ホットスポットの問題のトラブルシューティング
このドキュメントでは、ホットスポットの読み取りと書き込みの問題を特定して解決する方法について説明します。
分散データベースとして、TiDBには、サーバーリソースをより有効に活用するために、アプリケーションの負荷をさまざまなコンピューティングノードまたはストレージノードに可能な限り均等に分散する負荷分散メカニズムがあります。ただし、特定のシナリオでは、一部のアプリケーションの負荷を適切に分散できないため、パフォーマンスに影響を与え、ホットスポットとも呼ばれる単一の高負荷ポイントを形成する可能性があります。
TiDBは、ホットスポットのトラブルシューティング、解決、または回避に対する完全なソリューションを提供します。負荷のホットスポットのバランスをとることにより、QPSの改善や遅延の削減など、全体的なパフォーマンスを向上させることができます。
一般的なホットスポット
このセクションでは、TiDBエンコーディングルール、テーブルホットスポット、およびインデックスホットスポットについて説明します。
TiDBエンコーディングルール
TiDBは、TableIDを各テーブルに、IndexIDを各インデックスに、RowIDを各行に割り当てます。デフォルトでは、テーブルが整数の主キーを使用している場合、主キーの値はRowIDとして扱われます。これらのIDの中で、TableIDはクラスタ全体で一意ですが、IndexIDとRowIDはテーブルで一意です。これらすべてのIDのタイプはint64です。
データの各行は、次のルールに従ってキーと値のペアとしてエンコードされます。
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
キーのtablePrefixとrecordPrefixSepは特定の文字列定数であり、KV空間内の他のデータと区別するために使用されます。
インデックスデータの場合、キーと値のペアは次のルールに従ってエンコードされます。
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
インデックスデータには、一意のインデックスと非一意のインデックスの2つのタイプがあります。
一意のインデックスについては、上記のコーディング規則に従うことができます。
一意でないインデックスの場合、同じインデックスの
tablePrefix{tableID}_indexPrefixSep{indexID}つが同じであり、複数の行のColumnsValueが同じである可能性があるため、このエンコーディングを使用して一意のキーを作成することはできません。非一意インデックスのエンコード規則は次のとおりです。Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID Value: null
テーブルのホットスポット
TiDBコーディング規則によれば、同じテーブルのデータは、TableIDの先頭が前に付いた範囲にあり、データはRowID値の順序で配置されます。テーブルの挿入中にRowID値がインクリメントされる場合、挿入された行は末尾にのみ追加できます。リージョンは特定のサイズに達した後に分割されますが、それでも範囲の最後にのみ追加できます。 INSERTの操作は、1つのリージョンでのみ実行でき、ホットスポットを形成します。
一般的な自動インクリメントの主キーは順次増加しています。主キーが整数型の場合、デフォルトでは主キーの値がRowIDとして使用されます。このとき、RowIDは順次増加しており、 INSERT操作が多数存在するとテーブルの書き込みホットスポットが形成されます。
一方、TiDBのRowIDも、デフォルトで順次自動インクリメントされます。主キーが整数型でない場合は、書き込みホットスポットの問題も発生する可能性があります。
ホットスポットのインデックス
インデックスのホットスポットは、テーブルのホットスポットに似ています。一般的なインデックスのホットスポットは、時間順に単調に増加するフィールド、または繰り返し値が多数あるINSERTのシナリオに表示されます。
ホットスポットの問題を特定する
パフォーマンスの問題は必ずしもホットスポットが原因であるとは限らず、複数の要因が原因である可能性があります。問題のトラブルシューティングを行う前に、それがホットスポットに関連しているかどうかを確認してください。
書き込みホットスポットを判断するには、 TiKV-Trouble-Shooting監視パネルでHot Writeを開き、TiKVノードのRaftstoreCPUメトリック値が他のノードのメトリック値よりも大幅に高いかどうかを確認します。
読み取りホットスポットを判断するには、 TiKV-Details監視パネルでThread_CPUを開いて、任意のTiKVノードのコプロセッサーCPUメトリック値が特に高いかどうかを確認します。
TiDBダッシュボードを使用してホットスポットテーブルを見つける
TiDBダッシュボードのキービジュアライザー機能は、ユーザーがホットスポットのトラブルシューティングの範囲をテーブルレベルに絞り込むのに役立ちます。以下は、 KeyVisualizerによって示される熱図の例です。グラフの横軸は時間、縦軸はさまざまな表や索引です。色が明るいほど、負荷が大きくなります。ツールバーで読み取りまたは書き込みフローを切り替えることができます。
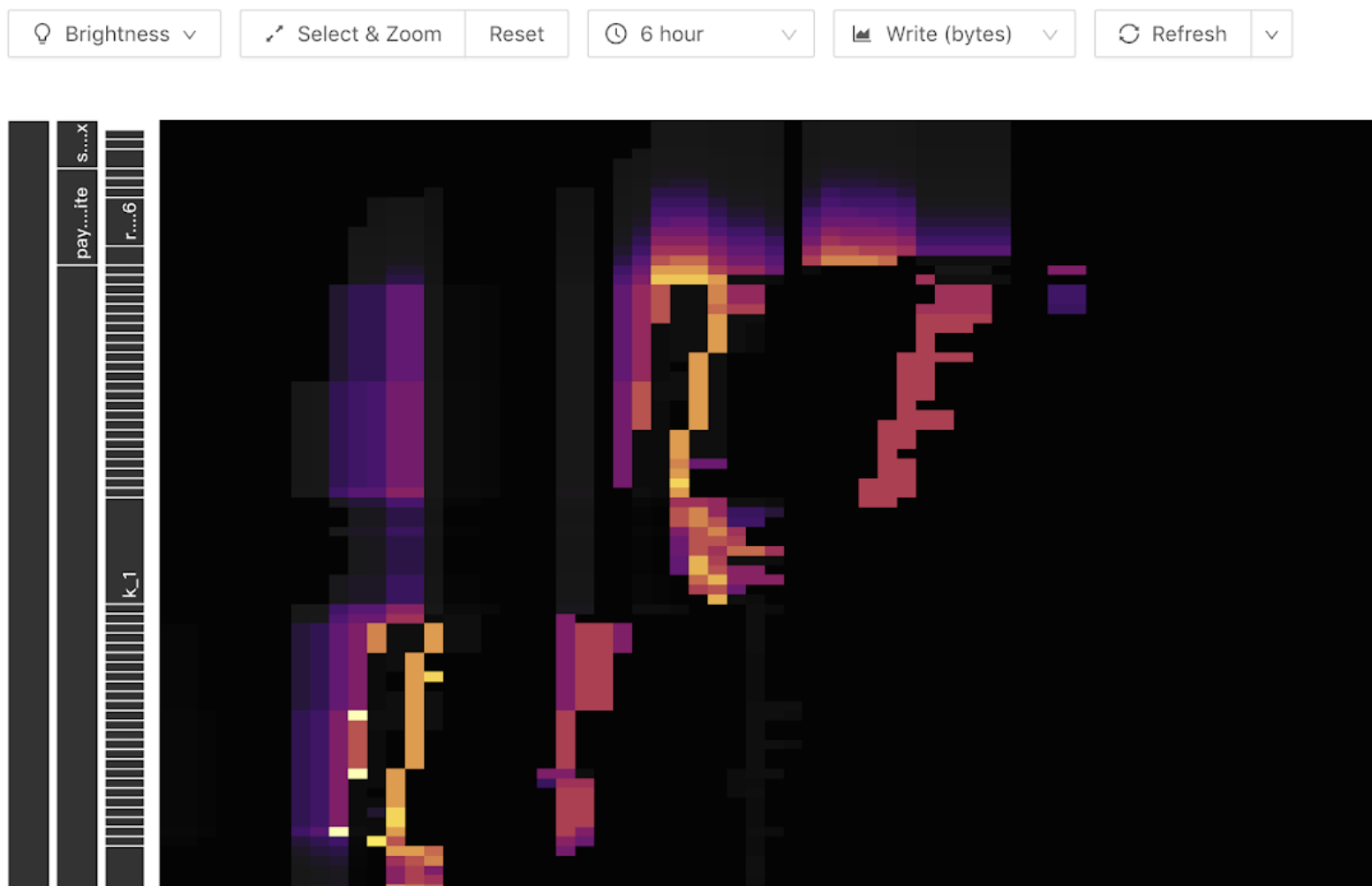
次の明るい対角線(上向きまたは下向きに斜め)が書き込みフローグラフに表示されます。書き込みは最後にしか表示されないため、テーブルリージョンの数が増えると、ラダーとして表示されます。これは、書き込みホットスポットが次の表に表示されていることを示しています。

読み取りホットスポットの場合、通常、熱図に明るい水平線が表示されます。通常、これらは、次のように、アクセス数が多い小さなテーブルが原因で発生します。

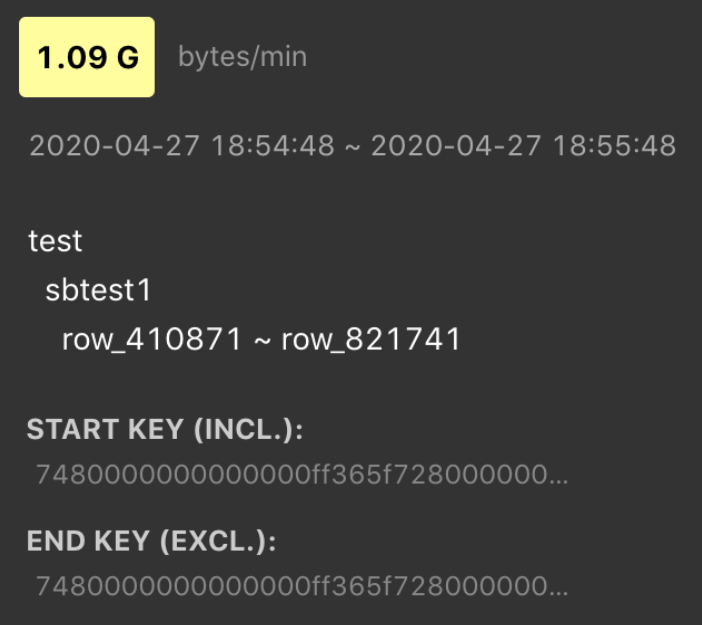
明るいブロックにカーソルを合わせると、どのテーブルまたはインデックスに大きな負荷がかかっているかがわかります。例えば:
SHARD_ROW_ID_BITSを使用してホットスポットを処理します
非整数の主キー、または主キーまたは共同主キーのないテーブルの場合、TiDBは暗黙の自動インクリメントRowIDを使用します。 INSERTの操作が多数存在する場合、データは1つのリージョンに書き込まれるため、書き込みホットスポットが発生します。
SHARD_ROW_ID_BITSを設定すると、行IDが分散して複数のリージョンに書き込まれ、書き込みホットスポットの問題を軽減できます。
SHARD_ROW_ID_BITS = 4 # Represents 16 shards.
SHARD_ROW_ID_BITS = 6 # Represents 64 shards.
SHARD_ROW_ID_BITS = 0 # Represents the default 1 shard.
ステートメントの例:
CREATE TABLE:CREATE TABLE t (c int) SHARD_ROW_ID_BITS = 4;
ALTER TABLE:ALTER TABLE t SHARD_ROW_ID_BITS = 4;
SHARD_ROW_ID_BITSの値は動的に変更できます。変更された値は、新しく書き込まれたデータに対してのみ有効になります。
CLUSTEREDタイプの主キーを持つテーブルの場合、TiDBはテーブルの主キーをRowIDとして使用します。現時点では、RowID生成ルールが変更されるため、 SHARD_ROW_ID_BITSオプションは使用できません。 NONCLUSTEREDタイプの主キーを持つテーブルの場合、TiDBは自動的に割り当てられた64ビット整数をRowIDとして使用します。この場合、 SHARD_ROW_ID_BITS機能を使用できます。 CLUSTEREDタイプの主キーの詳細については、 クラスター化されたインデックスを参照してください。
次の2つの負荷図は、主キーのない2つのテーブルがSHARD_ROW_ID_BITSを使用してホットスポットを分散させる場合を示しています。最初の図はホットスポットを散乱させる前の状況を示し、2番目の図はホットスポットを散乱させた後の状況を示しています。
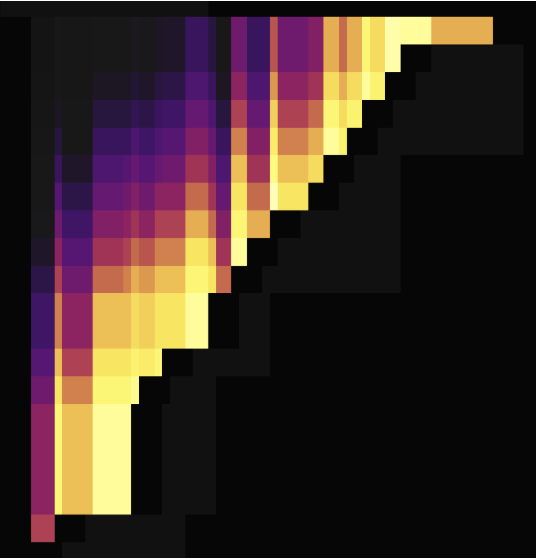
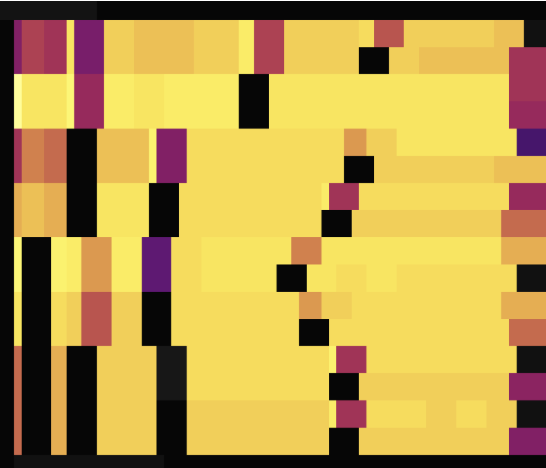
上記の負荷図に示されているように、 SHARD_ROW_ID_BITSを設定する前は、負荷のホットスポットは単一の領域に集中しています。 SHARD_ROW_ID_BITSを設定すると、ロードホットスポットが分散します。
AUTO_RANDOMを使用して自動インクリメントの主キーホットスポットテーブルを処理する
自動インクリメントの主キーによってもたらされる書き込みホットスポットを解決するには、 AUTO_RANDOMを使用して、自動インクリメントの主キーを持つホットスポットテーブルを処理します。
この機能が有効になっている場合、TiDBは、書き込みホットスポットを分散させる目的を達成するために、ランダムに分散され、繰り返されない(スペースが使い果たされる前に)主キーを生成します。
TiDBによって生成された主キーは、主キーの自動インクリメントではなくなり、 LAST_INSERT_ID()を使用して、前回割り当てられた主キーの値を取得できることに注意してください。
この機能を使用するには、 CREATE TABLEステートメントのAUTO_INCREMENTからAUTO_RANDOMを変更します。この機能は、主キーが一意性を保証するだけでよい非アプリケーションシナリオに適しています。
例えば:
CREATE TABLE t (a BIGINT PRIMARY KEY AUTO_RANDOM, b varchar(255));
INSERT INTO t (b) VALUES ("foo");
SELECT * FROM t;
+------------+---+
| a | b |
+------------+---+
| 1073741825 | b |
+------------+---+
SELECT LAST_INSERT_ID();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 1073741825 |
+------------------+
次の2つの負荷図は、ホットスポットを分散させるためにAUTO_INCREMENTからAUTO_RANDOMを変更する前と後の両方の状況を示しています。最初のものはAUTO_INCREMENTを使用し、2番目のものはAUTO_RANDOMを使用します。
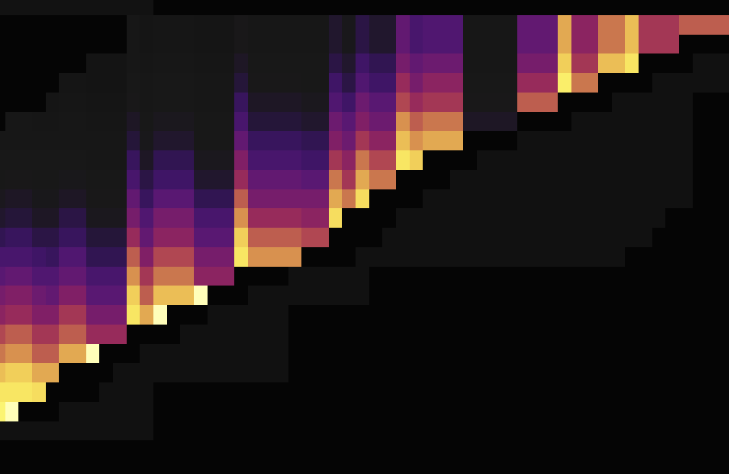

上記の負荷図に示されているように、 AUTO_RANDOMを使用してAUTO_INCREMENTを置き換えると、ホットスポットが分散する可能性があります。
詳細については、 AUTO_RANDOMを参照してください。
小さなテーブルのホットスポットの最適化
TiDBのコプロセッサーキャッシュ機能は、計算結果キャッシュのプッシュダウンをサポートします。この機能を有効にすると、TiDBはTiKVにプッシュダウンされる計算結果をキャッシュします。この機能は、小さなテーブルの読み取りホットスポットに適しています。
詳細については、 コプロセッサーキャッシュを参照してください。
参照: