TiDBコンピューティング
TiKVが提供する分散ストレージに基づいて、TiDBは、トランザクション処理の優れた機能とデータ分析の優れた機能を組み合わせたコンピューティングエンジンを構築します。このドキュメントでは、TiDBデータベーステーブルのデータをTiKVの(キー、値)キーと値のペアにマッピングするデータマッピングアルゴリズムを紹介し、次にTiDBがメタデータを管理する方法を紹介し、最後にTiDBSQLレイヤーのアーキテクチャを示します。
コンピューティングレイヤーが依存するストレージソリューションの場合、このドキュメントでは、TiKVの行ベースのストレージ構造のみを紹介します。 OLAPサービスの場合、TiDBは列ベースのストレージソリューションTiFlashをTiKV拡張機能として導入します。
テーブルデータのKey-Valueへのマッピング
このセクションでは、TiDBの(キー、値)キーと値のペアにデータをマッピングするためのスキームについて説明します。ここでマッピングされるデータには、次の2つのタイプが含まれます。
- 表の各行のデータ。以降、表データと呼びます。
- 表内のすべてのインデックスのデータ。以下、インデックスデータと呼びます。
テーブルデータのKey-Valueへのマッピング
リレーショナルデータベースでは、テーブルに多くの列が含まれる場合があります。行の各列のデータを(キー、値)キーと値のペアにマップするには、キーの作成方法を検討する必要があります。まず、OLTPシナリオでは、単一または複数の行のデータの追加、削除、変更、検索などの多くの操作があり、データベースがデータの行をすばやく読み取る必要があります。したがって、すばやく見つけられるように、各キーには一意のID(明示的または暗黙的)が必要です。次に、多くのOLAPクエリで全表スキャンが必要になります。テーブル内のすべての行のキーを範囲にエンコードできる場合は、範囲クエリによってテーブル全体を効率的にスキャンできます。
上記の考慮事項に基づいて、TiDBのKey-Valueへのテーブルデータのマッピングは次のように設計されています。
- 同じテーブルのデータをまとめて検索しやすくするために、TiDBは
TableIDで表される各テーブルにテーブルIDを割り当てます。テーブルIDは、クラスタ全体で一意の整数です。 - TiDBは、テーブル内のデータの各行に
RowIDで表される行IDを割り当てます。行IDも整数であり、テーブル内で一意です。行IDについては、TiDBが小さな最適化を行いました。テーブルに整数型の主キーがある場合、TiDBはこの主キーの値を行IDとして使用します。
データの各行は、次のルールに従って(キー、値)キーと値のペアとしてエンコードされます。
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
tablePrefixとrecordPrefixSepはどちらも、キースペース内の他のデータを区別するために使用される特別な文字列定数です。文字列定数の正確な値はマッピング関係の要約で紹介されています。
インデックス付きデータのKey-Valueへのマッピング
TiDBは、主キーとセカンダリインデックス(一意のインデックスと一意でないインデックスの両方)の両方をサポートします。テーブルデータマッピングスキームと同様に、TiDBはIndexIDで表されるテーブルの各インデックスにインデックスIDを割り当てます。
主キーと一意のインデックスの場合、キーと値のペアに基づいて対応するRowIDをすばやく見つける必要があるため、このようなキーと値のペアは次のようにエンコードされます。
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
一意性の制約を満たす必要のない通常のセカンダリインデックスの場合、単一のキーが複数の行に対応する場合があります。キーの範囲に応じて、対応するRowIDを照会する必要があります。したがって、キーと値のペアは、次のルールに従ってエンコードする必要があります。
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null
マッピング関係の要約
上記のすべてのエンコード規則のtablePrefix 、およびrecordPrefixSepは、KVをキースペース内の他のデータと区別するために使用される文字列定数であり、次のように定義されindexPrefixSep 。
tablePrefix = []byte{'t'}
recordPrefixSep = []byte{'r'}
indexPrefixSep = []byte{'i'}
また、上記のエンコーディングスキームでは、テーブルデータまたはインデックスデータのキーエンコーディングスキームに関係なく、テーブル内のすべての行に同じキープレフィックスがあり、インデックスのすべてのデータにも同じプレフィックスがあることに注意してください。したがって、同じプレフィックスを持つデータは、TiKVのキースペースに一緒に配置されます。したがって、サフィックス部分のエンコード方式を注意深く設計して、エンコード前とエンコード後の比較が同じになるようにすることで、テーブルデータまたはインデックスデータを順序付けられた方法でTiKVに格納できます。このエンコード方式を使用すると、テーブル内のすべての行データがTiKVのキースペースにRowIDずつ順番に配置され、特定のインデックスのデータも、インデックスデータの特定の値に従ってキースペースに順番に配置されます( indexedColumnsValue )。
Key-Valueマッピング関係の例
このセクションでは、TiDBのキーと値のマッピング関係を理解するための簡単な例を示します。次のテーブルがTiDBに存在するとします。
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);
テーブルに3行のデータがあるとします。
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
データの各行は(キー、値)キーと値のペアにマップされ、テーブルにはintタイプの主キーがあるため、値RowIDがこの主キーの値になります。テーブルのTableIDが10で、TiKVに保存されているテーブルデータが次のようになっているとします。
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", " Manager", 30]
主キーに加えて、テーブルには一意ではない通常の2次インデックスidxAgeがあります。 IndexIDが1で、TiKVに保存されているインデックスデータが次のようになっているとします。
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
上記の例は、TiDBのリレーショナルモデルからKey-Valueモデルへのマッピングルールと、このマッピングスキームの背後にある考慮事項を示しています。
メタデータ管理
TiDBの各データベースとテーブルには、その定義とさまざまな属性を示すメタデータがあります。この情報も永続化する必要があり、TiDBはこの情報をTiKVにも保存します。
各データベースまたはテーブルには、一意のIDが割り当てられます。一意の識別子として、テーブルデータがKey-Valueにエンコードされる場合、このIDはプレフィックスがm_のキーにエンコードされます。これにより、シリアル化されたメタデータが格納されたキーと値のペアが構築されます。
さらに、TiDBは、専用の(Key、Value)キーと値のペアを使用して、すべてのテーブルの構造情報の最新バージョン番号を格納します。このキーと値のペアはグローバルであり、そのバージョン番号は、DDL操作の状態が変化するたびに1ずつ増加します。 TiDBは、このキーと値のペアを/tidb/ddl/global_schema_versionのキーでPDサーバーに永続的に保存し、Valueはint64タイプのバージョン番号の値です。一方、TiDBはスキーマの変更をオンラインで適用するため、PDサーバーに格納されているテーブル構造情報のバージョン番号が変更されているかどうかを常にチェックするバックグラウンドスレッドを保持します。このスレッドはまた、バージョンの変更が一定期間内に取得できることを保証します。
SQLレイヤーの概要
TiDBのSQLレイヤーであるTiDBサーバーは、SQLステートメントをKey-Value操作に変換し、操作を分散Key-ValueストレージレイヤーであるTiKVに転送し、TiKVから返された結果をアセンブルし、最後にクエリ結果をクライアントに返します。
このレイヤーのノードはステートレスです。これらのノード自体はデータを格納せず、完全に同等です。
SQLコンピューティング
SQLコンピューティングの最も簡単なソリューションは、前のセクションで説明したテーブルデータのKey-Valueへのマッピングです。これは、SQLクエリをKVクエリにマップし、KVインターフェイスを介して対応するデータを取得し、さまざまな計算を実行します。
たとえば、 select count(*) from user where name = "TiDB" SQLステートメントを実行するには、TiDBはテーブル内のすべてのデータを読み取り、 nameフィールドがTiDBであるかどうかを確認し、そうである場合はこの行を返す必要があります。プロセスは次のとおりです。
- キー範囲を作成します。テーブル内の
RowIDすべてが[0, MaxInt64)の範囲にあります。行データKeyのエンコード規則によれば、0とMaxInt64を使用すると、左クローズと右オープンの[StartKey, EndKey)範囲を構築できます。 - キー範囲のスキャン:上記で作成したキー範囲に従ってTiKVのデータを読み取ります。
- データのフィルター処理:読み取られたデータの各行について、
name = "TiDB"の式を計算します。結果がtrueの場合は、この行に戻ります。そうでない場合は、この行をスキップしてください。 Count(*)を計算します。要件を満たす行ごとに、Count(*)の結果を合計します。
プロセス全体を次のように示します。
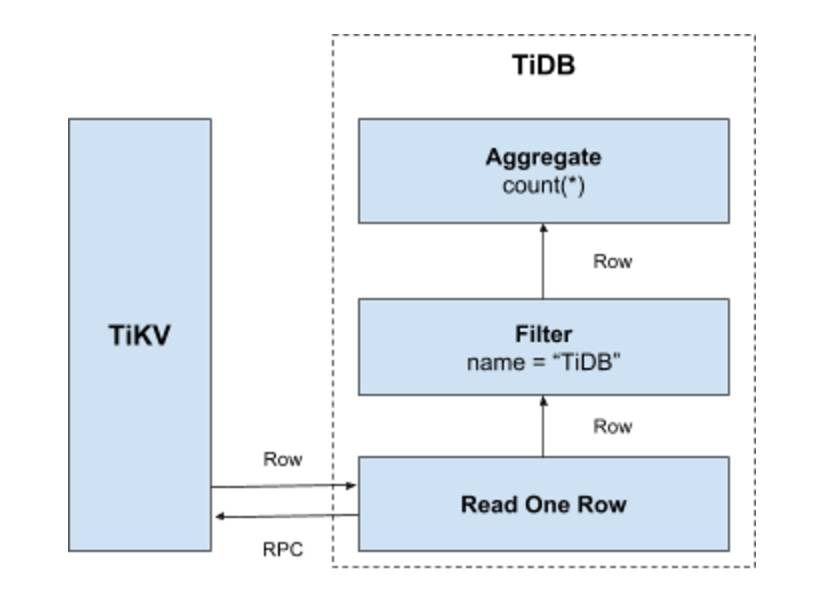
このソリューションは直感的で実行可能ですが、分散データベースのシナリオでは明らかな問題がいくつかあります。
- データがスキャンされると、各行は、少なくとも1つのRPCオーバーヘッドを伴うKV操作を介してTiKVから読み取られます。これは、スキャンするデータが大量にある場合に非常に高くなる可能性があります。
- すべての行に適用できるわけではありません。条件を満たさないデータを読み取る必要はありません。
- このクエリの返された結果から、要件に一致する行の数だけが必要であり、それらの行の値は必要ありません。
分散SQL操作
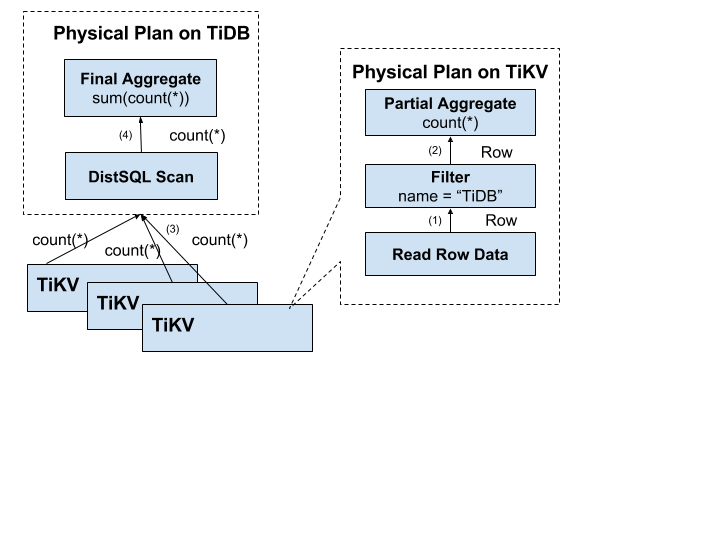
上記の問題を解決するには、RPC呼び出しの数が多くなるのを避けるために、計算をストレージノードにできるだけ近づける必要があります。まず、SQL述語条件name = "TiDB"を計算のためにストレージノードにプッシュダウンして、有効な行のみが返されるようにする必要があります。これにより、意味のないネットワーク転送が回避されます。次に、集約関数Count(*)を事前集約のためにストレージノードにプッシュダウンすることもでき、各ノードはCount(*)の結果を返すだけで済みます。 SQLレイヤーは、各ノードから返されたCount(*)の結果を合計します。
次の画像は、データがレイヤーごとにどのように返されるかを示しています。
SQLレイヤーのアーキテクチャ
前のセクションではSQLレイヤーのいくつかの機能を紹介しましたが、SQLステートメントの処理方法について基本的な知識を持っていることを願っています。実際、TiDBのSQLレイヤーははるかに複雑で、多くのモジュールとレイヤーがあります。次の図は、重要なモジュールと呼び出し関係を示しています。

ユーザーのSQL要求は、直接またはLoad Balancerを介してTiDBサーバーに送信されます。 TiDBサーバーはMySQL Protocol Packetを解析し、リクエストのコンテンツを取得し、SQLリクエストを構文的および意味的に解析し、クエリプランを開発および最適化し、クエリプランを実行し、データを取得および処理します。すべてのデータはTiKVクラスタに保存されるため、このプロセスでは、TiDBサーバーがTiKVと対話してデータを取得する必要があります。最後に、TiDBサーバーはクエリ結果をユーザーに返す必要があります。