TiDB で Java アプリケーションを開発するためのベスト プラクティス
このドキュメントでは、Java アプリケーションを開発して TiDB をより効果的に使用するためのベスト プラクティスを紹介します。バックエンドの TiDB データベースと対話するいくつかの一般的な Java アプリケーション コンポーネントに基づいて、このドキュメントは開発中によく遭遇する問題の解決策も提供します。
Java アプリケーションのデータベース関連コンポーネント
Java アプリケーションで TiDB データベースと対話する一般的なコンポーネントには、次のものがあります。
- ネットワーク プロトコル: クライアントは、標準MySQL プロトコルを介して TiDBサーバーと対話します。
- JDBC API および JDBC ドライバー: Java アプリケーションは通常、標準JDBC (Java データベース接続) API を使用してデータベースにアクセスします。 TiDB に接続するには、JDBC API を介して MySQL プロトコルを実装する JDBC ドライバーを使用できます。このような MySQL 用の一般的な JDBC ドライバーには、 MySQL コネクタ/JおよびMariaDB コネクタ/Jが含まれます。
- データベース接続プール: 要求されるたびに接続を作成するオーバーヘッドを削減するために、アプリケーションは通常、接続プールを使用して接続をキャッシュし、再利用します。 JDBC 情報源は接続プール API を定義します。必要に応じて、さまざまなオープンソース接続プールの実装から選択できます。
- データ アクセス フレームワーク: 通常、アプリケーションはマイバティスや休止状態などのデータ アクセス フレームワークを使用して、データベース アクセス操作をさらに簡素化し、管理します。
- アプリケーションの実装: アプリケーション ロジックは、どのコマンドをいつデータベースに送信するかを制御します。一部のアプリケーションは、 春の取引の側面を使用して、トランザクションの開始およびコミット ロジックを管理します。
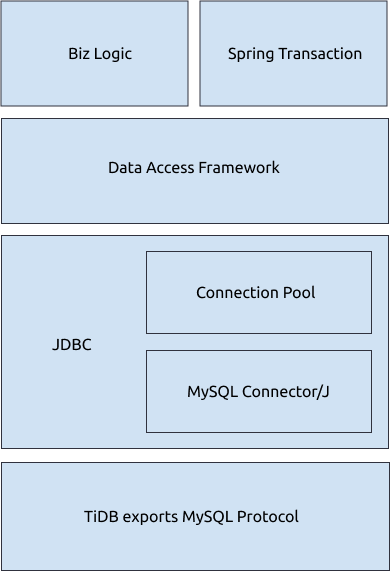
上の図から、Java アプリケーションが次のことを行う可能性があることがわかります。
- JDBC API を介して MySQL プロトコルを実装し、TiDB とやり取りします。
- 接続プールから永続的な接続を取得します。
- MyBatis などのデータ アクセス フレームワークを使用して、SQL ステートメントを生成および実行します。
- Spring Transaction を使用して、トランザクションを自動的に開始または停止します。
このドキュメントの残りの部分では、上記のコンポーネントを使用して Java アプリケーションを開発する際の問題とその解決策について説明します。
JDBC
Java アプリケーションは、さまざまなフレームワークでカプセル化できます。ほとんどのフレームワークでは、JDBC API が最下位レベルで呼び出され、データベースサーバーと対話します。 JDBC の場合、次の点に注目することをお勧めします。
- JDBC API の使用方法の選択
- API 実装者のパラメーター構成
JDBC API
JDBC API の使用法については、 JDBC 公式チュートリアルを参照してください。このセクションでは、いくつかの重要な API の使用法について説明します。
準備 API を使用する
OLTP (オンライン トランザクション処理) シナリオの場合、プログラムによってデータベースに送信される SQL ステートメントは、パラメーターの変更を削除した後に使い果たされる可能性があるいくつかのタイプです。したがって、通常のテキストファイルからの実行の代わりに準備されたステートメントを使用し、Prepared Statements を再利用して直接実行することをお勧めします。これにより、TiDB で SQL 実行計画を繰り返し解析して生成するオーバーヘッドが回避されます。
現在、ほとんどの上位レベルのフレームワークは、SQL 実行のために Prepare API を呼び出します。開発に JDBC API を直接使用する場合は、Prepare API の選択に注意してください。
さらに、MySQL Connector/J のデフォルトの実装では、クライアント側のステートメントのみが前処理され、ステートメントはクライアントで?が置き換えられた後、テキスト ファイルでサーバーに送信されます。したがって、Prepare API の使用に加えて、TiDBサーバーでステートメントの前処理を実行する前に、JDBC 接続パラメーターでuseServerPrepStmts = trueも構成する必要があります。詳細なパラメータ設定については、 MySQL JDBC パラメータを参照してください。
バッチ API を使用する
バッチ挿入の場合は、 addBatch / executeBatch APIを使用できます。メソッドaddBatch()は、最初に複数の SQL ステートメントをクライアントにキャッシュし、次にメソッドexecuteBatchを呼び出すときにそれらを一緒にデータベースサーバーに送信するために使用されます。
ノート:
デフォルトの MySQL Connector/J 実装では、
addBatch()でバッチに追加された SQL ステートメントの送信時刻はexecuteBatch()が呼び出される時刻まで遅延しますが、実際のネットワーク転送中にステートメントは 1 つずつ送信されます。したがって、この方法では通常、通信オーバーヘッドの量は減少しません。ネットワーク転送をバッチ処理する場合は、JDBC 接続パラメーターで
rewriteBatchedStatements = trueを構成する必要があります。詳細なパラメータ設定については、 バッチ関連のパラメーターを参照してください。
StreamingResultを使用して実行結果を取得する
ほとんどのシナリオでは、実行効率を向上させるために、JDBC はクエリ結果を事前に取得し、デフォルトでクライアント メモリに保存します。しかし、クエリが非常に大きな結果セットを返す場合、クライアントはデータベースサーバーに一度に返されるレコードの数を減らすことを要求し、クライアントのメモリの準備が整い、次のバッチを要求するまで待ちます。
通常、JDBC には 2 種類の処理方法があります。
FetchSizeをInteger.MIN_VALUEに設定しますを指定すると、クライアントはキャッシュされません。クライアントはStreamingResultを介してネットワーク接続から実行結果を読み取ります。クライアントがストリーミング読み取りメソッドを使用する場合、ステートメントを使用してクエリを作成し続ける前に、読み取りを終了するか、
resultsetを閉じる必要があります。それ以外の場合は、エラーNo statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.が返されます。クライアントが
resultsetの読み取りを終了するか閉じる前にクエリでこのようなエラーを回避するには、URL にclobberStreamingResults=trueパラメーターを追加します。次に、resultsetは自動的に閉じられますが、前のストリーミング クエリで読み取られる結果セットは失われます。Cursor Fetch を使用するには、最初に正の整数として
FetchSizeを設定を指定し、JDBC URL でuseCursorFetch=trueを構成します。
TiDB は両方の方法をサポートしていますが、最初の方法を使用することをお勧めします。これは、実装がより単純で実行効率が高いためです。
MySQL JDBC パラメータ
JDBC は通常、JDBC URL パラメータの形式で実装関連の構成を提供します。このセクションではMySQL Connector/J のパラメータ設定を紹介します (MariaDB を使用する場合はMariaDB のパラメーター構成を参照してください)。このドキュメントではすべての構成項目を取り上げることはできないため、主にパフォーマンスに影響を与える可能性があるいくつかのパラメーターに焦点を当てています。
準備関連パラメータ
このセクションでは、 Prepareに関連するパラメーターを紹介します。
useServerPrepStmts
useServerPrepStmtsはデフォルトでfalseに設定されています。つまり、Prepare API を使用しても、「準備」操作はクライアントでのみ行われます。サーバーの解析オーバーヘッドを回避するために、同じ SQL ステートメントで Prepare API を複数回使用する場合は、この構成をtrueに設定することをお勧めします。
この設定が既に有効になっていることを確認するには、次のようにします。
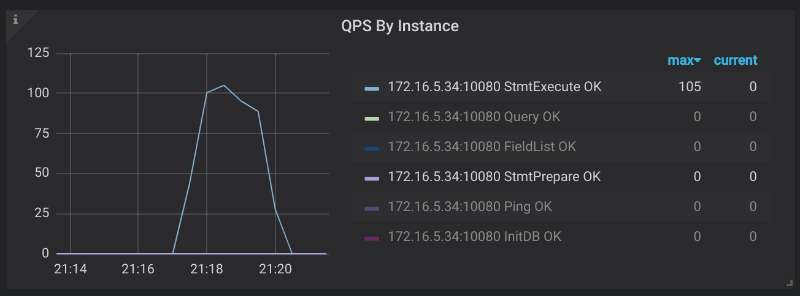
- TiDB モニタリング ダッシュボードに移動し、 [ Query Summary ] > [ QPS By Instance ] からリクエスト コマンド タイプを表示します。
- リクエストで
COM_QUERYがCOM_STMT_EXECUTEまたはCOM_STMT_PREPAREに置き換えられている場合は、この設定がすでに有効になっていることを意味します。
cachePrepStmts
useServerPrepStmts=trueを指定すると、サーバーはプリペアド ステートメントを実行できますが、デフォルトでは、クライアントは各実行後にプリペアド ステートメントを閉じ、それらを再利用しません。これは、「準備」操作がテキスト ファイルの実行ほど効率的ではないことを意味します。これを解決するには、 useServerPrepStmts=trueを設定した後、 cachePrepStmts=trueも設定することをお勧めします。これにより、クライアントはプリペアド ステートメントをキャッシュできます。
この設定が既に有効になっていることを確認するには、次のようにします。
- TiDB モニタリング ダッシュボードに移動し、 [ Query Summary ] > [ QPS By Instance ] からリクエスト コマンド タイプを表示します。
- リクエスト内の
COM_STMT_EXECUTEの数がCOM_STMT_PREPAREの数よりはるかに多い場合、この設定はすでに有効になっていることを意味します。
さらに、 useConfigs=maxPerformanceを構成すると、 cachePrepStmts=trueを含む複数のパラメーターが同時に構成されます。
prepStmtCacheSqlLimit
cachePrepStmtsを設定したら、 prepStmtCacheSqlLimitの設定にも注意してください (デフォルト値は256です)。この構成は、クライアントにキャッシュされるプリペアド ステートメントの最大長を制御します。
この最大長を超えるプリペアド ステートメントはキャッシュされないため、再利用できません。この場合、アプリケーションの実際の SQL 長に応じて、この構成の値を増やすことを検討してください。
次の場合は、この設定が小さすぎるかどうかを確認する必要があります。
- TiDB モニタリング ダッシュボードに移動し、 [ Query Summary ] > [ QPS By Instance ] からリクエスト コマンド タイプを表示します。
cachePrepStmts=trueが構成されていることを確認しますが、COM_STMT_PREPAREはまだCOM_STMT_EXECUTEとほぼ等しく、COM_STMT_CLOSEが存在します。
prepStmtCacheSize
prepStmtCacheSizeは、キャッシュされるプリペアド ステートメントの数を制御します (デフォルト値は25です)。アプリケーションで多くの種類の SQL ステートメントを「準備」する必要があり、準備済みステートメントを再利用したい場合は、この値を増やすことができます。
この設定が既に有効になっていることを確認するには、次のようにします。
- TiDB モニタリング ダッシュボードに移動し、 [ Query Summary ] > [ QPS By Instance ] からリクエスト コマンド タイプを表示します。
- リクエスト内の
COM_STMT_EXECUTEの数がCOM_STMT_PREPAREの数よりはるかに多い場合、この設定はすでに有効になっていることを意味します。
バッチ関連のパラメーター
バッチ書き込みの処理中は、 rewriteBatchedStatements=trueを構成することをお勧めします。 addBatch()またはexecuteBatch()を使用した後でも、JDBC はデフォルトで SQL を 1 つずつ送信します。次に例を示します。
pstmt = prepare("insert into t (a) values(?)");
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
Batchのメソッドが使用されますが、TiDB に送信される SQL ステートメントは依然として個別のINSERTのステートメントです。
insert into t(a) values(10);
insert into t(a) values(11);
insert into t(a) values(12);
ただし、 rewriteBatchedStatements=trueを設定すると、TiDB に送信される SQL ステートメントは単一のINSERTステートメントになります。
insert into t(a) values(10),(11),(12);
INSERTステートメントの書き直しは、複数の「値」キーワードの後の値を SQL ステートメント全体に連結することであることに注意してください。 INSERTのステートメントに他の違いがある場合は、次のように書き直すことはできません。
insert into t (a) values (10) on duplicate key update a = 10;
insert into t (a) values (11) on duplicate key update a = 11;
insert into t (a) values (12) on duplicate key update a = 12;
上記のINSERTつのステートメントを 1 つのステートメントに書き換えることはできません。ただし、3 つのステートメントを次のステートメントに変更すると、次のようになります。
insert into t (a) values (10) on duplicate key update a = values(a);
insert into t (a) values (11) on duplicate key update a = values(a);
insert into t (a) values (12) on duplicate key update a = values(a);
次に、書き換え要件を満たします。上記のINSERTつのステートメントは、次の 1 つのステートメントに書き換えられます。
insert into t (a) values (10), (11), (12) on duplicate key update a = values(a);
バッチ更新中に 3 つ以上の更新がある場合、SQL ステートメントは書き換えられ、複数のクエリとして送信されます。これにより、クライアントからサーバーへの要求のオーバーヘッドが効果的に削減されますが、より大きな SQL ステートメントが生成されるという副作用があります。例えば:
update t set a = 10 where id = 1; update t set a = 11 where id = 2; update t set a = 12 where id = 3;
さらに、 クライアントのバグであるため、バッチ更新中にrewriteBatchedStatements=trueとuseServerPrepStmts=trueを構成する場合は、このバグを回避するためにallowMultiQueries=trueパラメーターも構成することをお勧めします。
パラメータを統合する
監視を通じて、アプリケーションが TiDB クラスターに対してINSERTの操作しか実行しないにもかかわらず、冗長なSELECTのステートメントが多数あることに気付く場合があります。通常、これは、JDBC がselect @@session.transaction_read_onlyなどの設定をクエリするためにいくつかの SQL ステートメントを送信するために発生します。これらの SQL ステートメントは TiDB には役に立たないため、余分なオーバーヘッドを避けるためにuseConfigs=maxPerformanceを構成することをお勧めします。
useConfigs=maxPerformance構成には、構成のグループが含まれます。
cacheServerConfiguration=true
useLocalSessionState=true
elideSetAutoCommits=true
alwaysSendSetIsolation=false
enableQueryTimeouts=false
構成後、モニタリングを確認して、 SELECTステートメントの数が減少していることを確認できます。
タイムアウト関連のパラメーター
TiDB は、タイムアウトを制御する 2 つの MySQL 互換パラメーター ( wait_timeoutとmax_execution_time ) を提供します。これら 2 つのパラメータは、Java アプリケーションとの接続アイドル タイムアウトと、接続での SQL 実行のタイムアウトをそれぞれ制御します。つまり、これらのパラメータは、TiDB と Java アプリケーション間の接続の最長アイドル時間と最長ビジー時間を制御します。両方のパラメータのデフォルト値は0で、デフォルトでは、接続を無限にアイドル状態と無限にビジー状態にすることができます (1 つの SQL ステートメントを実行するための無限の期間)。
ただし、実際の本番環境では、アイドル接続や実行時間が過度に長い SQL ステートメントは、データベースやアプリケーションに悪影響を及ぼします。アイドル状態の接続と長時間実行される SQL ステートメントを回避するために、アプリケーションの接続文字列でこれら 2 つのパラメーターを構成できます。たとえば、 sessionVariables=wait_timeout=3600 (1 時間) とsessionVariables=max_execution_time=300000 (5 分) を設定します。
接続プール
TiDB (MySQL) 接続の構築は比較的コストがかかります (少なくとも OLTP シナリオの場合)。これは、TCP 接続の構築に加えて、接続認証も必要になるためです。したがって、クライアントは通常、再利用のために TiDB (MySQL) 接続を接続プールに保存します。
Java には、 光CP 、 tomcat-jdbc 、 ドルイド 、 c3p0 、およびdbcpなどの多くの接続プールの実装があります。 TiDB は、使用する接続プールを制限しないため、アプリケーションに合わせて好きなものを選択できます。
接続数を構成する
接続プールのサイズは、アプリケーション自体のニーズに合わせて適切に調整するのが一般的です。例として HikariCP を取り上げます。
maximumPoolSize: 接続プール内の接続の最大数。この値が大きすぎると、TiDB は無駄な接続を維持するためにリソースを消費します。この値が小さすぎると、アプリケーションの接続が遅くなります。したがって、この値を自分の利益のために構成してください。詳細については、 プールのサイジングについてを参照してください。minimumIdle: 接続プール内のアイドル接続の最小数。主に、アプリケーションがアイドル状態のときに突然の要求に応答するために、いくつかの接続を予約するために使用されます。アプリケーションのニーズに応じて構成することもできます。
アプリケーションは、使用終了後に接続を返す必要があります。また、アプリケーションで対応する接続プール監視 ( metricRegistryなど) を使用して、接続プールの問題を時間内に特定することもお勧めします。
プローブ構成
接続プールは、TiDB への永続的な接続を維持します。デフォルトでは、TiDB は積極的にクライアント接続を閉じませんが (エラーが報告されない限り)、通常、クライアントと TiDB の間に LVS や HAProxy などのネットワーク プロキシが存在します。通常、これらのプロキシは、(プロキシのアイドル構成によって制御される) 一定期間アイドル状態になっている接続をプロアクティブにクリーンアップします。プロキシのアイドル構成に注意を払うことに加えて、接続プールは、接続を維持するかプローブする必要もあります。
Java アプリケーションで次のエラーが頻繁に表示される場合:
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
nがn milliseconds agoまたは非常に小さい値である場合、通常は、実行された SQL 操作によって0が異常終了するためです。原因を特定するには、TiDB の stderr ログを確認することをお勧めします。
nが非常に大きな値 (上記の例の3600000など) である場合、この接続が長時間アイドル状態であり、その後中間プロキシによって閉じられた可能性があります。通常の解決策は、プロキシのアイドル構成の値を増やし、接続プールで次のことができるようにすることです。
- 毎回接続を使用する前に、接続が利用可能かどうかを確認してください
- 別のスレッドを使用して、接続が利用可能かどうかを定期的に確認してください。
- テストクエリを定期的に送信して接続を維持する
異なる接続プールの実装では、上記のメソッドの 1 つ以上がサポートされている場合があります。接続プールのドキュメントを確認して、対応する構成を見つけることができます。
データ アクセス フレームワーク
多くの場合、アプリケーションは、データベース アクセスを簡素化するために、ある種のデータ アクセス フレームワークを使用します。
マイバティス
マイバティスは一般的な Java データ アクセス フレームワークです。これは主に、SQL クエリを管理し、結果セットと Java オブジェクト間のマッピングを完了するために使用されます。 MyBatis は TiDB との互換性が高いです。 MyBatis は、その歴史的な問題に基づいて問題を起こすことはめったにありません。
ここでは、このドキュメントでは主に次の構成に焦点を当てています。
マッパーのパラメーター
MyBatis Mapper は 2 つのパラメーターをサポートしています。
select 1 from t where id = #{param1}は Prepared Statement としてselect 1 from t where id =?に変換されて「準備」され、実パラメータは再利用のために使用されます。このパラメーターを前述の Prepare 接続パラメーターと一緒に使用すると、最高のパフォーマンスを得ることができます。select 1 from t where id = ${param2}をselect 1 from t where id = 1にテキストファイルとして置き換えて実行します。このステートメントを別のパラメーターに置き換えて実行すると、MyBatis はステートメントを「準備」するための別の要求を TiDB に送信します。これにより、TiDB が多数のプリペアド ステートメントをキャッシュする可能性があり、この方法で SQL 操作を実行すると、インジェクションのセキュリティ リスクが生じます。
動的 SQL バッチ
前述のように JDBC でrewriteBatchedStatements=trueを構成することに加えて、複数のINSERTステートメントをinsert ... values(...), (...), ...の形式に自動的に書き換えることをサポートするために、MyBatis は動的 SQL を使用してバッチ挿入を半自動的に生成することもできます。例として、次のマッパーを取り上げます。
<insert id="insertTestBatch" parameterType="java.util.List" fetchSize="1">
insert into test
(id, v1, v2)
values
<foreach item="item" index="index" collection="list" separator=",">
(
#{item.id}, #{item.v1}, #{item.v2}
)
</foreach>
on duplicate key update v2 = v1 + values(v1)
</insert>
このマッパーはinsert on duplicate key updateステートメントを生成します。次の(?,?,?)の「値」の数は、渡されたリストの数によって決まります。その最終的な効果はrewriteBatchStatements=trueを使用した場合と似ており、クライアントと TiDB 間の通信オーバーヘッドも効果的に削減されます。
前述のように、Prepared Statements は最大長がprepStmtCacheSqlLimitの値を超えるとキャッシュされないことにも注意する必要があります。
ストリーミング結果
前のセクションは、読み取り実行結果を JDBC でストリーミングする方法を紹介します。 JDBC の対応する構成に加えて、MyBatis で非常に大きな結果セットを読み取りたい場合は、次の点にも注意する必要があります。
- マッパー構成で単一の SQL ステートメントに
fetchSizeを設定できます (前のコード ブロックを参照)。その効果は、JDBC でsetFetchSizeを呼び出すことと同等です。 - 結果セット全体を一度に取得することを避けるために、クエリ インターフェイスを
ResultHandlerで使用できます。 - ストリームの読み取りには
Cursorクラスを使用できます。
XML を使用してマッピングを構成する場合、マッピングの<select>セクションでfetchSize="-2147483648" ( Integer.MIN_VALUE ) を構成することにより、読み取り結果をストリーミングできます。
<select id="getAll" resultMap="postResultMap" fetchSize="-2147483648">
select * from post;
</select>
コードを使用してマッピングを構成する場合、 @Options(fetchSize = Integer.MIN_VALUE)アノテーションを追加し、結果のタイプをCursorのままにして、SQL 結果をストリーミングで読み取れるようにすることができます。
@Select("select * from post")
@Options(fetchSize = Integer.MIN_VALUE)
Cursor<Post> queryAllPost();
ExecutorType
openSessionの中からExecutorTypeを選べます。 MyBatis は 3 種類のエグゼキュータをサポートしています。
- シンプル: 実行ごとにプリペアド ステートメントが JDBC に呼び出されます (JDBC 構成アイテム
cachePrepStmtsが有効になっている場合、繰り返されるプリペアド ステートメントが再利用されます)。 - 再利用: 準備済みステートメントは
executorにキャッシュされるため、JDBC を使用せずに準備済みステートメントの重複呼び出しを減らすことができますcachePrepStmts - バッチ: 各更新操作 (
INSERT/DELETE/UPDATE) は最初にバッチに追加され、トランザクションがコミットされるかSELECTクエリが実行されるまで実行されます。 JDBCレイヤーでrewriteBatchStatementsが有効になっている場合、ステートメントを書き換えようとします。そうでない場合、ステートメントは 1 つずつ送信されます。
通常、デフォルト値のExecutorTypeはSimpleです。 openSessionを呼び出すときにExecutorTypeを変更する必要があります。バッチ実行の場合、トランザクションでUPDATE ~ INSERT個のステートメントがかなり高速に実行されることに気付くかもしれませんが、データの読み取り時またはトランザクションのコミット時は遅くなります。これは実際には正常な動作であるため、遅い SQL クエリのトラブルシューティングを行う際には、この点に注意する必要があります。
春の取引
現実の世界では、アプリケーションは春の取引および AOP アスペクトを使用してトランザクションを開始および停止する場合があります。
メソッド定義に@Transactionalアノテーションを追加することで、AOP はメソッドが呼び出される前にトランザクションを開始し、メソッドが結果を返す前にトランザクションをコミットします。アプリケーションに同様のニーズがある場合は、コード内に@Transactionalを見つけて、トランザクションがいつ開始および終了されるかを判断できます。
埋め込みの特殊なケースに注意してください。これが発生した場合、Spring は伝搬構成に基づいて異なる動作をします。
その他
このセクションでは、問題のトラブルシューティングに役立つ Java の便利なツールをいくつか紹介します。
トラブルシューティング ツール
Java アプリケーションで問題が発生し、アプリケーションのロジックがわからない場合は、JVM の強力なトラブルシューティング ツールを使用することをお勧めします。以下に、いくつかの一般的なツールを示します。
jstack
jstackは Go の pprof/goroutine に似ており、プロセスがスタックする問題を簡単にトラブルシューティングできます。
jstack pidを実行すると、対象プロセスの全スレッドの ID とスタック情報を出力できます。デフォルトでは、Java スタックのみが出力されます。 C++ スタックを同時に JVM に出力したい場合は、 -mオプションを追加します。
jstack を複数回使用することで、スタックした問題 (たとえば、Mybatis で Batch ExecutorType を使用するためにアプリケーションのビューからのクエリが遅い) またはアプリケーションのデッドロックの問題 (たとえば、アプリケーションが SQL ステートメントを送信しないなど) を簡単に見つけることができます。送信する前にロックをプリエンプトしています)。
さらに、 top -p $ PID -Hまたは Java スイス ナイフは、スレッド ID を表示する一般的な方法です。また、「スレッドが大量の CPU リソースを占有し、何を実行しているのかわからない」という問題を特定するには、次の手順を実行します。
- スレッド ID を 16 進数に変換するには、
printf "%x\n" pidを使用します。 - jstack 出力に移動して、対応するスレッドのスタック情報を見つけます。
jmap & マット
Go の pprof/heap とは異なり、 jmapプロセス全体のメモリ スナップショットをダンプし (Go では、ディストリビューターのサンプリング)、スナップショットを別のツールで分析できますマット 。
マットを介して、プロセス内のすべてのオブジェクトの関連情報と属性を確認でき、スレッドの実行ステータスも観察できます。たとえば、mat を使用して、現在のアプリケーションに存在する MySQL 接続オブジェクトの数、および各接続オブジェクトのアドレスとステータス情報を確認できます。
デフォルトでは、 mat は到達可能なオブジェクトのみを処理することに注意してください。若い GC の問題をトラブルシューティングする場合は、mat 構成を調整して到達不能オブジェクトを表示できます。さらに、若い GC の問題 (または多数の存続期間の短いオブジェクト) のメモリ割り当てを調査するには、Java Flight Recorder を使用する方が便利です。
痕跡
通常、オンライン アプリケーションはコードの変更をサポートしていませんが、Java で動的計測を実行して問題を特定することが望まれることがよくあります。したがって、btrace または arthas trace を使用することをお勧めします。アプリケーション プロセスを再起動せずに、トレース コードを動的に挿入できます。
フレームグラフ
Java アプリケーションでフレーム グラフを取得するのは面倒です。詳細については、 Java フレーム グラフの紹介: すべての人に火をつけよう!を参照してください。
結論
このドキュメントでは、データベースと対話する一般的に使用される Java コンポーネントに基づいて、TiDB で Java アプリケーションを開発する際の一般的な問題と解決策について説明します。 TiDB は MySQL プロトコルとの互換性が高いため、MySQL ベースの Java アプリケーションのベスト プラクティスのほとんどは TiDB にも適用されます。
TiDB コミュニティ slack チャンネルに参加して、TiDB で Java アプリケーションを開発する際の経験や問題について、広範な TiDB ユーザー グループと共有してください。