TiDB ダッシュボードの診断レポートを使用して問題を特定する
このドキュメントでは、TiDB ダッシュボードの診断レポートを使用して問題を特定する方法を紹介します。
比較診断
このセクションでは、比較診断機能を使用して、大規模なクエリまたは書き込みによって発生する QPS ジッターまたはレイテンシーの増加を診断する方法を示します。
例 1
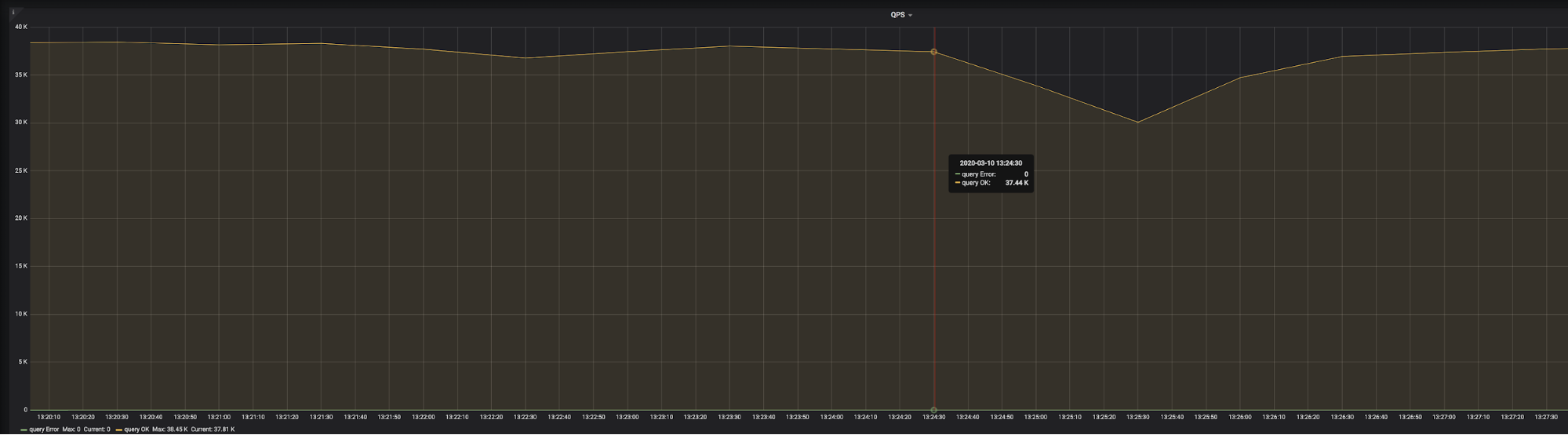
go-ycsb圧力テストの結果を上の画像に示します。 2020-03-10 13:24:30で、QPS が突然減少し始めたことがわかります。 3 分後、QPS は正常に戻り始めました。 TiDB ダッシュボードの診断レポートを使用して、原因を突き止めることができます。
次の 2 つの時間範囲でシステムを比較するレポートを生成します。
T1: 2020-03-10 13:21:00 ~ 2020-03-10 13:23:00 。この範囲では、システムは正常であり、参照範囲と呼ばれます。
T2: 2020-03-10 13:24:30 ~ 2020-03-10 13:27:30 。この範囲で、QPS が減少し始めました。
ジッターの影響範囲は 3 分であるため、上記の 2 つの時間範囲は両方とも 3 分です。一部の監視された平均値は診断時の比較に使用されるため、範囲が長すぎると平均値の差が小さくなり、問題を正確に特定できなくなります。
レポートが生成されたら、このレポートを比較診断ページで表示できます。
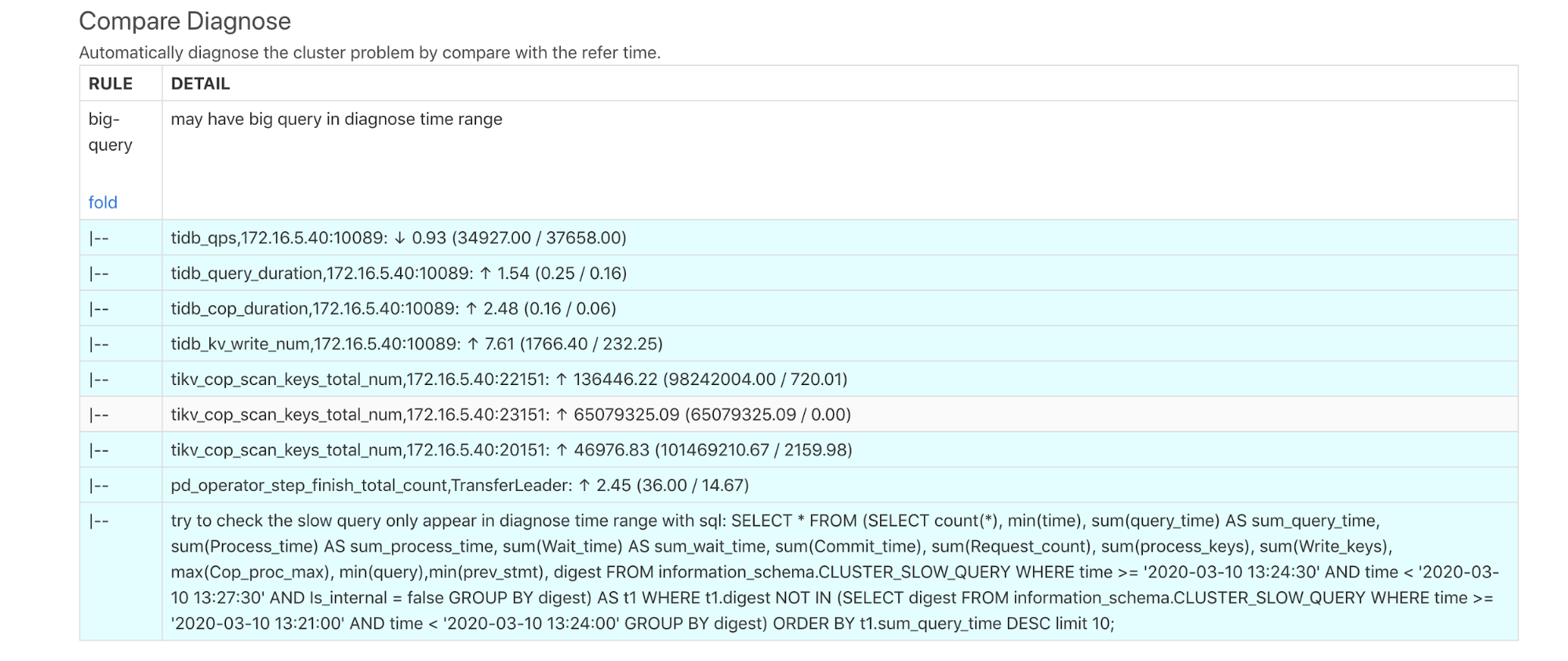
上記の診断結果は、診断時に大きなクエリが存在する可能性があることを示しています。上記のレポートの各DETAILは、次のように説明されています。
tidb_qps: QPS が 0.93 倍減少しました。tidb_query_duration: P999 クエリレイテンシーが 1.54 倍増加しました。tidb_cop_duration: P999 コプロセッサー要求の処理レイテンシーは 2.48 倍増加しました。tidb_kv_write_num: P999 TiDB トランザクションで書き込まれた KV の数が 7.61 倍に増加しました。tikv_cop_scan_keys_total_nun: TiKV コプロセッサーによってスキャンされたキー/値の数は、3 つの TiKV インスタンスで大幅に改善されました。pd_operator_step_finish_total_countでは、リーダーの移動数が 2.45 倍に増加しています。これは、異常な時間帯のスケジューリングが正常な時間帯のスケジューリングよりも高いことを意味します。- このレポートは、低速なクエリが存在する可能性があることを示し、SQL ステートメントを使用して低速なクエリをクエリできることを示しています。 SQL文の実行結果は次のとおりです。
SELECT * FROM (SELECT count(*), min(time), sum(query_time) AS sum_query_time, sum(Process_time) AS sum_process_time, sum(Wait_time) AS sum_wait_time, sum(Commit_time), sum(Request_count), sum(process_keys), sum(Write_keys), max(Cop_proc_max), min(query),min(prev_stmt), digest FROM information_schema.CLUSTER_SLOW_QUERY WHERE time >= '2020-03-10 13:24:30' AND time < '2020-03-10 13:27:30' AND Is_internal = false GROUP BY digest) AS t1 WHERE t1.digest NOT IN (SELECT digest FROM information_schema.CLUSTER_SLOW_QUERY WHERE time >= '2020-03-10 13:21:00' AND time < '2020-03-10 13:24:00' GROUP BY digest) ORDER BY t1.sum_query_time DESC limit 10\G
***************************[ 1. row ]***************************
count(*) | 196
min(time) | 2020-03-10 13:24:30.204326
sum_query_time | 46.878509117
sum_process_time | 265.924
sum_wait_time | 8.308
sum(Commit_time) | 0.926820886
sum(Request_count) | 6035
sum(process_keys) | 201453000
sum(Write_keys) | 274500
max(Cop_proc_max) | 0.263
min(query) | delete from test.tcs2 limit 5000;
min(prev_stmt) |
digest | 24bd6d8a9b238086c9b8c3d240ad4ef32f79ce94cf5a468c0b8fe1eb5f8d03df
上記の結果から、 13:24:30から、合計 46.8 秒で 5,000 行のデータを削除するたびに、合計 196 回実行されたバッチ削除の大規模な書き込みがあることがわかります。
例 2
大規模なクエリが実行されていない場合、そのクエリはスロー ログに記録されません。この状況では、この大規模なクエリを引き続き診断できます。次の例を参照してください。
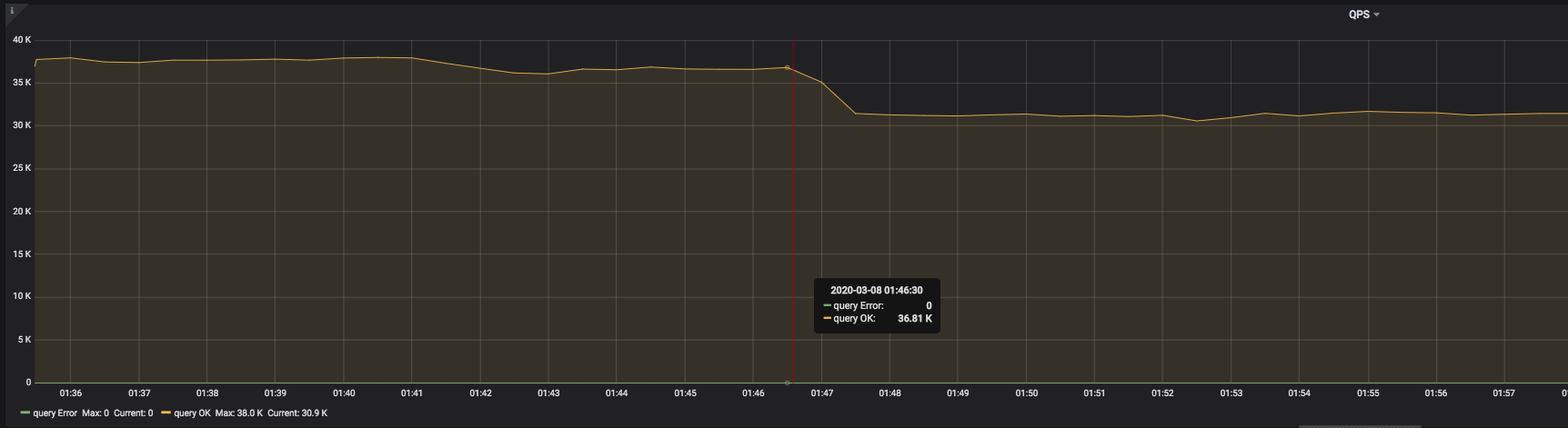
別のgo-ycsbつの圧力テストの結果が上の画像に示されています。 2020-03-08 01:46:30で、QPS が突然低下し始め、回復していないことがわかります。
次の 2 つの時間範囲でシステムを比較するレポートを生成します。
T1: 2020-03-08 01:36:00 ~ 2020-03-08 01:41:00 。この範囲では、システムは正常であり、参照範囲と呼ばれます。
T2: 2020-03-08 01:46:30 ~ 2020-03-08 01:51:30 。この範囲で、QPS が減少し始めました。
レポートが生成されたら、このレポートを比較診断ページで表示できます。
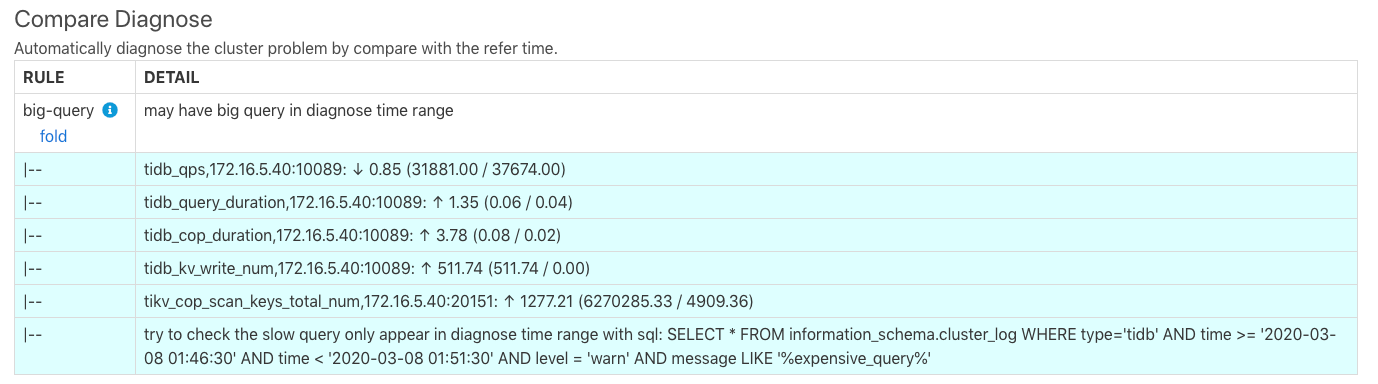
診断結果は、例 1 の結果と同様です。上の画像の最後の行は、低速なクエリが存在する可能性があることを示しており、SQL ステートメントを使用して TiDB ログ内の高価なクエリをクエリできることを示しています。 SQL文の実行結果は以下の通りです。
> SELECT * FROM information_schema.cluster_log WHERE type='tidb' AND time >= '2020-03-08 01:46:30' AND time < '2020-03-08 01:51:30' AND level = 'warn' AND message LIKE '%expensive_query%'\G
TIME | 2020/03/08 01:47:35.846
TYPE | tidb
INSTANCE | 172.16.5.40:4009
LEVEL | WARN
MESSAGE | [expensivequery.go:167] [expensive_query] [cost_time=60.085949605s] [process_time=2.52s] [wait_time=2.52s] [request_count=9] [total_keys=996009] [process_keys=996000] [num_cop_tasks=9] [process_avg_time=0.28s] [process_p90_time=0.344s] [process_max_time=0.344s] [process_max_addr=172.16.5.40:20150] [wait_avg_time=0.000777777s] [wait_p90_time=0.003s] [wait_max_time=0.003s] [wait_max_addr=172.16.5.40:20150] [stats=t_wide:pseudo] [conn_id=19717] [user=root] [database=test] [table_ids="[80,80]"] [txn_start_ts=415132076148785201] [mem_max="23583169 Bytes (22.490662574768066 MB)"] [sql="select count(*) from t_wide as t1 join t_wide as t2 where t1.c0>t2.c1 and t1.c2>0"]
上記のクエリ結果は、この172.16.5.40:4009つの TiDB インスタンスで、 2020/03/08 01:47:35.846に 60 秒間実行された高価なクエリがあることを示していますが、実行はまだ終了していません。このクエリはデカルト積の結合です。
比較診断レポートを使用して問題を特定する
診断が間違っている可能性があるため、比較レポートを使用すると、DBA が問題をより迅速に特定するのに役立つ場合があります。次の例を参照してください。

go-ycsb圧力テストの結果を上の画像に示します。 2020-05-22 22:14:00で、QPS が突然減少し始めたことがわかります。 3 分後、QPS は正常に戻り始めました。 TiDB ダッシュボードの比較診断レポートを使用して、原因を突き止めることができます。
次の 2 つの時間範囲でシステムを比較するレポートを生成します。
T1: 2020-05-22 22:11:00 ~ 2020-05-22 22:14:00 。この範囲では、システムは正常であり、参照範囲と呼ばれます。
T2: 2020-05-22 22:14:00 2020-05-22 22:17:00 .この範囲で、QPS が減少し始めました。
比較レポートを生成したら、 Max diff アイテムレポートを確認します。このレポートは、上記の 2 つの時間範囲の監視項目を比較し、監視項目の違いに従って並べ替えます。この表の結果は次のとおりです。
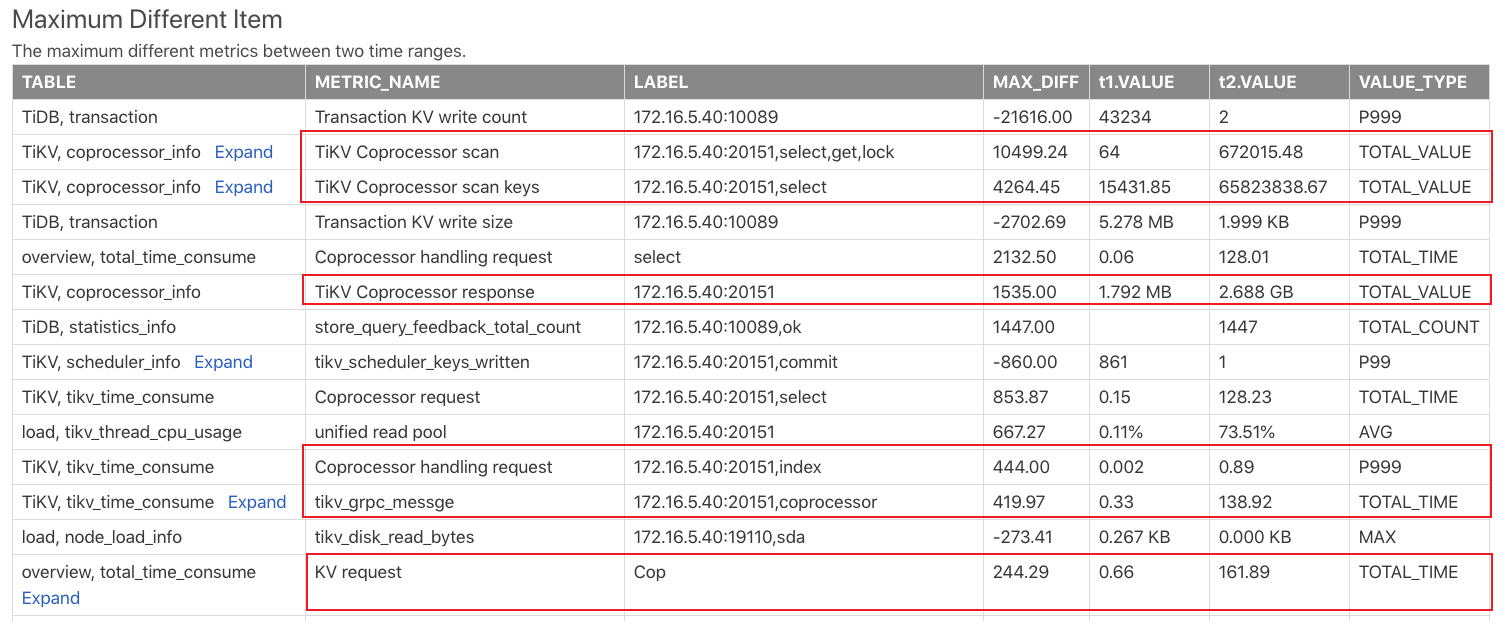
上記の結果から、T2 のコプロセッサー要求が T1 の要求よりもはるかに多いことがわかります。より多くの負荷をもたらすいくつかの大きなクエリが T2 に表示される可能性があります。
実際、T1 から T2 までの時間範囲全体で、 go-ycsb番目の圧力テストが実行されています。次に、T2 の間に 20 tpchのクエリが実行されます。したがって、多くのコプロセッサー要求を引き起こすのはtpchの照会です。
実行時間がスローログのしきい値を超えるような大規模なクエリがスローログに記録された場合。 Slow Queries In Time Range t2のレポートをチェックして、遅いクエリがあるかどうかを確認できます。ただし、T1 の一部のクエリは、T2 では低速のクエリになる可能性があります。これは、T2 では他の負荷によって実行が遅くなるためです。