteフェーズの変更に最も時間がかかります。 1 秒あたりGetによって消費されるデータベース時間は 5.33 秒から 1.75 秒に減少し、1 秒あたりCopによって消費されるデータベース時間は 3.87 秒から 1.09 秒に減少します。
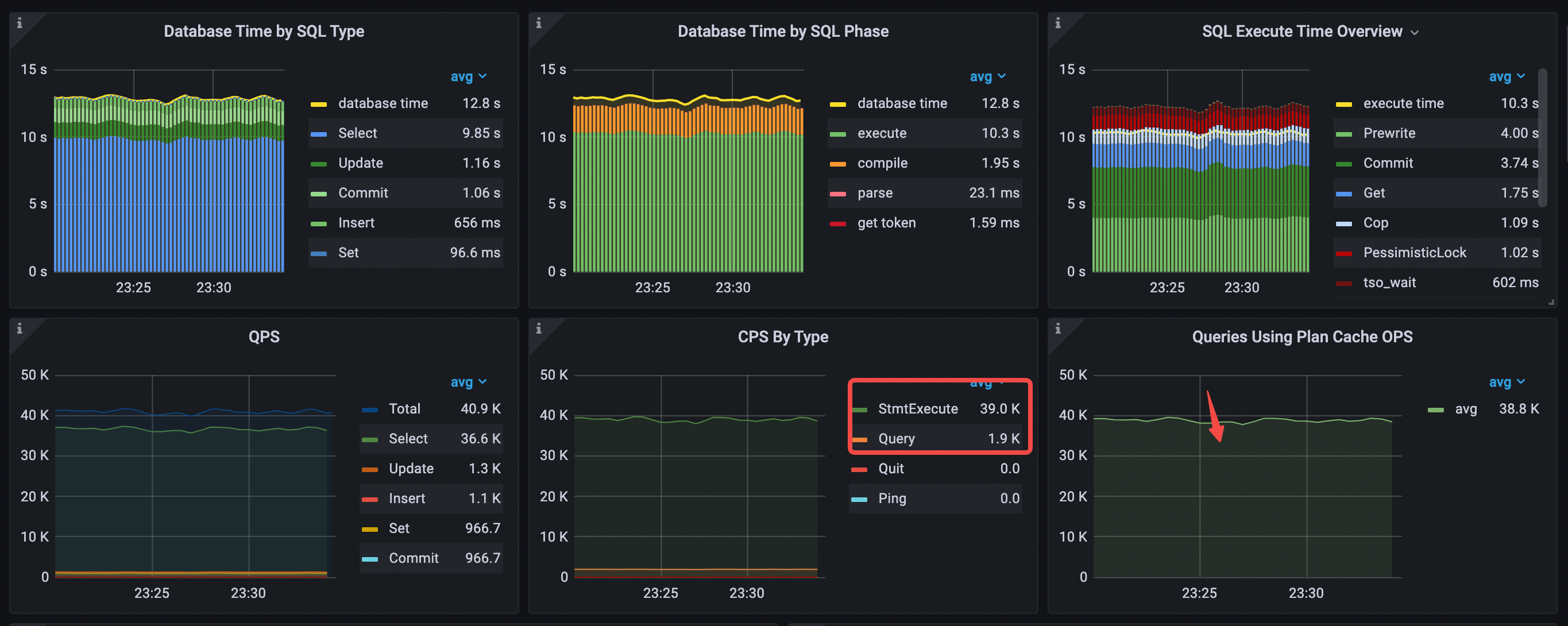
- SQL タイプ別のデータベース時間:
Selectステートメント タイプが最も時間がかかります。 - SQL フェーズごとのデータベース時間:
executeフェーズとcompileフェーズに最も時間がかかります。 - SQL 実行時間の概要:
Prewrite、Commit、およびGetが最も時間がかかります。 - 実行プランのキャッシュにヒットしました。 Plan Cache OPS を使用したクエリの値は、およそ
StmtExecute秒あたり 1 に相当します。 - タイプ別 CPS:
StmtExecuteコマンドのみが使用されます。 - 平均 QPS = 40.9k (34.9k から 40.9k へ)
平均 TiDB CPU 使用率は 603% から 478% に低下し、平均 TiKV CPU 使用率は 346% から 256% に低下します。
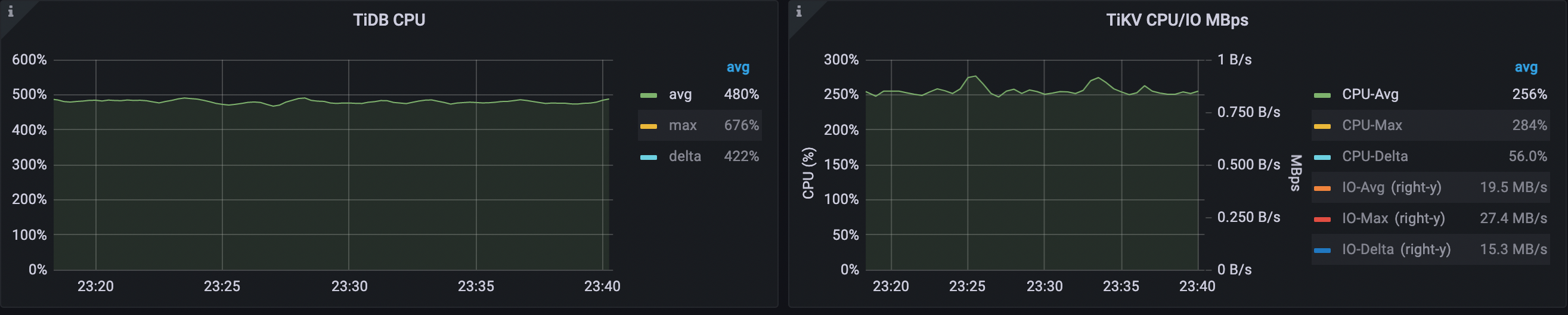
平均クエリレイテンシーは 533 us から 313 us に減少します。平均executeレイテンシーは 466 us から 250 us に減少します。
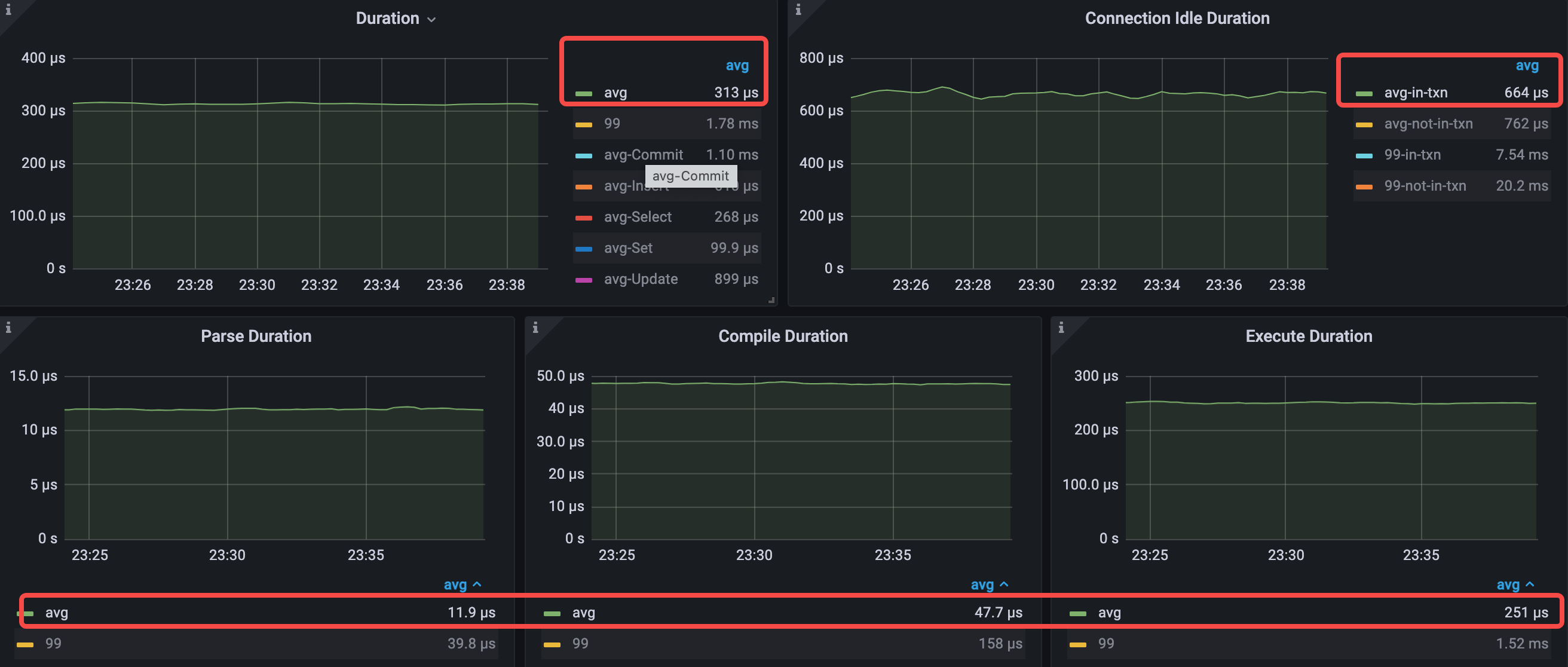
- 平均クエリ時間 = 313μs (533μs から 313μs へ)
- 平均解析時間 = 11.9μs (13.4μs から 11.9μs へ)
- 平均コンパイル時間 = 47.7μs (50.3μs から 47.7μs へ)
- 平均実行時間 = 251μs (466μs から 251μs へ)
分析の結論
すべての読み取り専用テーブルをキャッシュした後、 Execute Durationは大幅に低下します。これは、すべての読み取り専用テーブルが TiDB にキャッシュされ、これらのテーブルについて TiKV でデータをクエリする必要がないため、クエリの所要時間が短縮され、QPS が増加するためです。
これは楽観的な結果です。実際のビジネスでの読み取り専用テーブルのデータは、TiDB がすべてをキャッシュするには大きすぎる可能性があるためです。もう 1 つの制限は、小さなテーブル キャッシュ機能は書き込み操作をサポートしていますが、すべてのレイテンシーノードのキャッシュが最初に無効化されることを保証するために、書き込み操作にはデフォルトで 3 秒の待機が必要であることです。
概要
次の表は、7 つの異なるシナリオのパフォーマンスを示しています。
| 指標 | シナリオ 1 | シナリオ 2 | シナリオ 3 | シナリオ 4 | シナリオ 5 | シナリオ 6 | シナリオ 7 | シナリオ 5 とシナリオ 2 の比較 (%) | シナリオ 7 とシナリオ 3 の比較 (%) |
|---|---|---|---|---|---|---|---|---|---|
| クエリ期間 | 479μs | 1120μs | 528μs | 426μs | 690μs | 533μs | 313μs | -38% | -51% |
| QPS | 56.3k | 24.2k | 19.7k | 22.1k | 30.9k | 34.9k | 40.9k | +28% | +108% |
これらのシナリオでは、シナリオ 2 はアプリケーションが Query インターフェースを使用する一般的なシナリオであり、シナリオ 5 はアプリケーションが Prepared Statement インターフェースを使用する理想的なシナリオです。
- シナリオ 2 とシナリオ 5 を比較すると、Java アプリケーション開発のベスト プラクティスを使用し、Prepared Statement オブジェクトをクライアント側にキャッシュすることで、各 SQL ステートメントが実行計画キャッシュにアクセスするために必要なコマンドとデータベースの対話は 1 回だけであることがわかります。クエリのレイテンシーが 38% 低下し、QPS が 28% 増加し、TiDB の平均 CPU 使用率が 936% から 577% に低下しました。
- シナリオ 2 とシナリオ 7 を比較すると、RC 読み取りや小さなテーブル キャッシュなどの最新のレイテンシー最適化機能をシナリオ 5 に加えることで、平均的な TiDB CPU が使用率は 936% から 478% に低下します。
各シナリオのパフォーマンスを比較すると、次の結論を導き出すことができます。
TiDB の実行プラン キャッシュは、OLTP のパフォーマンス チューニングにおいて重要な役割を果たします。 v6.0.0 から導入された RC 読み取りおよび小さなテーブル キャッシュ機能も、このワークロードのさらなるパフォーマンス チューニングにおいて重要な役割を果たします。
TiDB は、MySQL プロトコルのさまざまなコマンドと互換性があります。 Prepared Statement インターフェースを使用し、次の JDBC 接続パラメーターを設定すると、アプリケーションは最高のパフォーマンスを達成できます。
useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=1000&prepStmtCacheSqlLimit=20480&useConfigs= maxPerformanceパフォーマンスの分析とチューニングには、TiDB ダッシュボード (Top SQL機能や継続的なプロファイリング機能など) とパフォーマンス概要ダッシュボードを使用することをお勧めします。
- Top SQLの機能を使用すると、実行中にデータベース内の各 SQL ステートメントの CPU 消費を視覚的に監視および調査して、データベースのパフォーマンスの問題をトラブルシューティングできます。
- 継続的なプロファイリングを使用すると、TiDB、TiKV、および PD の各インスタンスからパフォーマンス データを継続的に収集できます。アプリケーションが異なるインターフェイスを使用して TiDB と対話する場合、TiDB の CPU 消費量の違いは非常に大きくなります。
- パフォーマンス概要ダッシュボードを使用すると、データベース時間と SQL 実行時間の内訳情報の概要を取得できます。データベース時間に基づいてパフォーマンスを分析および診断し、システム全体のパフォーマンスのボトルネックが TiDB にあるかどうかを判断できます。ボトルネックが TiDB にある場合は、データベース時間とレイテンシー時間の内訳を負荷プロファイルとリソース使用量とともに使用して、TiDB 内のパフォーマンスのボトルネックを特定し、それに応じてパフォーマンスを調整できます。
これらの機能を組み合わせて使用することで、実際のアプリケーションのパフォーマンスを効率的に分析および調整できます。