Follower Read
TiDBでは、高可用性とデータの安全性を確保するために、TiKVは各リージョンに複数のレプリカを保存します。そのうちの1つがリーダー、残りはフォロワーです。デフォルトでは、すべての読み取りおよび書き込みリクエストはリーダーによって処理されます。Follower Read機能により、TiDBは強力な一貫性を維持しながら、リージョンのフォロワーレプリカからデータを読み取ることができます。これにより、リーダーの読み取りワークロードが軽減され、クラスター全体の読み取りスループットが向上します。
Follower Read を実行する際、TiDBはトポロジ情報に基づいて適切なレプリカを選択します。具体的には、TiDBはzoneラベルを使用してローカルレプリカを識別します。つまり、TiDBノードのzoneラベルがターゲットTiKVノードの3ラベルと同じ場合、TiDBはそのレプリカをローカルレプリカと見なします。詳細については、 トポロジラベルによるレプリカのスケジュール参照してください。
フォロワーが読み取りリクエストを処理できるようにすることで、 Follower Read は次の目標を達成します。
- 読み取りホットスポットを分散し、リーダーの作業負荷を軽減します。
- マルチ AZ またはマルチデータセンターの展開でローカルレプリカの読み取りを優先し、AZ 間のトラフィックを最小限に抑えます。
使用シナリオ
Follower Read は次のシナリオに適しています。
- 読み取り要求が集中するアプリケーション、または読み取りホットスポットが顕著なアプリケーション。
- ローカルレプリカからの読み取りを優先して、AZ 間の帯域幅使用量を削減するマルチ AZ 展開。
- 全体的な読み取りパフォーマンスをさらに向上させたい読み取り/書き込み分離アーキテクチャ。
使用法
TiDB のFollower Read機能を有効にするには、 tidb_replica_read変数の値を次のように変更します。
set [session | global] tidb_replica_read = '<target value>';
スコープ: セッション | グローバル
デフォルト: リーダー
この変数は、想定されるデータ読み取りモードを定義します。v8.5.4以降、この変数は読み取り専用SQL文にのみ適用されます。
ローカルレプリカから読み取ることで AZ 間のトラフィックを削減する必要があるシナリオでは、次の構成が推奨されます。
leader: デフォルト値。最高のパフォーマンスを提供します。closest-adaptive: パフォーマンスの低下を最小限に抑えながら、AZ 間のトラフィックを最小限に抑えます。closest-replicas: AZ 間のトラフィック節約を最大化しますが、パフォーマンスが低下する可能性があります。
他の構成を使用している場合は、次の表を参照して推奨構成に変更してください。
より正確な読み取りレプリカ選択ポリシーを使用する場合は、次のように使用可能な構成の完全なリストを参照してください。
値を
tidb_replica_read~leaderまたは空の文字列に設定すると、TiDB はデフォルトの動作を維持し、すべての読み取り操作をリーダー レプリカに送信して実行します。tidb_replica_readをfollowerに設定すると、TiDB は読み取り操作を実行するためにリージョンのフォロワーレプリカを選択します。リージョンにラーナーレプリカがある場合、TiDB は同じ優先度で読み取り操作の対象としてそれらも考慮します。現在のリージョンに利用可能なフォロワーレプリカまたはラーナーレプリカが存在しない場合、TiDB はリーダーレプリカから読み取ります。tidb_replica_readの値をleader-and-followerに設定すると、TiDB は読み取り操作を実行するレプリカを任意に選択できます。このモードでは、読み取りリクエストはリーダー、フォロワー、ラーナーの間で負荷分散されます。値が
tidb_replica_readからprefer-leaderに設定されている場合、TiDB は読み取り操作を実行する際にリーダーレプリカを優先的に選択します。リーダーレプリカの読み取り操作の処理速度が明らかに遅い場合(ディスクやネットワークのパフォーマンスジッターなどの影響による)、TiDB は読み取り操作を実行するために他の利用可能なフォロワーレプリカを選択します。値が
tidb_replica_readからclosest-replicasに設定されている場合、TiDB は同じアベイラビリティゾーン内のレプリカ(リーダー、フォロワー、またはラーナー)を優先的に選択して読み取り操作を実行します。同じアベイラビリティゾーン内にレプリカがない場合、TiDB はリーダーレプリカから読み取りを行います。tidb_replica_readの値がclosest-adaptiveに設定されている場合:- 読み取り要求の推定結果が
tidb_adaptive_closest_read_threshold以上の値である場合、TiDB は読み取り操作に同じアベイラビリティ ゾーン内のレプリカを選択することを優先します。 アベイラビリティ ゾーン間で読み取りトラフィックの不均衡な分散を回避するために、TiDB はすべてのオンライン TiDB および TiKV ノードのアベイラビリティ ゾーンの分散を動的に検出します。各アベイラビリティ ゾーンでは、closest-adaptive構成が有効になる TiDB ノードの数は制限されており、これは常に TiDB ノードが最も少ないアベイラビリティ ゾーン内の TiDB ノードの数と同じであり、その他の TiDB ノードは自動的にリーダー レプリカから読み取ります。たとえば、TiDB ノードが 3 つのアベイラビリティ ゾーン (A、B、C) に分散されていて、A と B にそれぞれ 3 つの TiDB ノードが含まれ、C には 2 つの TiDB ノードのみが含まれる場合、各アベイラビリティ ゾーンでclosest-adaptive構成が有効になる TiDB ノードの数は 2 であり、A および B アベイラビリティ ゾーンのそれぞれのその他の TiDB ノードは読み取り操作にリーダー レプリカを自動的に選択します。 - 読み取り要求の推定結果が
tidb_adaptive_closest_read_thresholdの値未満の場合、TiDB は読み取り操作に対してリーダー レプリカのみを選択できます。
- 読み取り要求の推定結果が
tidb_replica_readをlearnerに設定すると、TiDB はラーナーレプリカからデータを読み取ります。現在のリージョンで利用可能なラーナーレプリカがない場合、TiDB は利用可能なリーダーレプリカまたはフォロワーレプリカからデータを読み取ります。
基本的な監視
TiDB > KV 要求>読み取り要求トラフィックパネル (v8.5.4 の新機能)をチェックして、 Follower Read を有効にするかどうかを決定し、有効にした後のトラフィック削減効果を確認できます。
実施メカニズム
Follower Read機能が導入される前、TiDBは強力なリーダー原則を適用し、すべての読み取りおよび書き込みリクエストをリージョンのリーダーノードに送信して処理していました。TiKVはリージョンを複数の物理ノードに均等に分散できますが、各リージョンではリーダーノードのみが外部サービスを提供できます。他のフォロワーは読み取りリクエストを処理できず、常にリーダーから複製されたデータを受信し、フェイルオーバー発生時にリーダーを選出するための投票の準備のみを行います。
Follower Read には、TiKV 読み取りリクエストをリーダーレプリカからリージョン内のフォロワーレプリカにオフロードする一連の負荷分散メカニズムが含まれています。線形化可能性を侵害したり、TiDB のスナップショット分離に影響を与えたりすることなくフォロワーノードからのデータ読み取りを可能にするには、フォロワーノードがRaftプロトコルのReadIndexを使用して、読み取りリクエストがリーダーノードにコミットされた最新のデータを読み取れるようにする必要があります。TiDB レベルでは、 Follower Read機能は、負荷分散ポリシーに基づいて、リージョンの読み取りリクエストをフォロワーレプリカに送信するだけです。
強力な一貫性のある読み取り
フォロワーノードが読み取り要求を処理する際、まずRaftプロトコルのReadIndexを使用してリージョンのリーダーとやり取りし、現在のRaftグループの最新のコミットインデックスを取得します。リーダーの最新のコミットインデックスがフォロワーにローカルに適用された後、読み取り要求の処理が開始されます。
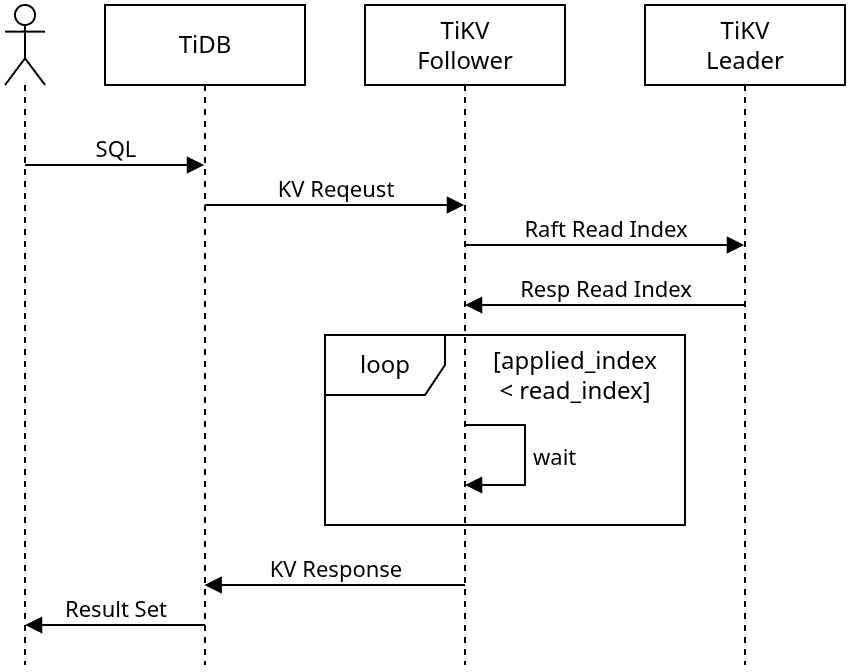
Followerレプリカ選択戦略
Follower Read機能は、TiDBのスナップショット分離トランザクション分離レベルに影響を与えません。TiDBは、最初の読み取り試行ではtidb_replica_read設定に基づいてレプリカを選択します。2回目の再試行以降は、読み取りの成功を優先します。そのため、選択されたフォロワーノードにアクセスできなくなった場合、またはその他のエラーが発生した場合、TiDBはリーダーノードにサービスを切り替えます。
leader
- 場所に関係なく、読み取りには常にリーダー レプリカを選択します。
closest-replicas
- TiDB と同じ AZ 内のレプリカがリーダー ノードである場合、TiDB はそこからFollower Read を実行しません。
- TiDB と同じ AZ にあるレプリカがフォロワー ノードの場合、TiDB はそこからFollower Read を実行します。
closest-adaptive
- 推定結果が十分に大きくない場合、 TiDB は
leaderポリシーを使用し、 Follower Read を実行しません。 - 推定結果が十分に大きい場合、TiDB は
closest-replicasポリシーを使用します。
Follower Readパフォーマンスのオーバーヘッド
強力なデータ一貫性を確保するため、 Follower Read は読み取るデータ量に関わらずReadIndex演算を実行します。これにより、TiKV CPU リソースが必然的に追加消費されます。そのため、ポイントクエリなどの小規模クエリのシナリオでは、 Follower Readのパフォーマンス低下が比較的顕著になります。さらに、小規模クエリにおけるローカル読み取りによるトラフィック削減は限定的であるため、大規模なクエリやバッチ読み取りシナリオではFollower Read の使用がより推奨されます。
tidb_replica_read closest-adaptiveに設定すると、TiDB は小さなクエリに対してFollower Read を実行しません。その結果、様々なワークロードにおいて、TiKV の CPU オーバーヘッドの増加は、通常、 leaderポリシーと比較して 10% 未満になります。