1つのリージョンに複数のアベイラビリティゾーンを展開
分散SQLデータベースであるTiDBは、従来のリレーショナルデータベースの優れた機能とNoSQLデータベースのスケーラビリティを兼ね備え、複数のアベイラビリティゾーン(AZ)をまたがる高可用性を実現します。このドキュメントでは、1つのリージョンに複数のAZをデプロイする方法について説明します。
このドキュメントにおける「リージョン」という用語は地理的な領域を指し、「リージョン」はTiKVにおけるデータstorageの基本単位を指します。「AZ」はリージョン内の独立した場所を指し、各リージョンには複数のAZが存在します。このドキュメントで説明するソリューションは、単一の都市に複数のデータセンターが存在するシナリオにも適用されます。
Raftプロトコル
Raftは分散コンセンサスアルゴリズムです。このアルゴリズムを使用することで、TiDBクラスタのコンポーネント間でPDとTiKVの両方がデータの災害復旧を実現します。これは以下のメカニズムを通じて実現されます。
- Raftメンバーの本質的な役割は、ログの複製を実行し、状態マシンとして機能することです。Raftメンバー間では、ログを複製することでデータの複製が実現されます。RaftRaftは、さまざまな状況に応じて自身の状態を変化させ、サービスを提供するリーダーを選出します。
- RaftはRaftプロトコルに従う投票システムです。Raftグループでは、メンバーが過半数の票を獲得すると、そのメンバーはリーダーに昇格します。つまり、 Raftグループに過半数のノードが残っている場合、サービスを提供するリーダーが選出されます。
Raft の信頼性を活用するには、実際の展開シナリオで次の条件を満たす必要があります。
- 1 台のサーバーに障害が発生した場合に備えて、少なくとも 3 台のサーバーを使用します。
- 1 つのラックが故障した場合に備えて、少なくとも 3 つのラックを使用してください。
- 1 つの AZ に障害が発生した場合に備えて、少なくとも 3 つの AZ を使用します。
- 1 つのリージョンでデータの安全性の問題が発生した場合に備えて、少なくとも 3 つのリージョンに TiDBをデプロイ。
ネイティブRaftプロトコルは、偶数個のレプリカを適切にサポートしていません。リージョン間のネットワークレイテンシーの影響を考慮すると、高可用性と耐障害性を備えたRaftデプロイメントには、同一リージョン内に3つのAZを配置することが最適なソリューションとなる可能性があります。
1つのリージョンに3つのAZを展開
TiDBクラスターは、同一リージョン内の3つのAZにデプロイできます。このソリューションでは、クラスター内でRaftプロトコルを用いて3つのAZ間のデータレプリケーションが実装されています。これらの3つのAZは、同時に読み取りと書き込みのサービスを提供できます。1つのAZに障害が発生しても、データの整合性は影響を受けません。
シンプルなアーキテクチャ
TiDB、TiKV、PD は 3 つの AZ に分散されており、これが最も一般的な展開であり、可用性が最も高くなります。
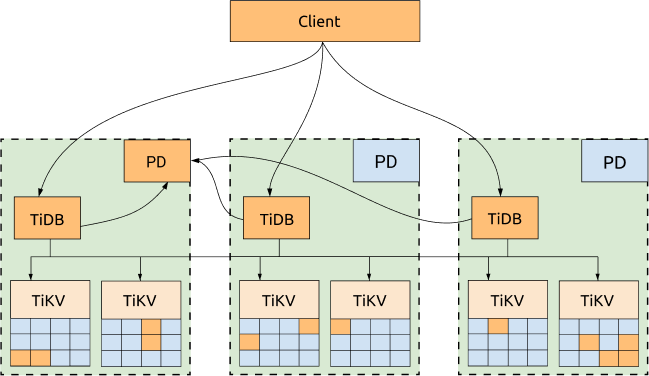
利点:
- すべてのレプリカは 3 つの AZ に分散されており、高い可用性と災害復旧機能を備えています。
- 1 つの AZ がダウンしてもデータは失われません (RPO = 0)。
- 1つのAZがダウンした場合でも、他の2つのAZが自動的にリーダー選出を開始し、一定時間内(通常は20秒以内)にサービスを自動的に再開します。詳細については、次の図をご覧ください。
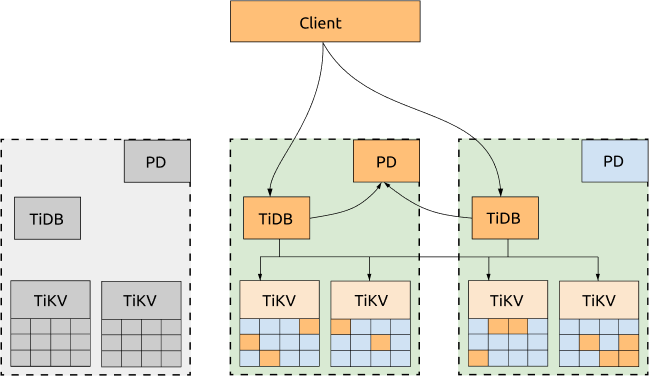
デメリット:
パフォーマンスはネットワークレイテンシーによって影響を受ける可能性があります。
- 書き込みの場合、すべてのデータは少なくとも2つのAZに複製される必要があります。TiDBは書き込みに2フェーズコミットを使用するため、書き込みレイテンシーは2つのAZ間のネットワークレイテンシーの2倍以上になります。
- リーダーが読み取り要求を送信する TiDB ノードと同じ AZ にない場合、読み取りパフォーマンスはネットワークレイテンシーの影響も受けます。
- 各TiDBトランザクションは、PDリーダーからタイムスタンプオラクル(TSO)を取得する必要があります。そのため、TiDBとPDリーダーが同じAZにない場合、書き込みリクエストを含む各トランザクションはTSOを2回取得する必要があるため、トランザクションのパフォーマンスはネットワークレイテンシーの影響を受けます。
最適化されたアーキテクチャ
3つのAZすべてがアプリケーションにサービスを提供する必要がない場合は、すべてのリクエストを1つのAZにディスパッチし、TiKVリージョンリーダーとPDリーダーを同じAZに移行するようにスケジューリングポリシーを設定できます。これにより、TSOの取得もTiKVリージョンの読み取りも、AZ間のネットワークレイテンシーの影響を受けません。このAZがダウンした場合、PDリーダーとTiKVリージョンリーダーは他の稼働中のAZで自動的に選出されるため、リクエストを稼働中のAZに切り替えるだけで済みます。
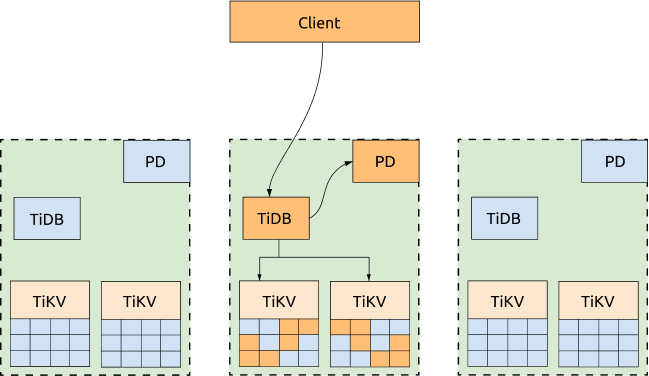
利点:
クラスターの読み取りパフォーマンスとTSO取得能力が向上しました。スケジューリングポリシーの設定テンプレートは次のとおりです。
-- Evicts all leaders of other AZs to the AZ that provides services to the application.
config set label-property reject-leader LabelName labelValue
-- Migrates PD leaders and sets priority.
member leader transfer pdName1
member leader_priority pdName1 5
member leader_priority pdName2 4
member leader_priority pdName3 3
注記:
TiDB v5.2以降、
label-property構成はデフォルトではサポートされません。レプリカポリシーを設定するには、 配置ルール使用してください。
デメリット:
- 書き込みシナリオは、依然としてAZ間のネットワークレイテンシーの影響を受けます。これは、 Raftが多数決プロトコルに準拠し、書き込まれたすべてのデータが少なくとも2つのAZに複製される必要があるためです。
- サービスを提供する TiDBサーバーは1 つの AZ にのみ存在します。
- すべてのアプリケーション トラフィックは 1 つの AZ によって処理され、パフォーマンスはその AZ のネットワーク帯域幅の圧力によって制限されます。
- TSO の取得能力と読み取りパフォーマンスは、アプリケーショントラフィックを処理する AZ 内の PDサーバーと TiKVサーバーが稼働しているかどうかによって影響を受けます。これらのサーバーがダウンしている場合でも、アプリケーションはセンター間ネットワークレイテンシーの影響を受けます。
展開例
このセクションでは、トポロジの例を示し、TiKV ラベルと TiKV ラベルの計画について説明します。
トポロジの例
以下の例では、3つのAZ(AZ1、AZ2、AZ3)が1つのリージョンに配置されていることを前提としています。各AZには2組のラックがあり、各ラックには3台のサーバーが設置されています。この例では、ハイブリッド展開、つまり1台のマシンに複数のインスタンスが展開されるシナリオは考慮していません。1つのリージョン内の3つのAZにTiDBクラスター(3つのレプリカ)を展開する手順は以下のとおりです。
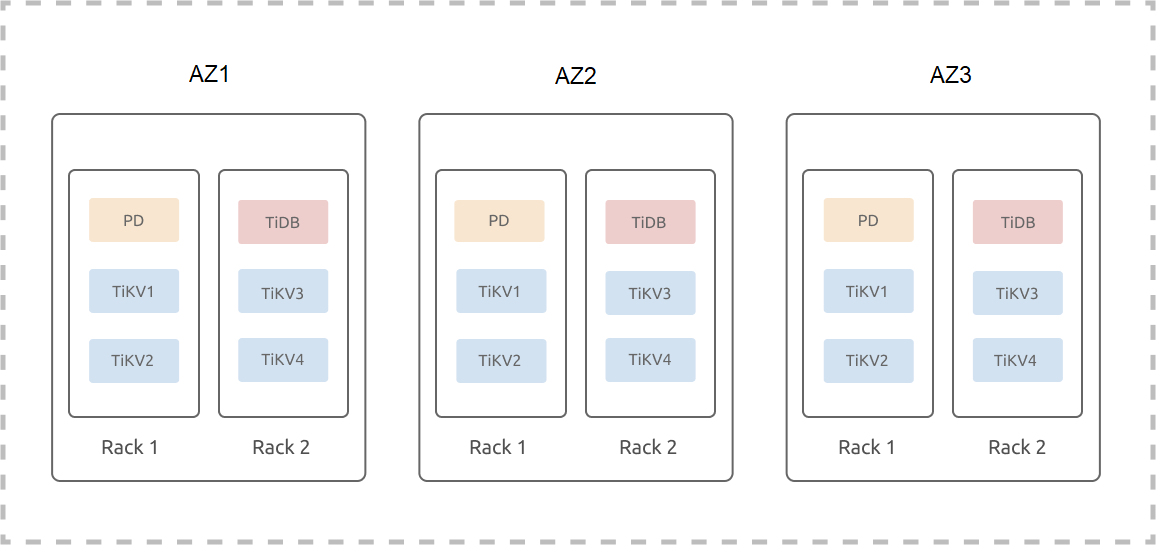
TiKVラベル
TiKVはMulti-Raftシステムであり、データは複数のリージョンに分割され、各リージョンのデフォルトのサイズは96MBです。各リージョンの3つのレプリカがRaftグループを形成します。3つのレプリカを持つTiDBクラスターの場合、リージョンのレプリカ数はTiKVインスタンス数に依存しないため、リージョンの3つのレプリカは3つのTiKVインスタンスにのみスケジュールされます。つまり、クラスターをN個のTiKVインスタンスにスケールアウトした場合でも、クラスターは3つのレプリカを持つ状態のままです。
3つのレプリカで構成されるRaftグループは、1つのレプリカ障害しか許容しないため、クラスターをN個のTiKVインスタンスにスケールアウトした場合でも、このクラスターが許容するレプリカ障害は1つだけです。2つのTiKVインスタンスに障害が発生すると、一部のリージョンでレプリカが失われ、このクラスター内のデータが不完全になる可能性があります。これらのリージョンのデータにアクセスするSQLリクエストは失敗します。N個のTiKVインスタンス間で2つの同時障害が発生する確率は、3個のTiKVインスタンス間で2つの同時障害が発生する確率よりもはるかに高くなります。つまり、Multi-RaftシステムをスケールアウトしてTiKVインスタンスの数を増やすほど、システムの可用性は低下します。
上記の制限のため、TiKVの位置情報の記述にはlabel使用されます。ラベル情報は、デプロイメントまたはローリングアップグレード操作によってTiKV起動構成ファイルに更新されます。起動されたTiKVは、最新のラベル情報をPDに報告します。PDは、ユーザーが登録したラベル名(ラベルメタデータ)とTiKVトポロジに基づいて、リージョンレプリカを最適にスケジュールし、システムの可用性を向上させます。
TiKVラベルの計画例
システムの可用性と災害復旧能力を向上させるには、既存の物理リソースと災害復旧能力に応じてTiKVラベルを設計・計画する必要があります。また、計画されているトポロジに応じて、クラスタ初期化構成ファイルを編集する必要があります。
server_configs:
pd:
replication.location-labels: ["zone","az","rack","host"]
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { zone: "z1", az: "az1", rack: "r1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { zone: "z1", az: "az1", rack: "r1", host: "31" }
- host: 10.63.10.32
config:
server.labels: { zone: "z1", az: "az1", rack: "r2", host: "32" }
- host: 10.63.10.33
config:
server.labels: { zone: "z1", az: "az1", rack: "r2", host: "33" }
- host: 10.63.10.34
config:
server.labels: { zone: "z2", az: "az2", rack: "r1", host: "34" }
- host: 10.63.10.35
config:
server.labels: { zone: "z2", az: "az2", rack: "r1", host: "35" }
- host: 10.63.10.36
config:
server.labels: { zone: "z2", az: "az2", rack: "r2", host: "36" }
- host: 10.63.10.37
config:
server.labels: { zone: "z2", az: "az2", rack: "r2", host: "37" }
- host: 10.63.10.38
config:
server.labels: { zone: "z3", az: "az3", rack: "r1", host: "38" }
- host: 10.63.10.39
config:
server.labels: { zone: "z3", az: "az3", rack: "r1", host: "39" }
- host: 10.63.10.40
config:
server.labels: { zone: "z3", az: "az3", rack: "r2", host: "40" }
- host: 10.63.10.41
config:
server.labels: { zone: "z3", az: "az3", rack: "r2", host: "41" }
上記の例では、 zoneレプリカの分離を制御する論理可用性ゾーンレイヤーです (サンプル クラスターには 3 つのレプリカがあります)。
将来的に AZ がスケールアウトされる可能性があることを考慮し、3階層ラベル構造( az 、 rack 、 host )はそのまま採用しません。 AZ2 、 AZ3 、 AZ4スケールアウトすると仮定した場合、対応するアベイラビリティゾーン内の AZ とラックをスケールアウトするだけで済みます。
この 3 層のラベル構造をそのまま採用すると、AZ をスケールアウトした後に、新しいラベルを適用し、TiKV 内のデータを再調整する必要がある場合があります。
高可用性と災害復旧分析
1つのリージョンに複数のAZを配置することで、1つのAZに障害が発生した場合でも、クラスターは手動介入なしに自動的にサービスを復旧できます。データの整合性も保証されます。なお、スケジューリングポリシーはパフォーマンスを最適化するために使用されますが、障害発生時には、これらのポリシーはパフォーマンスよりも可用性を優先します。