2つのリージョンに3つのアベイラビリティゾーンを展開
このドキュメントでは、2 つのリージョン展開における 3 つの可用性ゾーン (AZ) のアーキテクチャと構成について説明します。
このドキュメントにおける「リージョン」という用語は地理的な領域を指し、「リージョン」はTiKVにおけるデータstorageの基本単位を指します。「AZ」はリージョン内の独立した場所を指し、各リージョンには複数のAZが存在します。このドキュメントで説明するソリューションは、単一の都市に複数のデータセンターが存在するシナリオにも適用されます。
概要
2つのリージョンに3つのAZを配置するアーキテクチャは、高可用性と耐障害性を備えたデプロイメントソリューションです。本番データ用AZ、同じリージョンに災害復旧用AZ、そして別のリージョンに災害復旧用AZを配置します。このモードでは、2つのリージョンにまたがる3つのAZが相互接続されます。1つのAZに障害が発生した場合や災害が発生した場合でも、他のAZが引き続き正常に動作し、主要なアプリケーションまたはすべてのアプリケーションを引き継ぎます。1つのリージョンに複数のAZを配置するデプロイメントと比較して、このソリューションはリージョン間の高可用性という利点があり、リージョンレベルの自然災害にも耐えることができます。
分散データベースTiDBは、 Raftアルゴリズムを用いて2リージョン3AZアーキテクチャをネイティブにサポートし、データベースクラスター内のデータの一貫性と高可用性を保証します。同一リージョン内のAZ間のネットワークレイテンシーは比較的低いため、アプリケーショントラフィックを同一リージョン内の2つのAZに分散させることができ、TiKVリージョンリーダーとPDリーダーの分散を制御することで、これらの2つのAZ間でトラフィック負荷を分散させることができます。
デプロイメントアーキテクチャ
このセクションでは、シアトルとサンフランシスコを例に、TiDB の分散データベースの 2 つのリージョンにおける 3 つの AZ の展開モードについて説明します。
この例では、2つのAZ(AZ1とAZ2)がシアトルにあり、もう1つのAZ(AZ3)がサンフランシスコにあります。AZ1とAZ2間のネットワークレイテンシーは3ミリ秒未満です。シアトルのAZ3とAZ1/AZ2間のネットワークレイテンシーは約20ミリ秒です(ISP専用ネットワークを使用)。
クラスター展開のアーキテクチャは次のとおりです。
- TiDB クラスターは、シアトルの AZ1、シアトルの AZ2、サンフランシスコの AZ3 の 2 つのリージョンの 3 つの AZ にデプロイされています。
- クラスターには5つのレプリカがあり、AZ1に2つ、AZ2に2つ、AZ3に1つあります。TiKVコンポーネントでは、各ラックにラベルが付けられており、各ラックにレプリカがあることを意味します。
- ユーザーにとって透過的なデータの一貫性と高可用性を確保するために、 Raftプロトコルが採用されています。
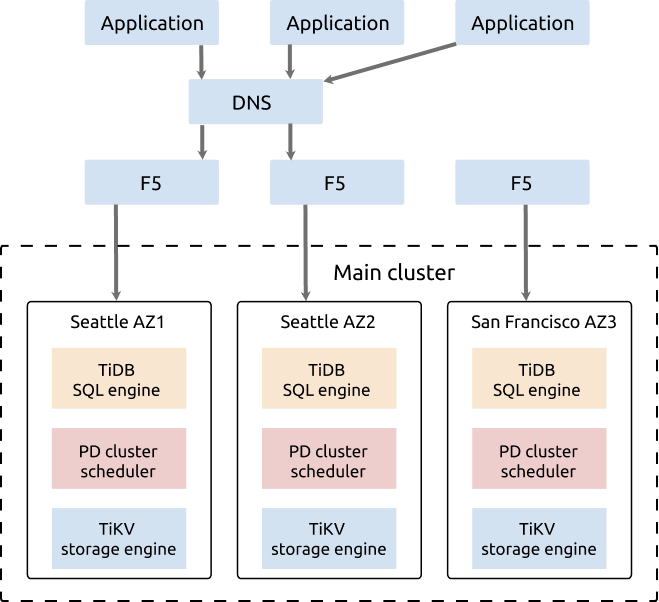
このアーキテクチャは高可用性です。リージョンリーダーの配置は、同じリージョン(シアトル)内の2つのAZ(AZ1とAZ2)に制限されています。リージョンリーダーの配置が制限されていない3AZソリューションと比較して、このアーキテクチャには以下の利点と欠点があります。
利点
- リージョンリーダーは、レイテンシーが低い同じリージョンの AZ にあるため、書き込みが高速になります。
- 2つのAZが同時にサービスを提供できるため、リソースの使用率が高くなります。
- 1 つの AZ に障害が発生しても、サービスは引き続き利用可能であり、データの安全性は確保されます。
デメリット
- データの一貫性はRaftアルゴリズムによって実現されるため、同一リージョン内の2つのAZが同時に障害に見舞われた場合、別のリージョン(サンフランシスコ)の災害復旧AZに1つのレプリカのみが残ります。これは、ほとんどのレプリカが残るというRaftアルゴリズムの要件を満たしていません。その結果、クラスターが一時的に利用できなくなる可能性があります。保守担当者は、残った1つのレプリカからクラスターを復旧する必要があり、複製されていない少量のホットデータが失われることになります。ただし、このようなケースはまれです。
- ISP 専用ネットワークが使用されるため、このアーキテクチャのネットワーク インフラストラクチャには高いコストがかかります。
- 2 つのリージョンの 3 つの AZ に 5 つのレプリカが構成され、データの冗長性が高まり、storageコストが高くなります。
展開の詳細
2 つのリージョン (シアトルとサンフランシスコ) の 3 つの AZ の展開プランの構成は、次のようになります。
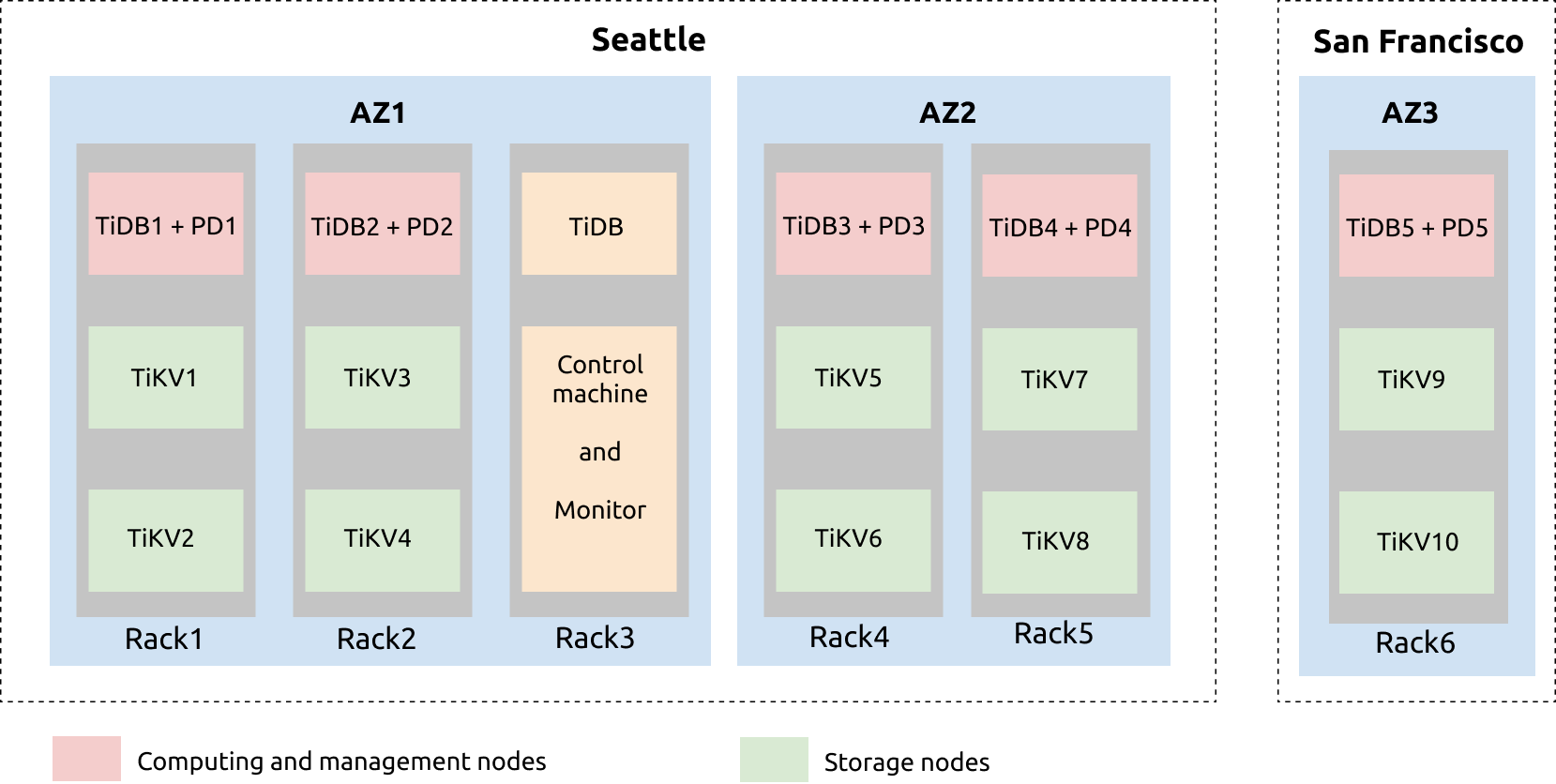
上の図から、シアトルにはAZ1とAZ2という2つのAZがあることがわかります。AZ1には、rac1、rac2、rac3という3つのラックセットがあります。AZ2には、rac4とrac5という2つのラックがあります。サンフランシスコのAZ3には、rac6というラックがあります。
AZ1のrac1では、1台のサーバーにTiDBとPDサービスがデプロイされ、他の2台のサーバーにTiKVサービスがデプロイされています。各TiKVサーバーには2つのTiKVインスタンス(tikv-server)がデプロイされています。これはrac2、rac4、rac5、rac6でも同様です。
TiDBサーバー、制御マシン、監視サーバーはrac3上に配置されています。TiDBサーバーは定期メンテナンスとバックアップ用に導入されています。Prometheus、Grafana、およびリストアツールは制御マシンと監視マシンに導入されています。
コンフィグレーション
例
たとえば、次のtiup topology.yaml yaml ファイルを参照してください。
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb_cluster/tidb-deploy"
data_dir: "/data/tidb_cluster/tidb-data"
server_configs:
tikv:
server.grpc-compression-type: gzip
pd:
replication.location-labels: ["az","replication zone","rack","host"]
pd_servers:
- host: 10.63.10.10
name: "pd-10"
- host: 10.63.10.11
name: "pd-11"
- host: 10.63.10.12
name: "pd-12"
- host: 10.63.10.13
name: "pd-13"
- host: 10.63.10.14
name: "pd-14"
tidb_servers:
- host: 10.63.10.10
- host: 10.63.10.11
- host: 10.63.10.12
- host: 10.63.10.13
- host: 10.63.10.14
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { az: "1", replication zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { az: "1", replication zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { az: "2", replication zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { az: "2", replication zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { az: "3", replication zone: "5", rack: "5", host: "34" }
raftstore.raft-min-election-timeout-ticks: 50
raftstore.raft-max-election-timeout-ticks: 60
monitoring_servers:
- host: 10.63.10.60
grafana_servers:
- host: 10.63.10.60
alertmanager_servers:
- host: 10.63.10.60
ラベルデザイン
2つのリージョンに3つのAZを展開する場合、ラベル設計では可用性と災害復旧を考慮する必要があります。展開の物理構造に基づいて、4つhostレベル( az )をrackすることをお勧めしますreplication zone
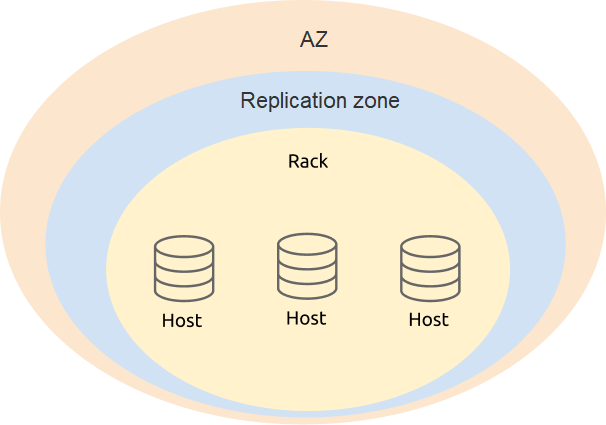
PD 構成で、TiKV ラベルのレベル情報を追加します。
server_configs:
pd:
replication.location-labels: ["az","replication zone","rack","host"]
tikv_serversの構成は、TiKV の実際の物理的な展開場所のラベル情報に基づいており、PD がグローバルな管理とスケジュールを実行しやすくなります。
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { az: "1", replication zone: "1", rack: "1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { az: "1", replication zone: "2", rack: "2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { az: "2", replication zone: "3", rack: "3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { az: "2", replication zone: "4", rack: "4", host: "33" }
- host: 10.63.10.34
config:
server.labels: { az: "3", replication zone: "5", rack: "5", host: "34" }
パラメータ設定を最適化する
2 つのリージョンに 3 つの AZ を展開する場合、パフォーマンスを最適化するには、通常のパラメータを設定するだけでなく、コンポーネントパラメータも調整する必要があります。
TiKVでgRPCメッセージ圧縮を有効にします。クラスターのデータはネットワーク経由で送信されるため、gRPCメッセージ圧縮を有効にするとネットワークトラフィックを削減できます。
server.grpc-compression-type: gzip別のリージョン(サンフランシスコ)にある TiKV ノードのネットワーク構成を最適化します。サンフランシスコの AZ3 の以下の TiKV パラメータを変更し、この TiKV ノードのレプリカがRaft選出に参加しないようにします。
raftstore.raft-min-election-timeout-ticks: 50 raftstore.raft-max-election-timeout-ticks: 60
注記:
TiKVノードの選出タイムアウト値を
raftstore.raft-min-election-timeout-ticksとraftstore.raft-max-election-timeout-ticks大きく設定すると、そのノード上のリージョンがリーダーになる可能性が大幅に低下します。ただし、一部のTiKVノードがオフラインになり、残りのアクティブなTiKVノードのRaftログが遅延しているような災害シナリオでは、このTiKVノード上の選出タイムアウト値が大きいリージョンのみがリーダーになることができます。このTiKVノード上のリージョンは、選出を開始する前に少なくともraftstore.raft-min-election-timeout-ticksで設定された期間待機する必要があるため、このようなシナリオではクラスターの可用性への影響を防ぐため、これらの値を過度に大きく設定しないことをお勧めします。
スケジューリングを設定します。クラスターが有効化されたら、ツール
tiup ctl:v{CLUSTER_VERSION} pdを使用してスケジューリングポリシーを変更します。TiKV Raftレプリカの数を変更します。この数は計画どおりに設定します。この例では、レプリカの数は5です。config set max-replicas 5RaftリーダーをAZ3にスケジュールすることを禁止します。Raftリーダーを別のリージョン(AZ3)にスケジュールすると、シアトルのAZ1/AZ2とサンフランシスコのAZ3の間に不要なネットワークオーバーヘッドが発生します。ネットワーク帯域幅とレイテンシーもTiDBクラスターのパフォーマンスに影響を与えます。
config set label-property reject-leader dc 3注記:
TiDB v5.2以降、
label-property構成はデフォルトではサポートされません。レプリカポリシーを設定するには、 配置ルール使用してください。PDの優先度を設定します。PDリーダーが別のリージョン(AZ3)にある状況を回避するには、ローカルPD(シアトル)の優先度を上げ、別のリージョン(サンフランシスコ)のPDの優先度を下げることができます。数値が大きいほど優先度が高くなります。利用可能なすべてのPDノードの中で、優先度が最も高いノードがリーダーになります。
member leader_priority PD-10 5 member leader_priority PD-11 5 member leader_priority PD-12 5 member leader_priority PD-13 5 member leader_priority PD-14 1