2つの都市に配置された3つのデータセンター
このドキュメントでは、2つの都市の展開における3つのデータセンター(DC)のアーキテクチャと構成を紹介します。
概要
2つの都市にある3つのDCのアーキテクチャは、本番データセンター、同じ都市のディザスタリカバリセンター、および別の都市のディザスタリカバリセンターを提供する、可用性と耐災害性の高い展開ソリューションです。このモードでは、2つの都市の3つのDCが相互接続されます。 1つのDCに障害が発生したり、災害が発生した場合でも、他のDCは正常に動作し、主要なアプリケーションまたはすべてのアプリケーションを引き継ぐことができます。 1つの都市展開でのマルチDCと比較すると、このソリューションには、都市間の高可用性という利点があり、都市レベルの自然災害に耐えることができます。
分散データベースTiDBは、Raftアルゴリズムを使用して2都市の3 DCアーキテクチャをネイティブにサポートし、データベースクラスタ内のデータの一貫性と高可用性を保証します。同じ都市のDC間のネットワーク遅延は比較的低いため、アプリケーショントラフィックを同じ都市の2つのDCにディスパッチでき、TiKVリージョンリーダーとPDリーダーの分散を制御することでトラフィック負荷をこれら2つのDCで共有できます。 。
デプロイメントアーキテクチャ
このセクションでは、シアトルとサンフランシスコの例を取り上げて、TiDBの分散データベースの2つの都市における3つのDCの展開モードについて説明します。
この例では、2つのDC(IDC1とIDC2)がシアトルにあり、もう1つのDC(IDC3)がサンフランシスコにあります。 IDC1とIDC2の間のネットワーク遅延は3ミリ秒未満です。シアトルのIDC3とIDC1/IDC2の間のネットワーク遅延は約20ミリ秒です(ISP専用ネットワークが使用されます)。
クラスタデプロイメントのアーキテクチャは次のとおりです。
- TiDBクラスタは、シアトルのIDC1、シアトルのIDC2、サンフランシスコのIDC3の2つの都市の3つのDCに展開されます。
- クラスタには5つのレプリカがあり、2つはIDC1に、2つはIDC2に、1つはIDC3にあります。 TiKVコンポーネントの場合、各ラックにはラベルがあります。これは、各ラックにレプリカがあることを意味します。
- Raftプロトコルは、データの一貫性と高可用性を確保するために採用されており、ユーザーには透過的です。
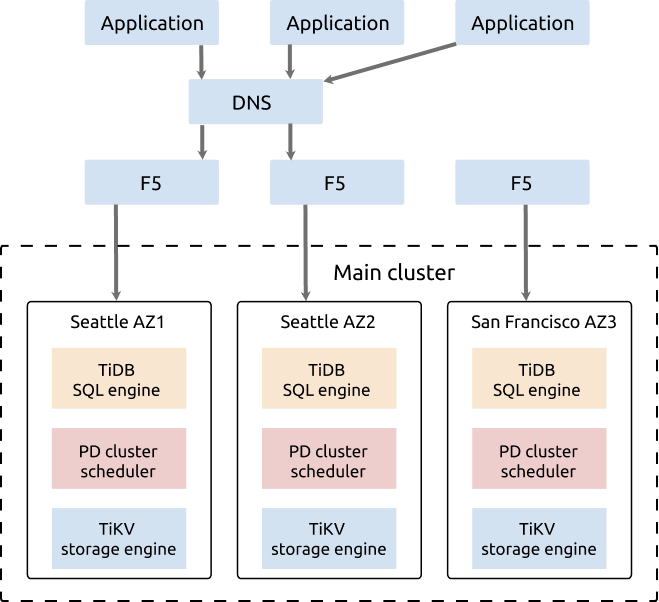
このアーキテクチャは高可用性です。リージョンリーダーの配布は、同じ都市(シアトル)にある2つのDC(IDC1とIDC2)に制限されています。リージョンリーダーの分散が制限されていない3DCソリューションと比較すると、このアーキテクチャには次の長所と短所があります。
利点
- リージョンリーダーは同じ都市のDCにいて、レイテンシが低いため、書き込みが高速になります。
- 2つのDCは同時にサービスを提供できるため、リソース使用率が高くなります。
- 1つのDCに障害が発生しても、サービスは引き続き利用可能であり、データの安全性が確保されます。
短所
- データの一貫性はRaftアルゴリズムによって実現されるため、同じ都市の2つのDCに同時に障害が発生した場合、別の都市(サンフランシスコ)のディザスタリカバリDCに残っているレプリカは1つだけです。これは、ほとんどのレプリカが存続するRaftアルゴリズムの要件を満たすことができません。その結果、クラスタが一時的に使用できなくなる可能性があります。メンテナンススタッフは、残っている1つのレプリカからクラスタを回復する必要があり、複製されていない少量のホットデータが失われます。しかし、このケースはまれなケースです。
- ISP専用のネットワークを使用しているため、このアーキテクチャのネットワークインフラストラクチャには高いコストがかかります。
- 2つの都市の3つのDCに5つのレプリカが構成されているため、データの冗長性が高まり、ストレージコストが高くなります。
展開の詳細
2つの都市(シアトルとサンフランシスコ)の展開計画における3つのDCの構成は、次のように示されています。
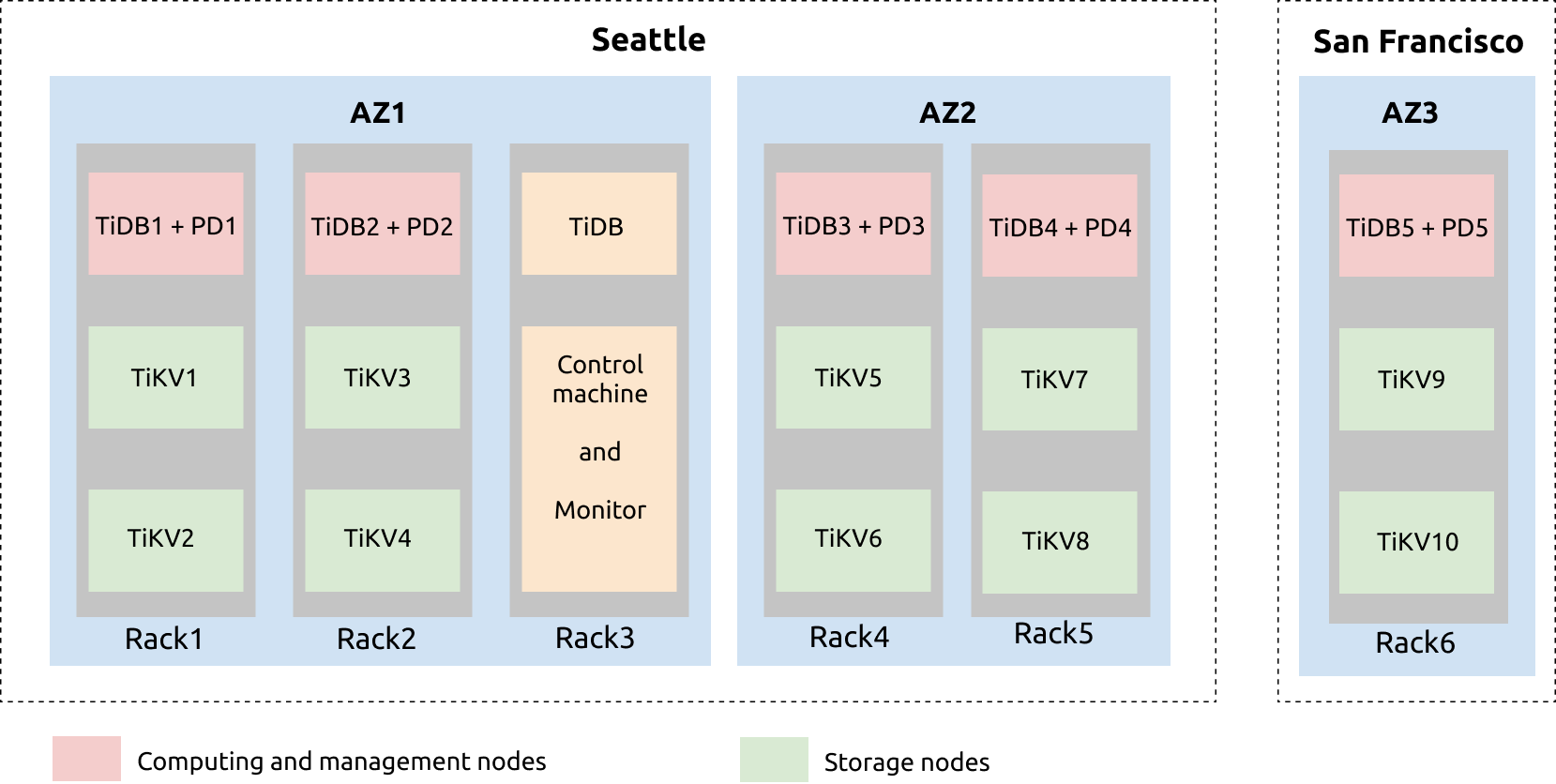
- 上の図から、シアトルにはIDC1とIDC2の2つのDCがあることがわかります。 IDC1には、RAC1、RAC2、およびRAC3の3セットのラックがあります。 IDC2には、RAC4とRAC5の2つのラックがあります。サンフランシスコのIDC3DCにはRAC6ラックがあります。
- 上記のRAC1ラックから、TiDBサービスとPDサービスが同じサーバーに展開されます。 2つのTiKVサーバーのそれぞれは、2つのTiKVインスタンス(tikv-server)とともにデプロイされます。これは、RAC2、RAC4、RAC5、およびRAC6に似ています。
- TiDBサーバー、制御マシン、および監視サーバーはRAC3上にあります。 TiDBサーバーは、定期的なメンテナンスとバックアップのために展開されます。 Prometheus、Grafana、および復元ツールは、制御マシンと監視マシンにデプロイされます。
- Drainerをデプロイするために、別のバックアップサーバーを追加できます。 Drainerは、ファイルを出力してbinlogデータを指定された場所に保存し、増分バックアップを実現します。
Configuration / コンフィグレーション
例
たとえば、次のtiup topology.yamlつのyamlファイルを参照してください。
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb_cluster/tidb-deploy"
data_dir: "/data/tidb_cluster/tidb-data"
server_configs:
tikv:
server.grpc-compression-type: gzip
pd:
replication.location-labels: ["dc","zone","rack","host"]
schedule.tolerant-size-ratio: 20.0
pd_servers:
- host: 10.63.10.10
name: "pd-10"
- host: 10.63.10.11
name: "pd-11"
- host: 10.63.10.12
name: "pd-12"
- host: 10.63.10.13
name: "pd-13"
- host: 10.63.10.14
name: "pd-14"
tidb_servers:
- host: 10.63.10.10
- host: 10.63.10.11
- host: 10.63.10.12
- host: 10.63.10.13
- host: 10.63.10.14
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { dc: "1", zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { dc: "1", zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { dc: "2", zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { dc: "2", zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { dc: "3", zone: "5", rack: "5", host: "34" }
raftstore.raft-min-election-timeout-ticks: 1000
raftstore.raft-max-election-timeout-ticks: 1200
monitoring_servers:
- host: 10.63.10.60
grafana_servers:
- host: 10.63.10.60
alertmanager_servers:
- host: 10.63.10.60
ラベルデザイン
2つの都市に3つのDCを展開する場合、ラベルの設計では、可用性と災害復旧を考慮する必要があります。デプロイメントの物理構造に基づいて、 zone hostのレベル( dc )を定義することをお勧めしrack 。
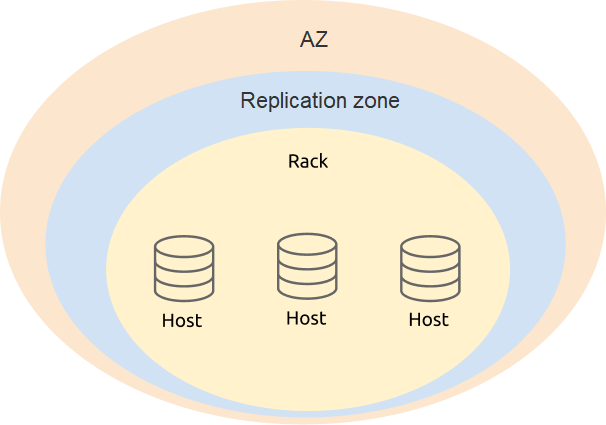
PD構成で、TiKVラベルのレベル情報を追加します。
server_configs:
pd:
replication.location-labels: ["dc","zone","rack","host"]
tikv_serversの構成は、TiKVの実際の物理展開場所のラベル情報に基づいているため、PDはグローバルな管理とスケジューリングを簡単に実行できます。
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { dc: "1", zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { dc: "1", zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { dc: "2", zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { dc: "2", zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { dc: "3", zone: "5", rack: "5", host: "34" }
パラメータ設定を最適化する
2つの都市に3つのDCを展開する場合、パフォーマンスを最適化するには、通常のパラメーターを構成するだけでなく、コンポーネントのパラメーターも調整する必要があります。
TiKVでgRPCメッセージ圧縮を有効にします。クラスタのデータはネットワークで送信されるため、gRPCメッセージ圧縮を有効にしてネットワークトラフィックを減らすことができます。
server.grpc-compression-type: gzipPDバランスバッファサイズを調整し、PDの許容範囲を増やします。 PDは、ノードの状況に応じて各オブジェクトのスコアをスケジューリングの基準として計算するため、2つのストアのリーダー(またはリージョン)のスコアの差が、指定されたリージョンサイズの倍数よりも小さい場合、PDはバランスが取れています。
schedule.tolerant-size-ratio: 20.0別の都市(サンフランシスコ)のTiKVノードのネットワーク構成を最適化します。サンフランシスコのIDC3(単独)の次のTiKVパラメーターを変更し、このTiKVノードのレプリカがラフト選挙に参加しないようにします。
raftstore.raft-min-election-timeout-ticks: 1000 raftstore.raft-max-election-timeout-ticks: 1200スケジューリングを構成します。クラスタを有効にした後、
tiup ctl pdツールを使用してスケジューリングポリシーを変更します。 TiKVRaftレプリカの数を変更します。この番号を計画どおりに構成します。この例では、レプリカの数は5です。config set max-replicas 5ラフトリーダーをIDC3にスケジュールすることを禁止します。ラフトリーダーを別の都市(IDC3)にスケジュールすると、シアトルのIDC1/IDC2とサンフランシスコのIDC3の間に不要なネットワークオーバーヘッドが発生します。ネットワーク帯域幅と遅延もTiDBクラスタのパフォーマンスに影響します。
config set label-property reject-leader dc 3ノート:
TiDB 5.2以降、
label-property構成はデフォルトでサポートされていません。レプリカポリシーを設定するには、 配置ルールを使用します。PDの優先度を設定します。 PDリーダーが別の都市(IDC3)にいる状況を回避するには、ローカルPD(シアトル)の優先度を上げ、別の都市(サンフランシスコ)のPDの優先度を下げることができます。数値が大きいほど、優先度が高くなります。
member leader_priority PD-10 5 member leader_priority PD-11 5 member leader_priority PD-12 5 member leader_priority PD-13 5 member leader_priority PD-14 1