TiDBを使用してJavaアプリケーションを開発するためのベストプラクティス
このドキュメントでは、TiDBをより有効に使用するためのJavaアプリケーションを開発するためのベストプラクティスを紹介します。このドキュメントは、バックエンドTiDBデータベースと相互作用するいくつかの一般的なJavaアプリケーションコンポーネントに基づいて、開発中に一般的に発生する問題の解決策も提供します。
Javaアプリケーションのデータベース関連コンポーネント
JavaアプリケーションでTiDBデータベースと対話する一般的なコンポーネントは次のとおりです。
- ネットワークプロトコル:クライアントは、標準MySQLプロトコルを介してTiDBサーバーと対話します。
- JDBC APIおよびJDBCドライバー:Javaアプリケーションは通常、標準のJDBC(Javaデータベースコネクティビティ)を使用してデータベースにアクセスします。 TiDBに接続するには、JDBCAPIを介してMySQLプロトコルを実装するJDBCドライバーを使用できます。 MySQL用のこのような一般的なJDBCドライバーには、 MySQLコネクタ/JとMariaDBコネクタ/Jが含まれます。
- データベース接続プール:要求されるたびに接続を作成するオーバーヘッドを削減するために、アプリケーションは通常、接続プールを使用して接続をキャッシュおよび再利用します。 JDBC 情報源は、接続プールAPIを定義します。必要に応じて、さまざまなオープンソース接続プールの実装から選択できます。
- データアクセスフレームワーク:アプリケーションは通常、 MyBatisやHibernateなどのデータアクセスフレームワークを使用して、データベースアクセス操作をさらに簡素化および管理します。
- アプリケーションの実装:アプリケーションロジックは、データベースにどのコマンドを送信するかを制御します。一部のアプリケーションは、 春のトランザクションの側面を使用して、トランザクションの開始ロジックとコミットロジックを管理します。
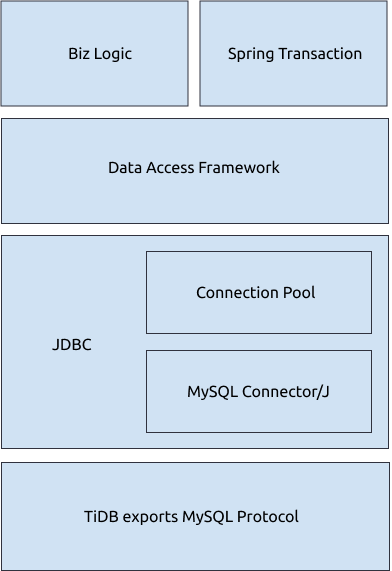
上の図から、Javaアプリケーションが次のことを実行する可能性があることがわかります。
- JDBC APIを介してMySQLプロトコルを実装し、TiDBと対話します。
- 接続プールから持続的接続を取得します。
- MyBatisなどのデータアクセスフレームワークを使用して、SQLステートメントを生成および実行します。
- Spring Transactionを使用して、トランザクションを自動的に開始または停止します。
このドキュメントの残りの部分では、上記のコンポーネントを使用してJavaアプリケーションを開発する際の問題とその解決策について説明します。
JDBC
Javaアプリケーションは、さまざまなフレームワークでカプセル化できます。ほとんどのフレームワークでは、JDBC APIは、データベースサーバーと対話するために最下位レベルで呼び出されます。 JDBCの場合、次のことに焦点を当てることをお勧めします。
- JDBCAPIの使用法の選択
- API実装者のパラメーター構成
JDBC API
JDBC APIの使用法については、 JDBC公式チュートリアルを参照してください。このセクションでは、いくつかの重要なAPIの使用法について説明します。
準備APIを使用する
OLTP(Online Transactional Processing)シナリオの場合、プログラムによってデータベースに送信されるSQLステートメントは、パラメーターの変更を削除した後に使い果たされる可能性のあるいくつかのタイプです。したがって、通常のテキストファイルからの実行ではなくプリペアドステートメントを使用し、PreparedStatementsを再利用して直接実行することをお勧めします。これにより、TiDBでSQL実行プランを繰り返し解析および生成するオーバーヘッドが回避されます。
現在、ほとんどの上位レベルのフレームワークは、SQL実行のために準備APIを呼び出します。開発にJDBCAPIを直接使用する場合は、PrepareAPIの選択に注意してください。
さらに、MySQL Connector / Jのデフォルトの実装では、クライアント側のステートメントのみが前処理され、クライアントで?が置き換えられた後、ステートメントはテキストファイルでサーバーに送信されます。したがって、Prepare APIを使用することに加えて、TiDBサーバーでステートメントの前処理を実行する前に、JDBC接続パラメーターでuseServerPrepStmts = trueを構成する必要もあります。パラメータ設定の詳細については、 MySQLJDBCパラメータを参照してください。
バッチAPIを使用する
バッチ挿入の場合は、 addBatch / executeBatch APIを使用できます。 addBatch()メソッドは、最初にクライアントで複数のSQLステートメントをキャッシュし、次にexecuteBatchメソッドを呼び出すときにそれらをデータベースサーバーに一緒に送信するために使用されます。
ノート:
デフォルトのMySQLConnector/ J実装では、
addBatch()でバッチに追加されたSQLステートメントの送信時間は、executeBatch()が呼び出された時間まで遅延しますが、実際のネットワーク転送中にステートメントは1つずつ送信されます。したがって、この方法では通常、通信のオーバーヘッドを減らすことはできません。ネットワーク転送をバッチ処理する場合は、JDBC接続パラメーターで
rewriteBatchedStatements = trueを構成する必要があります。詳細なパラメータ設定については、 バッチ関連のパラメーターを参照してください。
StreamingResultを使用して実行結果を取得します
ほとんどのシナリオでは、実行効率を向上させるために、JDBCは事前にクエリ結果を取得し、デフォルトでクライアントメモリに保存します。ただし、クエリが非常に大きな結果セットを返す場合、クライアントはデータベースサーバーに一度に返されるレコードの数を減らしてもらい、クライアントのメモリの準備ができて次のバッチを要求するまで待機することがよくあります。
通常、JDBCには2種類の処理方法があります。
FetchSizeをInteger.MIN_VALUEに設定しますは、クライアントがキャッシュしないようにします。クライアントは、StreamingResultを介してネットワーク接続から実行結果を読み取ります。クライアントがストリーミング読み取りメソッドを使用する場合、ステートメントを使用してクエリを実行し続ける前に、読み取りを終了するか、
resultsetを閉じる必要があります。それ以外の場合は、エラーNo statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.が返されます。クライアントが読み取りを終了するか
resultsetを閉じる前にクエリでこのようなエラーを回避するために、URLにclobberStreamingResults=trueパラメータを追加できます。次に、resultsetは自動的に閉じられますが、前のストリーミングクエリで読み取られる結果セットは失われます。カーソルフェッチを使用するには、最初に
FetchSizeを設定しますを正の整数として使用し、JDBCURLでuseCursorFetch=trueを構成します。
TiDBは両方の方法をサポートしていますが、実装が単純で実行効率が高いため、最初の方法を使用することをお勧めします。
MySQLJDBCパラメータ
JDBCは通常、実装関連の構成をJDBCURLパラメーターの形式で提供します。このセクションではMySQL Connector/Jのパラメータ構成を紹介します(MariaDBを使用する場合は、 MariaDBのパラメーター構成を参照してください)。このドキュメントはすべての構成項目を網羅しているわけではないため、パフォーマンスに影響を与える可能性のあるいくつかのパラメーターに主に焦点を当てています。
関連するパラメータを準備する
このセクションでは、 Prepareに関連するパラメーターを紹介します。
useServerPrepStmts
デフォルトではuseServerPrepStmtsがfalseに設定されています。つまり、Prepare APIを使用している場合でも、「prepare」操作はクライアントでのみ実行されます。サーバーの解析オーバーヘッドを回避するために、同じSQLステートメントがPrepare APIを複数回使用する場合は、この構成をtrueに設定することをお勧めします。
この設定がすでに有効になっていることを確認するには、次のようにします。
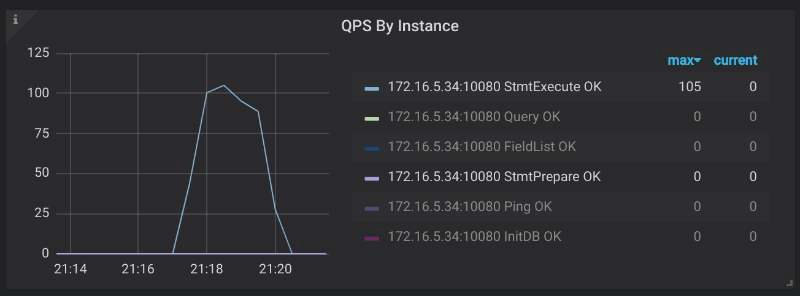
- TiDBモニタリングダッシュボードに移動し、[ Query Summary ]> [ QPSByInstance ]からリクエストコマンドタイプを表示します。
- リクエストで
COM_QUERYがCOM_STMT_EXECUTEまたはCOM_STMT_PREPAREに置き換えられた場合、この設定はすでに有効になっていることを意味します。
cachePrepStmts
useServerPrepStmts=trueを使用すると、サーバーはプリペアドステートメントを実行できますが、デフォルトでは、クライアントは実行のたびにプリペアドステートメントを閉じ、それらを再利用しません。これは、「準備」操作がテキストファイルの実行ほど効率的ではないことを意味します。これを解決するには、 useServerPrepStmts=trueを設定した後、 cachePrepStmts=trueも構成することをお勧めします。これにより、クライアントはプリペアドステートメントをキャッシュできます。
この設定がすでに有効になっていることを確認するには、次のようにします。
- TiDBモニタリングダッシュボードに移動し、[ Query Summary ]> [ QPSByInstance ]からリクエストコマンドタイプを表示します。
- リクエストの
COM_STMT_EXECUTEの数がCOM_STMT_PREPAREの数よりはるかに多い場合は、この設定がすでに有効になっていることを意味します。
さらに、 useConfigs=maxPerformanceを構成すると、 cachePrepStmts=trueを含む複数のパラメーターが同時に構成されます。
prepStmtCacheSqlLimit
cachePrepStmtsを構成した後、 prepStmtCacheSqlLimitの構成にも注意してください(デフォルト値は256です)。この構成は、クライアントにキャッシュされるプリペアドステートメントの最大長を制御します。
この最大長を超えるプリペアドステートメントはキャッシュされないため、再利用できません。この場合、アプリケーションの実際のSQLの長さに応じて、この構成の値を増やすことを検討できます。
次の場合は、この設定が小さすぎるかどうかを確認する必要があります。
- TiDBモニタリングダッシュボードに移動し、[ Query Summary ]> [ QPSByInstance ]からリクエストコマンドタイプを表示します。
- そして、
cachePrepStmts=trueが構成されているが、COM_STMT_PREPAREはまだほとんどCOM_STMT_EXECUTEに等しく、COM_STMT_CLOSEが存在することを確認します。
prepStmtCacheSize
prepStmtCacheSizeは、キャッシュされる準備済みステートメントの数を制御します(デフォルト値は25です)。アプリケーションで多くの種類のSQLステートメントを「準備」する必要があり、準備済みステートメントを再利用したい場合は、この値を増やすことができます。
この設定がすでに有効になっていることを確認するには、次のようにします。
- TiDBモニタリングダッシュボードに移動し、[ Query Summary ]> [ QPSByInstance ]からリクエストコマンドタイプを表示します。
- リクエストの
COM_STMT_EXECUTEの数がCOM_STMT_PREPAREの数よりはるかに多い場合は、この設定がすでに有効になっていることを意味します。
バッチ関連のパラメーター
バッチ書き込みの処理中に、 rewriteBatchedStatements=trueを構成することをお勧めします。 addBatch()またはexecuteBatch()を使用した後でも、JDBCはデフォルトでSQLを1つずつ送信します。次に例を示します。
pstmt = prepare(“insert into t (a) values(?)”);
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
Batchのメソッドが使用されますが、TiDBに送信されるSQLステートメントは依然として個別のINSERTのステートメントです。
insert into t(a) values(10);
insert into t(a) values(11);
insert into t(a) values(12);
ただし、 rewriteBatchedStatements=trueを設定すると、TiDBに送信されるSQLステートメントは単一のINSERTステートメントになります。
insert into t(a) values(10),(11),(12);
INSERTステートメントの書き直しは、複数の「values」キーワードの後の値をSQLステートメント全体に連結することであることに注意してください。 INSERTのステートメントに他の違いがある場合、次のように書き換えることはできません。
insert into t (a) values (10) on duplicate key update a = 10;
insert into t (a) values (11) on duplicate key update a = 11;
insert into t (a) values (12) on duplicate key update a = 12;
上記のINSERTつのステートメントを1つのステートメントに書き換えることはできません。ただし、3つのステートメントを次のステートメントに変更した場合:
insert into t (a) values (10) on duplicate key update a = values(a);
insert into t (a) values (11) on duplicate key update a = values(a);
insert into t (a) values (12) on duplicate key update a = values(a);
次に、それらは書き換え要件を満たします。上記のINSERTつのステートメントは、次の1つのステートメントに書き換えられます。
insert into t (a) values (10), (11), (12) on duplicate key update a = values(a);
バッチ更新中に3つ以上の更新がある場合、SQLステートメントは書き直され、複数のクエリとして送信されます。これにより、クライアントからサーバーへの要求のオーバーヘッドが効果的に削減されますが、副作用として、より大きなSQLステートメントが生成されます。例えば:
update t set a = 10 where id = 1; update t set a = 11 where id = 2; update t set a = 12 where id = 3;
さらに、 クライアントのバグのため、バッチ更新中にrewriteBatchedStatements=trueとuseServerPrepStmts=trueを構成する場合は、このバグを回避するためにallowMultiQueries=trueパラメーターも構成することをお勧めします。
パラメータを統合する
監視を通じて、アプリケーションがTiDBクラスタに対してINSERTの操作しか実行しないにもかかわらず、冗長なSELECTのステートメントが多数あることに気付く場合があります。通常、これは、JDBCが設定をクエリするためにいくつかのSQLステートメントを送信するために発生します(例: select @@session.transaction_read_only )。これらのSQLステートメントはTiDBには役に立たないため、余分なオーバーヘッドを回避するためにuseConfigs=maxPerformanceを構成することをお勧めします。
useConfigs=maxPerformance構成には、構成のグループが含まれます。
cacheServerConfiguration=true
useLocalSessionState=true
elideSetAutoCommits=true
alwaysSendSetIsolation=false
enableQueryTimeouts=false
設定後、モニタリングをチェックして、 SELECTステートメントの数が減少していることを確認できます。
タイムアウト関連のパラメーター
TiDBは、タイムアウトを制御する2つのMySQL互換パラメーターwait_timeoutとmax_execution_timeを提供します。これらの2つのパラメーターはそれぞれ、Javaアプリケーションとの接続アイドルタイムアウトと接続でのSQL実行のタイムアウトを制御します。つまり、これらのパラメータは、TiDBとJavaアプリケーション間の接続の最長アイドル時間と最長ビジー時間を制御します。両方のパラメーターのデフォルト値は0です。これにより、デフォルトで接続が無限にアイドル状態になり、無限にビジーになります(1つのSQLステートメントが実行されるまでの期間は無限になります)。
ただし、実際の実稼働環境では、実行時間が長すぎるアイドル状態の接続とSQLステートメントは、データベースとアプリケーションに悪影響を及ぼします。アイドル状態の接続と長時間実行されるSQLステートメントを回避するために、アプリケーションの接続文字列でこれら2つのパラメーターを構成できます。たとえば、 sessionVariables=wait_timeout=3600 (1時間)とsessionVariables=max_execution_time=300000 (5分)を設定します。
接続プール
TiDB(MySQL)接続の構築は、TCP接続の構築に加えて、接続認証も必要になるため、(少なくともOLTPシナリオでは)比較的コストがかかります。したがって、クライアントは通常、再利用のためにTiDB(MySQL)接続を接続プールに保存します。
ドルイドには、 HikariCPなどの多くの接続プールのc3p0がdbcp tomcat-jdbc 。 TiDBは、使用する接続プールを制限しないため、アプリケーションに適した接続プールを選択できます。
接続数を設定する
接続プールのサイズは、アプリケーション自体のニーズに応じて適切に調整するのが一般的な方法です。例としてHikariCPを取り上げます。
maximumPoolSize:接続プール内の接続の最大数。この値が大きすぎると、TiDBはリソースを消費して無駄な接続を維持します。この値が小さすぎると、アプリケーションの接続が遅くなります。したがって、この値を自分の利益のために構成します。詳細については、 プールのサイズについてを参照してください。minimumIdle:接続プール内のアイドル接続の最小数。これは主に、アプリケーションがアイドル状態のときに突然の要求に応答するために一部の接続を予約するために使用されます。アプリケーションのニーズに応じて構成することもできます。
アプリケーションは、使用を終了した後、接続を返す必要があります。また、アプリケーションで対応する接続プールの監視( metricRegistryなど)を使用して、接続プールの問題を時間内に特定することをお勧めします。
プローブ構成
接続プールは、TiDBへの永続的な接続を維持します。 TiDBは、デフォルトでは(エラーが報告されない限り)クライアント接続をプロアクティブに閉じませんが、通常、クライアントとTiDBの間にLVSやHAProxyなどのネットワークプロキシがあります。通常、これらのプロキシは、一定期間アイドル状態になっている接続をプロアクティブにクリーンアップします(プロキシのアイドル構成によって制御されます)。プロキシのアイドル構成に注意を払うことに加えて、接続プールは、接続を維持またはプローブする必要もあります。
Javaアプリケーションで次のエラーが頻繁に発生する場合:
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
n milliseconds agoのnが0または非常に小さい値である場合、通常、実行されたSQL操作によってTiDBが異常終了することが原因です。原因を特定するには、TiDBstderrログを確認することをお勧めします。
nが非常に大きい値(上記の例の3600000など)の場合、この接続は長時間アイドル状態になってから、中間プロキシによって閉じられた可能性があります。通常の解決策は、プロキシのアイドル構成の値を増やし、接続プールが次のことを行えるようにすることです。
- 毎回接続を使用する前に、接続が利用可能かどうかを確認してください
- 別のスレッドを使用して接続が使用可能かどうかを定期的に確認してください。
- 定期的にテストクエリを送信して、接続を維持します
異なる接続プールの実装は、上記の方法の1つ以上をサポートする場合があります。接続プールのドキュメントを確認して、対応する構成を見つけることができます。
データアクセスフレームワーク
アプリケーションは、データベースアクセスを簡素化するために、ある種のデータアクセスフレームワークを使用することがよくあります。
MyBatis
MyBatisは人気のあるJavaデータアクセスフレームワークです。これは主に、SQLクエリを管理し、結果セットとJavaオブジェクト間のマッピングを完了するために使用されます。 MyBatisはTiDBとの互換性が高いです。 MyBatisは、その歴史的な問題に基づいて問題を起こすことはめったにありません。
ここでは、このドキュメントは主に次の構成に焦点を当てています。
マッパーパラメーター
MyBatis Mapperは、次の2つのパラメーターをサポートしています。
select 1 from t where id = #{param1}はプリペアドステートメントとしてselect 1 from t where id =?に変換され、「準備」され、実際のパラメータが再利用に使用されます。前述の接続パラメータの準備でこのパラメータを使用すると、最高のパフォーマンスを得ることができます。select 1 from t where id = ${param2}はテキストファイルとしてselect 1 from t where id = 1に置き換えられ、実行されます。このステートメントが別のパラメーターに置き換えられて実行されると、MyBatisはステートメントを「準備」するためのさまざまなリクエストをTiDBに送信します。これにより、TiDBが多数のプリペアドステートメントをキャッシュする可能性があり、この方法でSQL操作を実行すると、インジェクションセキュリティのリスクがあります。
動的SQLバッチ
複数のINSERTステートメントのinsert ... values(...), (...), ...形式への自動書き換えをサポートするために、前述のようにJDBCでrewriteBatchedStatements=trueを構成することに加えて、MyBatisは動的SQLを使用してバッチ挿入を半自動で生成することもできます。例として、次のマッパーを取り上げます。
<insert id="insertTestBatch" parameterType="java.util.List" fetchSize="1">
insert into test
(id, v1, v2)
values
<foreach item="item" index="index" collection="list" separator=",">
(
#{item.id}, #{item.v1}, #{item.v2}
)
</foreach>
on duplicate key update v2 = v1 + values(v1)
</insert>
このマッパーはinsert on duplicate key updateのステートメントを生成します。次の(?,?,?)の「値」の数は、渡されたリストの数によって決まります。その最終的な効果は、 rewriteBatchStatements=trueを使用する場合と同様です。これにより、クライアントとTiDB間の通信オーバーヘッドも効果的に削減されます。
前述のように、プリペアドステートメントは最大長が値prepStmtCacheSqlLimitを超えた後はキャッシュされないことに注意する必要があります。
ストリーミング結果
前のセクションは、JDBCで読み取り実行結果をストリーミングする方法を紹介します。 JDBCの対応する構成に加えて、MyBatisで非常に大きな結果セットを読み取りたい場合は、次の点にも注意する必要があります。
- マッパー構成の単一のSQLステートメントに
fetchSizeを設定できます(前のコードブロックを参照)。その効果は、JDBCでsetFetchSizeを呼び出すのと同じです。 - クエリインターフェイスを
ResultHandlerで使用すると、結果セット全体を一度に取得することを回避できます。 - ストリームの読み取りには
Cursorクラスを使用できます。
XMLを使用してマッピングを構成する場合は、マッピングの<select>セクションでfetchSize="-2147483648" ( Integer.MIN_VALUE )を構成することにより、読み取り結果をストリーミングできます。
<select id="getAll" resultMap="postResultMap" fetchSize="-2147483648">
select * from post;
</select>
コードを使用してマッピングを構成する場合は、 @Options(fetchSize = Integer.MIN_VALUE)のアノテーションを追加し、結果のタイプをCursorのままにして、SQL結果をストリーミングで読み取ることができるようにすることができます。
@Select("select * from post")
@Options(fetchSize = Integer.MIN_VALUE)
Cursor<Post> queryAllPost();
ExecutorType
openSessionの間にExecutorTypeを選択できます。 MyBatisは、次の3種類のエグゼキュータをサポートしています。
- 単純:実行ごとにプリペアドステートメントがJDBCに呼び出されます(JDBC構成項目
cachePrepStmtsが有効になっている場合、繰り返されるプリペアドステートメントが再利用されます) - 再利用:プリペアドステートメントは
executorにキャッシュされるため、cachePrepStmtsを使用せずにプリペアドステートメントの重複呼び出しを減らすことができます。 - バッチ
UPDATE各更新操作(INSERT)は最初にバッチに追加され、トランザクションがコミットされるか、SELECTクエリが実行されるまで実行されDELETE。 JDBCレイヤーでrewriteBatchStatementsが有効になっている場合、ステートメントを書き直そうとします。そうでない場合は、ステートメントが1つずつ送信されます。
通常、デフォルト値のExecutorTypeはSimpleです。 openSessionを呼び出すときは、 ExecutorTypeを変更する必要があります。バッチ実行の場合、トランザクションでUPDATEまたはINSERTステートメントがかなり高速に実行されることがありますが、データの読み取りまたはトランザクションのコミット時には低速です。これは実際には正常であるため、遅いSQLクエリのトラブルシューティングを行う場合はこれに注意する必要があります。
春のトランザクション
現実の世界では、アプリケーションは春のトランザクションおよびAOPアスペクトを使用してトランザクションを開始および停止する場合があります。
メソッド定義に@Transactionalアノテーションを追加することにより、AOPはメソッドが呼び出される前にトランザクションを開始し、メソッドが結果を返す前にトランザクションをコミットします。アプリケーションに同様のニーズがある場合は、コードで@Transactionalを見つけて、トランザクションがいつ開始および終了されるかを判別できます。
埋め込みの特殊なケースに注意してください。これが発生した場合、Springは伝搬の構成に基づいて異なる動作をします。 TiDBはセーブポイントをサポートしていないため、ネストされたトランザクションはまだサポートされていません。
その他
このセクションでは、問題のトラブルシューティングに役立つJavaの便利なツールをいくつか紹介します。
トラブルシューティングツール
Javaアプリケーションで問題が発生し、アプリケーションロジックがわからない場合は、JVMの強力なトラブルシューティングツールを使用することをお勧めします。一般的なツールは次のとおりです。
jstack
jstackはGoのpprof/goroutineに似ており、プロセスのスタックの問題を簡単にトラブルシューティングできます。
jstack pidを実行することにより、ターゲットプロセス内のすべてのスレッドのIDとスタック情報を出力できます。デフォルトでは、Javaスタックのみが出力されます。 JVMでC++スタックを同時に出力する場合は、 -mオプションを追加します。
jstackを複数回使用することで、スタックの問題(たとえば、MybatisでBatch ExecutorTypeを使用することによるアプリケーションのビューからの遅いクエリ)またはアプリケーションのデッドロックの問題(たとえば、アプリケーションがSQLステートメントを送信しないため)を簡単に見つけることができます。送信する前にロックをプリエンプトしています)。
さらに、スレッドIDを表示する一般的な方法はtop -p $ PID -HまたはJavaスイスナイフです。また、「スレッドが多くのCPUリソースを占有し、何が実行されているのかわからない」という問題を見つけるには、次の手順を実行します。
printf "%x\n" pidを使用して、スレッドIDを16進数に変換します。- jstack出力に移動して、対応するスレッドのスタック情報を見つけます。
jmap&mat
Goのpprof/heapとは異なり、 jmapはプロセス全体のメモリスナップショットをダンプし(Goでは、ディストリビューターのサンプリングです)、スナップショットは別のツールマットで分析できます。
マットを介して、プロセス内のすべてのオブジェクトに関連する情報と属性を確認できます。また、スレッドの実行ステータスを確認することもできます。たとえば、matを使用して、現在のアプリケーションに存在するMySQL接続オブジェクトの数、および各接続オブジェクトのアドレスとステータス情報を確認できます。
デフォルトでは、matは到達可能なオブジェクトのみを処理することに注意してください。 GCの若い問題のトラブルシューティングを行う場合は、マットの構成を調整して、到達できないオブジェクトを表示できます。さらに、若いGCの問題(または多数の短命のオブジェクト)のメモリ割り当てを調査するには、JavaFlightRecorderを使用する方が便利です。
痕跡
オンラインアプリケーションは通常、コードの変更をサポートしていませんが、問題を特定するためにJavaで動的インストルメンテーションを実行することが望ましい場合がよくあります。したがって、btraceまたはarthastraceを使用することをお勧めします。アプリケーションプロセスを再起動せずに、トレースコードを動的に挿入できます。
炎のグラフ
Javaアプリケーションでフレームグラフを取得するのは面倒です。詳細については、 Java Flame Graphsの紹介:みんなのために火をつけろ!を参照してください。
結論
このドキュメントでは、データベースと相互作用する一般的に使用されるJavaコンポーネントに基づいて、TiDBを使用してJavaアプリケーションを開発するための一般的な問題と解決策について説明します。 TiDBはMySQLプロトコルとの互換性が高いため、MySQLベースのJavaアプリケーションのベストプラクティスのほとんどはTiDBにも適用されます。
TiDBコミュニティのSlackチャネルで参加し、TiDBを使用してJavaアプリケーションを開発する際の経験や問題について幅広いTiDBユーザーグループと共有してください。